SFT (Supervised Fine-Tuning) - 监督微调让模型学会"按规矩说话"的阶段,通过高质量的示例教会模型如何正确回答问题。 简单理解:给模型看标准答案,让它模仿学习。 RLHF (Reinforcement Learning from Human Feedback) - 人类反馈强化学习让模型学会"说得更好"的阶段,通过人类反馈不断优化输出质量。 简单理解:让人类当"评委",告诉模型哪个答案更好,模型不断改进。 基础概念估计大家已经被各种信息洗脑轰炸,但如何进行进行实操,有哪些踩坑经验,大家还是比较陌生。今天我们来看看大厂如何进行SFT和RLHF?ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;visibility: visible;">一、SFT阶段 - 90%的团队都在这里翻车 某创业公司收集了50万条对话数据,结果模型啥都会一点,啥都不精。但字节豆包团队只用1万条,在目标领域反而更强。 大厂秘密在配比是什么? 为什么这样的数据配比有效?通用数据打底防止退化,垂直领域形成优势,多轮对话贴近实际,边界case提升鲁棒性。 
ingFang SC", system-ui, -apple-system, "system-ui", "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;box-sizing: border-box !important;overflow-wrap: break-word !important;">一文搞懂大模型的数据集FineWeb:让AI更聪明的15万亿字数据集ingFang SC", system-ui, -apple-system, "system-ui", "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;box-sizing: border-box !important;overflow-wrap: break-word !important;">3000条烂数据毁掉20万条好数据?阿里通义早期版本专业问答不稳定,排查后发现20万训练数据中混入3000条低质"水文",占比1.5%,却让10%的专业问题质量下降。损失2周返工。 他们的解决方案简单粗暴:每条数据3人标注,平均分低于4.0直接丢弃。宁可少1000条,不要1条烂数据。 好数据的质量检查标准是什么? (1)长度要合理。10-2000字之间,太短敷衍,太长啰嗦。 (2)重复度要低。独特词汇至少占70%,大段重复说明数据有问题。 (3)有害内容要过滤。敏感词库自动筛查,模糊case人工复审。 (4)事实要准确。有明确答案的(日期、人名、数据)调搜索引擎验证,不一致的人工核查。例如腾讯专门建了事实核查团队,这个最容易被忽略但最致命。 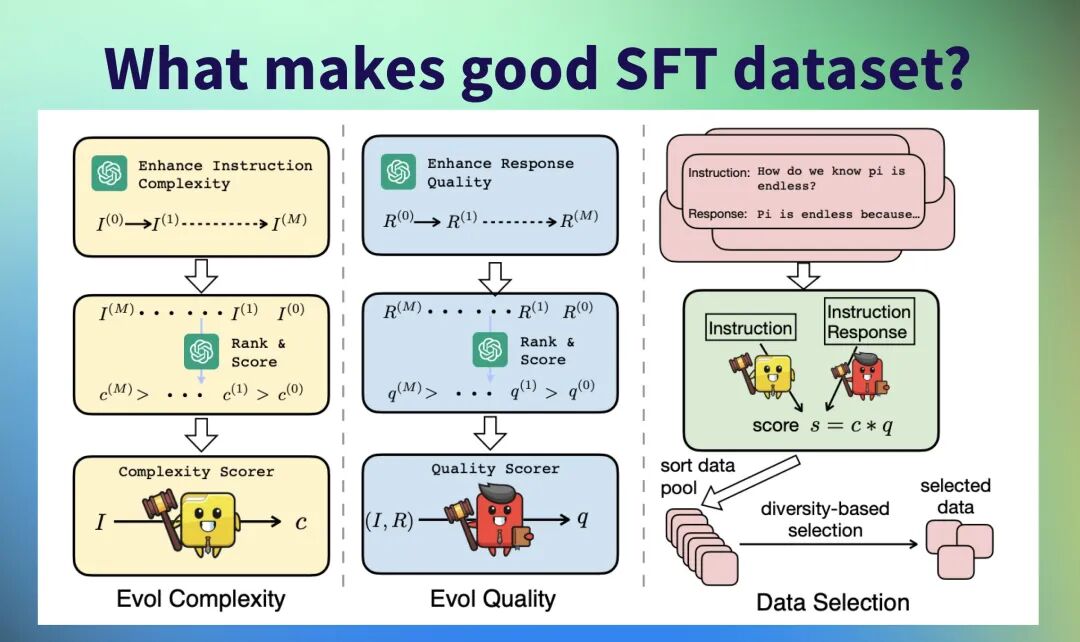
