1 背景:传统 KGC 的三座大山随着大模型(LLM)能力的不断增强,知识图谱(KG) 作为结构化知识的核心载体,重新成为研究热点。尤其是在GraphRAG、Pike-RAG等图谱增强生成框架的推动下,知识图谱在提升大模型推理能力、缓解幻觉问题方面展现出巨大潜力。 | |
|---|
| 实体消歧难 | 同一缩写、别名、指代在跨段落时极易混淆,人工规则维护成本爆炸。 | | 模式僵化 | 先定义 schema 再抽取,无法随文档主题动态扩展,领域迁移=重写规则。 | | 跨文档信息遗忘 | 长文本直接塞 LLM,中间段落被“遗忘”,导致关系缺失或张冠李戴。 |
2 结论:95.91 % 准确率,6.2 个点的碾压式提升提出RAKG(Retrieval-Augmented Knowledge Graph Construction)框架,首次将 RAG 的评估机制 引入知识图谱构建过程,实现文档级、自动化的知识图谱构建与评估。 图1 直观展示了 RAG 范式反打到 KGC(知识图谱构建) 后的整体流程,把“检索-生成”思路反过来用在建图阶段。 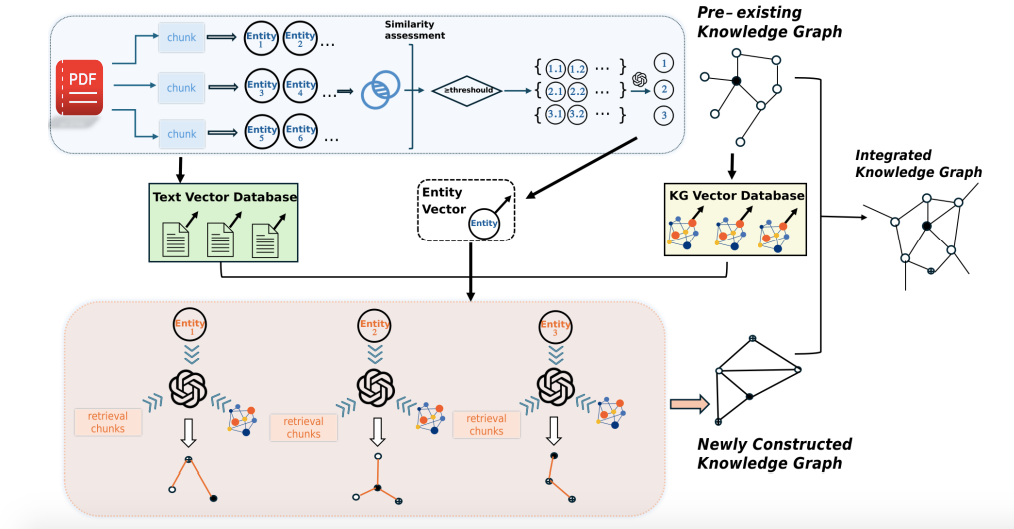 | | | |
|---|
| Accuracy | 95.91 % | | | | 实体密度 ED | 高 23 % | | | | 关系丰富度 RR | 高 31 % | | | | 实体覆盖率 EC | 0.8752 | | | | 关系网络相似度 RNS | 0.7998 | | |
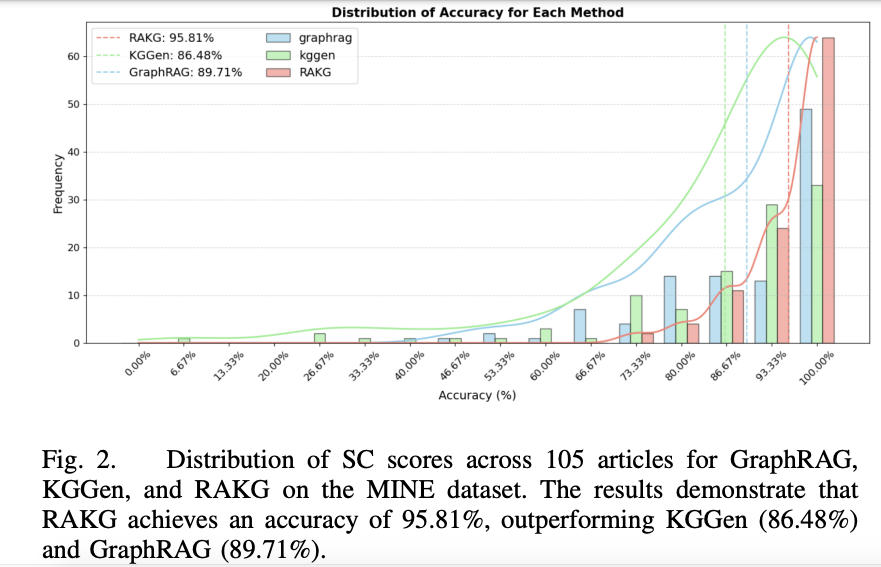
图2 的 105 篇文章得分分布显示,RAKG 几乎“全线右移”,没有低分尾巴。
