链载Ai
标题: Google: “老于,你是第三名!” [打印本页]
作者: 链载Ai 时间: 5 天前
标题: Google: “老于,你是第三名!”
八月中旬,Google面向全球发布了黑客松《BigQuery AI - Building the Future of Data》,旨在通过BigQuery + GenAI的方式打破传统数据分析框架、解锁新的业务场景。本次黑客松共分为三条赛道:Generative AI、Vector Search以及Multimodal,共吸引了全球5300余名选手参与。我的作品《Causal RAG》,在Google十二名评委的严格审核下,从全球众多参赛作品中杀出,并最终在“Vector Search”赛道获得了全球第三名;而我则有幸成为了全球十一名获奖者之一(图1)。获奖固然可喜,而比获奖更令人兴奋的是我的思路 -“Causal AI + LLMs推理范式”在一个更权威的平台上获得了认可。虽然我为比赛准备了一篇两千余字的英文论文,但对于读者而言,“访谈”可能是个更友好的思路诠释方式。所以下文将以模拟访谈的方式展开。1. 为何选择以RAG为主题?
答:RAG是个业界在技术上虽持续投入但仍然做不好的东西。虽然近期的技术演进(例如 Graph RAG、Multi-Agent RAG等)让RAG在定性任务上有了些许进步,但RAG本质上还是挣扎于定量问题。
例如,在财报场景中,当下的技术也许可以应对诸如:“2025财年,Salesforce的营收是多少?”之类的浅层What问题,但对 - “Salesforce 2021年最大的异常是?”这类深度What问题,以及 - “Salesforce FY25营收增长的驱动因素是什么?”这类Why问题就束手无策了。然而,绝大多数具有商业价值的场景都会要求定性、定量的答案。
所以,升级RAG以提供定性、定量的答案是个很好的方向。
2.Causal RAG的核心思路是什么?
答:统计学的成功在于构建事物的概化模型(Approximation)- 利用小规模、结构化的数据揭示出庞大、且非结构化现实中的真相,Bayesian如此,Li Feifei的World Models亦是如此。
同样,当分析财报时,分析师并不会把报告从头到尾、一字不差地过一遍,而是以利润表、资产负债表和现金流量表为核心构建一个财报的概化模型。该模型以财报百分之一的规模,覆盖了财报60%~70%的内容,且能够提供财报内并未直接出现的财务指标(例如,盈利能力、资本结构与杠杆风险等)。
之前的各类RAG方案似乎忘记了其统计学本质,企图构建一个规模庞大但笨重的“完整Copy”(例如,Graph RAG)。但更理想的思路也许是由轻量级的概化模型先应对那70%的深层What和Why问题,再由比较简单的RAG解决余下的浅层What问题。
基于以上理念,Causal RAG的核心思路就是(图2):
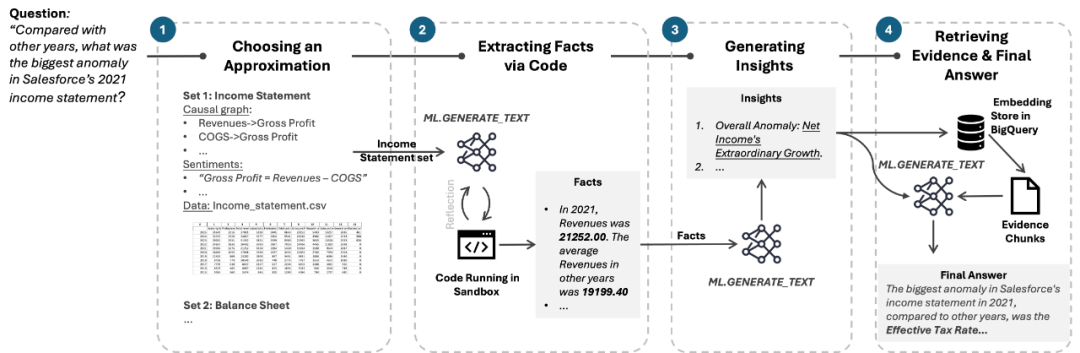
图2:Causal AI的核心思路
以Causal AI实现定性、定量的概化模型(1);
以LLMs产生Code搜索事实、并完成分析(2、3);
利用Vector Search对分析结果予以佐证(4)。
3. 为什么选择Causal AI构建概化模型?
答:还有什么其他更好的选择吗(笑)?我们需要概化模型支持因果关系、能够实现自主推理和对Hypothesis的自我验证;但传统的ML和DL表达的是相关性、基于大模型Deep Research并不支持对Hypothesis的验证、知识图谱只有定性没有定量、而我们在严谨的商业领域几乎不需要RL Trial-and-Error式的搜索。基于以上原因,Causal AI几乎是唯一的选择。
4. 那么以LLMs产生Code的原因是?
答:经典的Causal AI主要聚焦于发现系统变量间的因果结构,并据此执行干预(Intervention)与反事实(Counterfactual)推理。在存在Unobservables变量时,其通常依赖数据科学家的假设与人工建模来保证因果效应的可识别性。
而绝大多数商业场景(例如,财务与运营)的因果结构往往较为稳定,甚至由恒定式构成;问题的核心不在于“发现新因果”,而在于在复杂系统中定位根因与优化路径。因此,这类问题更接近一种搜索过程,更适合通过大模型生成Code在概念模型中进行检索与自主推理。
基于此,Causal RAG的范式可以描述为:
图3:Causal RAG范式
其中,大模型在概念上是由Transformer实现,基于Token Level的贝叶斯网络(P(Xt|X<t))。该贝叶斯网络在叠加由Causal Graph、Sentiments和相关Data构成的概念模型(Approximation)之后产生Code,并由代码逻辑在概念模型的范围内进行推理和检索。
5. Causal RAG的实现效果如何?
答:我们设计了一套财报问题以对比Causal RAG,Baseline RAG,以及SOTA模型的表现(Gemini-2.5-Pro)。该体系包括四类问题:1)浅层事实类问题(Basic Fact);2)浅层计算类问题(Calculation);3)Why类问题(Drivers);4)深层时间序列类问题(Trends)。
测试结果表明,Causal RAG在各个类别问题的表现都明显优于Baseline RAG。而另外一个有趣的发现是,虽然Gemini Pro 2.5有1M大小的Context Window,但其却难以应对基于多个PDF的时间序列查询(例如,鉴别Salesforce在某年的财报异常需要比对连续多年的基线数据);但Causal RAG则在此类问题上表现非常稳定。
图3:测评结果,Causal RAG的基座模型是Gemini Flash 2.5
6. 这个方案中Vector Search的成分岂不是很薄?
答:Embedding Search/Similarity Search本就是非常孱弱的检索体系。Causal RAG只是将其“归位” - 用于提供对推理结果的佐证。当然,当前方案的Vector Search还较为粗放,更细粒度的方案应该是根据Facts/Insights的情况逐条进行佐证。
7.所以Causal RAG会取代传统RAG吗?
答:不会,Causal RAG应该是Baseline RAG在定性、定量问题上的增强。
8. Causal RAG未来的计划是?
答:首先是形成完整的概化模型构建体系。当前的财报模型主要是基于恒定式,未来需要拓展到统计学关系。其次是商业场景的拓展,尤其是在公司战略和运营体系中发挥作用。在上述两方面,我也期待与产业界的朋友们交流合作
| 欢迎光临 链载Ai (http://www.lianzai.com/) |
Powered by Discuz! X3.5 |