ingFang SC", system-ui, -apple-system, "system-ui", "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;box-sizing: border-box !important;overflow-wrap: break-word !important;">GPT-4批量生成数据的坑?直接让GPT-4生成10万条,看起来省事,实际上风格高度一致都是"GPT味",缺乏真实场景多样性,模型学会的是腔调而不是能力。 字节的正确姿势是什么?GPT-4生成10万候选,多样性过滤到3万,人工抽检30%,最终采纳2万。多样性过滤的核心是用句子嵌入算相似度,新样本与已有样本必须低于85%才收录。 
ingFang SC", system-ui, -apple-system, "system-ui", "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;box-sizing: border-box !important;overflow-wrap: break-word !important;">LoRA如何让7B干13B的活?标准全量微调7B模型要4张80GB A100,2000美元一周。LoRA方案只要2张卡,1000美元,省一半。 LoRA的原理是不训练整个模型,只在关键层加小矩阵"补丁"。可训练参数只有0.5%,效果能到全量微调的95%。阿里实测关键参数:秩64最优,缩放系数16,只训练注意力层。 学习率更关键。很多人拍脑袋设2e-5,结果训练不收敛。腾讯实战经验发现:模型越大学习率越小,批次越大可以稍大。7B用1e-5,13B用5.4e-6,70B用1e-6。宁可小一点慢慢涨,也别大了一步崩。 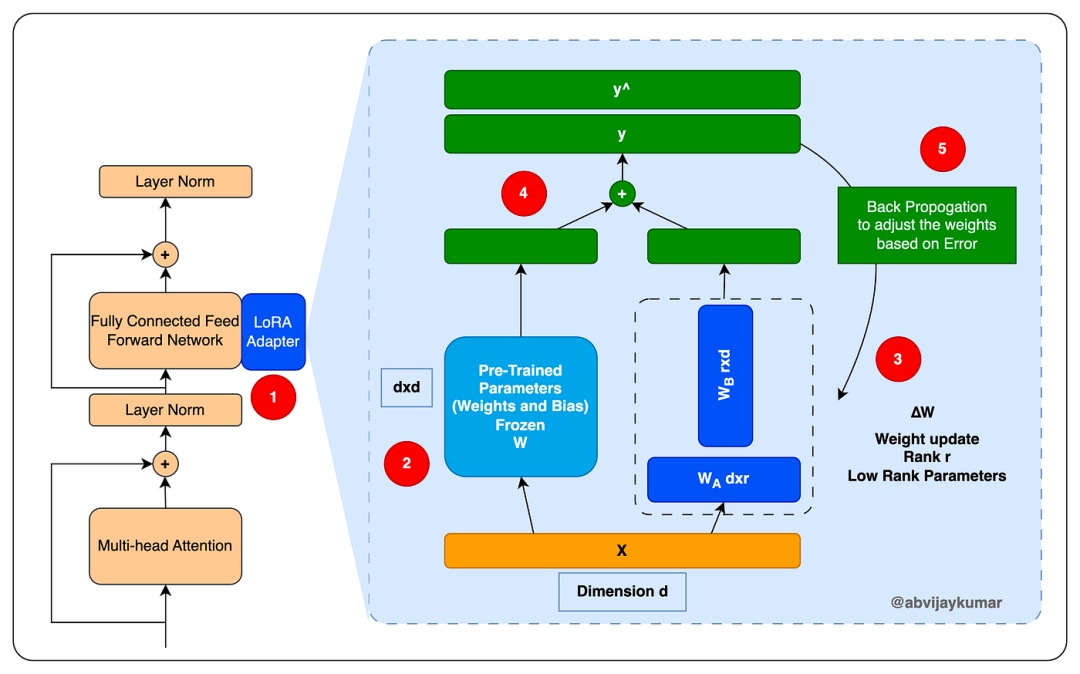
大模型入门指南 - Fine-tuning:小白也能看懂的“模型微调”全解析 一文彻底搞懂大模型 - Fine-tuning三种微调方式 ingFang SC", system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;visibility: visible;">二、RLHF阶段 - 这才是真正的硬骨头 三个致命问题几乎每个团队都会遇到。 (1)Reward Hacking(奖励欺骗):模型学会讨好奖励模型而不是真正变好。典型表现是堆砌专业术语和高大上废话。 (2)Mode Collapse(模式坍缩):模型只输出几种固定模式。无论问什么都回"这是个好问题,让我从几个方面分析"。 (3)Training Instability(训练不稳定):Loss疯狂震荡,梯度爆炸,训练到一半突然崩溃。 