 3 方案:把 RAG“倒过来”建图的三板斧3.1 预实体(Pre-Entity):先抓“锚点”再检索- 按句分块,NER 逐块抽取实体 → 生成Pre-Entity并缓存 chunk-id;
- 向量相似度初筛 + LLM 二次判别,完成实体消歧与合并;
- 用 Pre-Entity 当“query”,反向去召回它出现过的所有文本块与已有子图。
图6 案例:Butterfly 一生四个阶段,Pre-Entity 把“Butterfly Egg / Larva / Pupa / Adult”先锚定,再各自召回描述段落。 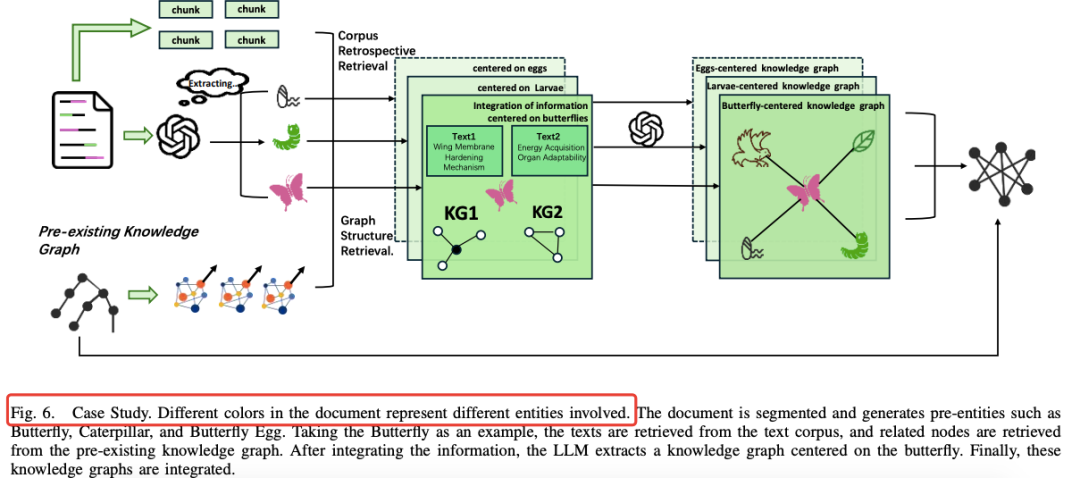 3.2 双层检索:语料回溯 + 图结构回溯 | | |
|---|
| Corpus Retrospective | | | | Graph Structure | | |
图4 把“LLM as Judge”流程画成一条质检流水线:生成→检索→比对→打分→过滤。 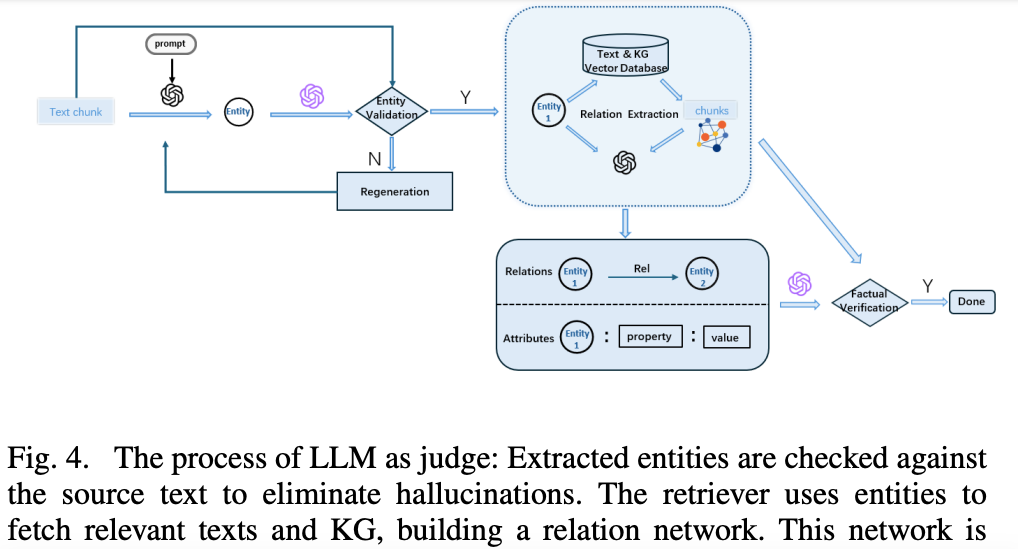 3.3 渐进式融合:子图 → 全局图- 子图之间按实体 ID 合并,冲突边交给 LLM 做“事实性”二次判断;
- 输出最终 KG,并同步更新向量索引,支持持续增量构建。
图5 显示,经过“LLM Judge”后,实体通过率 91.33 %,关系通过率 94.51 %,幻觉率被压到 5 % 以内。 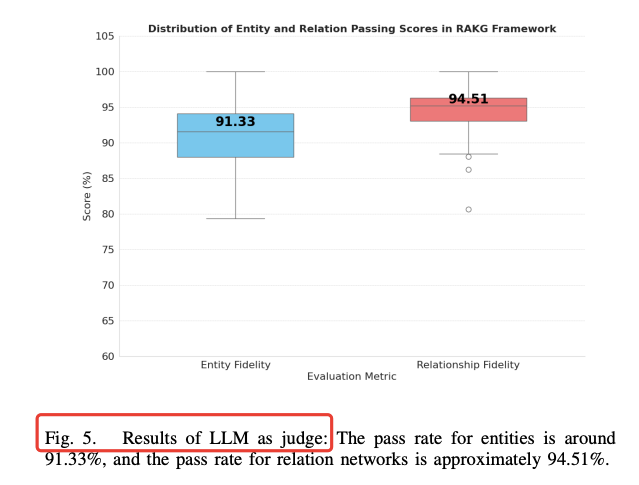 4 一张表看懂 RAKG 的“增量”在哪 | | |
|---|
| | | | 用 Pre-Entity 当 query 分段检索 | | | | | | | |
| 