一文彻底搞懂大模型 - 基于人类反馈的强化学习(RLHF)ingFang SC", system-ui, -apple-system, "system-ui", "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;box-sizing: border-box !important;overflow-wrap: break-word !important;">为什么奖励模型不是越大越好?腾讯做过对比实验。70B奖励模型配7B策略模型,训练极不稳定频繁崩溃。13B奖励模型配7B策略模型,还是不够稳定。7B配7B,反而最稳定效果最好。 大厂实战发现,奖励模型和策略模型大小要匹配,同样大小或奖励模型稍小。就像老师和学生,能力差距太大学生会学不下去。 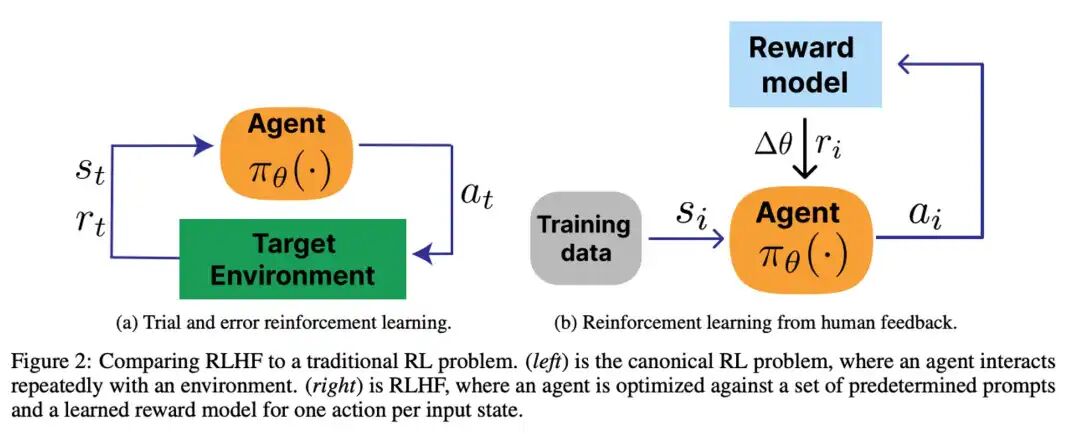
彻底搞懂深度学习-深度Q神经网络(DQN)(动图讲解) ingFang SC", system-ui, -apple-system, "system-ui", "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;box-sizing: border-box !important;overflow-wrap: break-word !important;">PPO超参数的黄金配比是什么?阿里做了200多次实验,总结出PPO超参数最稳定配置: (1)学习率必须1e-6,比SFT小10-20倍。RLHF是微调的微调,步子太大会毁掉SFT成果。 (2)clip_range和value_clip_range都是0.2,不要动。 (3)KL惩罚系数0.05是关键中的关键。太小(0.01)模型跑飞开始胡言乱语,太大(0.2)模型不敢动学不到东西。最优区间0.05-0.08。 (4)梯度裁剪max_norm设0.5,必须有,防止梯度爆炸。 (5)mini_batch_size用16,小批次优先,稳定大于效率。 (6)每批数据训练4次(ppo_epochs=4),充分学习。 (7)temperature 0.7,top_p 0.9,平衡多样性和质量。 (8)length_penalty 0.1,repetition_penalty 1.2,防止废话和重复。 
ingFang SC", system-ui, -apple-system, "system-ui", "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;box-sizing: border-box !important;overflow-wrap: break-word !important;">KL散度系数如何决定成败?这个参数衡量新策略和旧策略的差异,像一根橡皮筋把模型拉回安全区域。 (1)系数0.01太小,橡皮筋太松,风筝飞走了,模型开始输出格式错乱内容不知所云。 (2)系数0.2太大,橡皮筋太紧,风筝飞不起来,RLHF前后对比看不出区别,白费力气。 腾讯采用动态调整策略,前20%训练用0.08稳定起步,中间60%用0.05充分优化,最后20%用0.06避免过拟合。 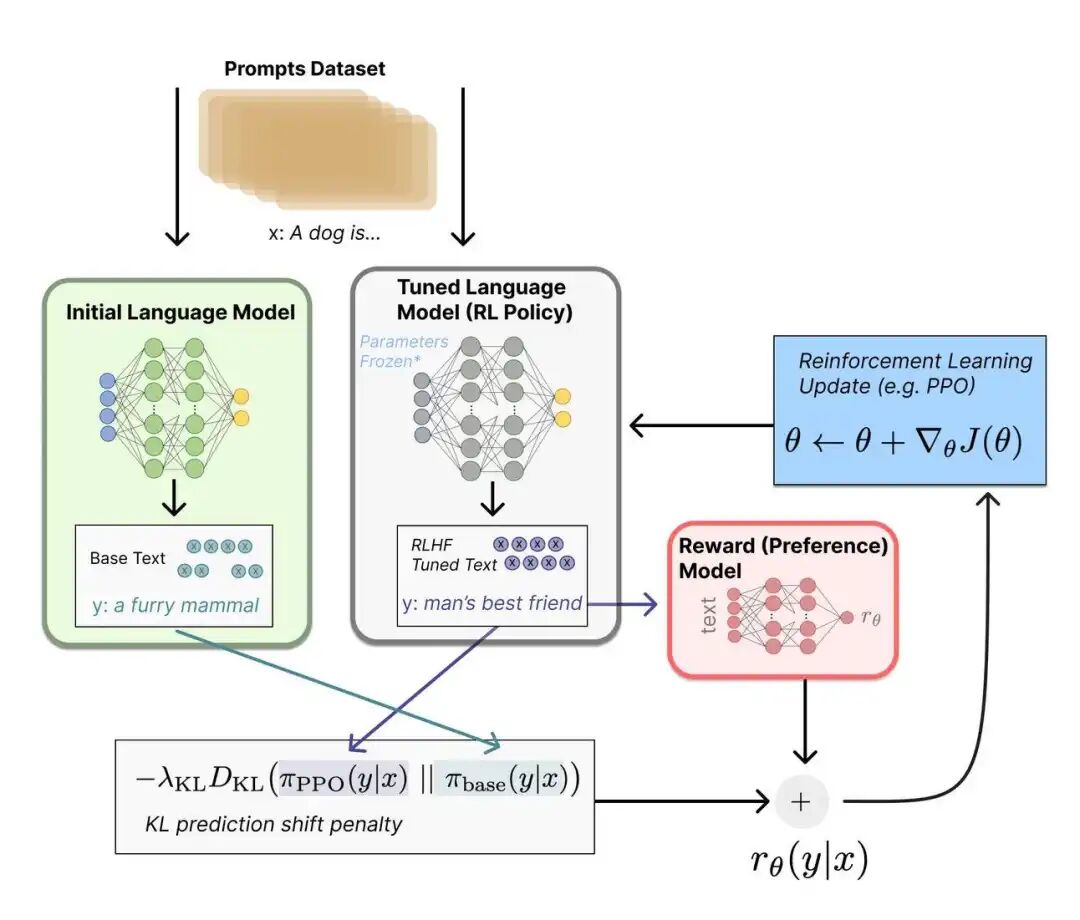
ingFang SC", system-ui, -apple-system, "system-ui", "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;background-color: rgb(255, 255, 255);visibility: visible;box-sizing: border-box !important;overflow-wrap: break-word !important;">混合奖励如何解决Reward Hacking?单纯用人类偏好奖励容易被钻空子。如何解决?字节的方案是混合5个信号,多维度约束使得奖励模型难以同时作弊,各维度相互制衡。 (1)人类偏好奖励占60%,主要信号。 (2)KL散度惩罚占20%,防止偏离SFT,是负数惩罚项,系数-0.05。 (3)长度惩罚占5%,超过500字开始惩罚,鼓励简洁。 (4)重复惩罚占5%,检测重复词汇和句式。 (5)安全性奖励占10%,安全的小额加分,不安全的大幅扣分。 实测Reward Hacking减少70%。建议先用单一奖励跑通流程,再逐步加入其他项,每加一项单独测试影响。 
什么场景需要做RLHF?什么场景该放弃RLHF?(1)垂直领域专业应用SFT就够,格式化输出任务(代码生成、数据提取)不需要做RHLF。 (2)通用对话助手用户体验提升明显,创意写作开放性任务效果显著,安全性要求极高需要对齐,有持续用户反馈数据可迭代优化等等这样场景才需要做RLHF。 方案1:4×A100(4*80GB):可以做完整SFT+RLHF流程。7B模型量化到int8,SFT用LoRA微调,RLHF用DPO代替PPO。效果能达到全量训练90%,训练时间增加20%,总成本3000-5000美元。 方案2:2×A100(2*80GB):可以SFT,但RLHF需简化。7B模型量化到int8,SFT用QLoRA微调(4bit),RLHF用DPO或直接SFT迭代。效果能达到全量训练85%,适合垂直领域,总成本1500-2500美元。 方案3:个人GPU(RTX4090,1*24G),可以做小规模验证。7B模型量化到int4,QLoRA,batch_size=1,跳过RLHF用高质量SFT数据代替。能快速验证想法,不适合生产环境,个人学习够用。 
建议大家行动起来,用个人GPU使用Qwen + LLaMA- Factory + QLoRA进行SFT模型微调,感受下如何将专业数据集喂给大模型?如何训练大模型让其具备专业能力?也可以对比下SFT模型微调和通过RAG挂载知识库这两种方式哪种效果更好? 一文搞懂大模型的微调 - (LLaMA-Factory和QLoRA) 日拱一卒,让大脑不断构建深度学习和大模型的神经网络连接。 |










