|
ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 15px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: inherit;color: rgb(15, 76, 129);">TL;DRingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 15px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">本文主要从使用的角度,通过两个实例(建筑预缴凭证以及带公式的文章)使用
ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 15px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">21年左右,由于工作关系,OCR是我非常关注的一个领域。原来在工作中,曾经将发票、送货单、预缴凭证、手写凭证等扫描到系统中,方便进行系统管理。ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 15px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">当时测试了阿里、百度、腾讯的各种OCR工具,各有千秋,但是又都不能尽如人意。识别率最好的是增值税发票,因为增值税发票的格式最清楚,而且增值税发票差不多都是机打,票面很整齐。不过,其它的一些非标单据识别率就非常差。虽然为业务人员提供了一些方便,但是并没有起到让人眼前一亮的效果。 Deepseek OCR 和 Baidu PaddleOCR-VL最近几天又被DeepSeek刷屏了,这次是因为它发布了一款新的模型 DeepSeek OCR,在行业内又引起了极大的关注。  这款模型只有3B参数,各路试用视频效果吹爆。当然,还有它的创新性的利用上下文光学压缩(Contexts Optical Compression)技术。 而在关注DeepSeek OCR的同时,又发现在在16号百度也发而了Paddle OCR的最新版本V3.3.0,而这个版本的核心组件为PaddleOCR-VL-0.9B,这是一种紧凑而强大的视觉语言模型(VLM),它由 NaViT 风格的动态分辨率视觉编码器与ERNIE-4.5-0.3B语言模型组成。  这个模型的参数更小,只有0.9B,而由于Paddle从2020年开始就专注于OCR相关的领域,现在与大模型结合起来,直到的效果会更加炸裂! 下面是OmniDocBench v1.5的评测结果:  在它发布的时候(10月16日),DeepSeek OCR还没有发布,所以在榜单上还没有DeepSeek OCR的身影。 在上表中,有我现在用得比较多的MinerU,我原来觉得MinerU是最好的PDF以及图片的识别工具,而PaddleOCR-VL在评测中的表现甚至比MinerU还要好!! 由于各路技术分析的文章和视频已经非常多,我就从我原来的工作中找两个场景将这三者做一个初步的对比,看看他们实情的表面怎样。 MinerU vs Deepseek-OCR vs PaddleOCR-VL简单测试测试环境准备由于Paddle只有0.9B,于是在自己的电脑上(Macbook Pro M3)试了一下,简单的OCR识别是可以运行的速度也还算可以,但是如果要生成结构化的markdown格式的文件的化,就会报segmentation fault。看起来,虽然参数小,但是要顺畅使用,对资源的要求还是比较高的。 为了让测试顺利进行,三个软件的运行环境如下: - 1.MinerU:本地安装的MinerU APP,平时做较大文件的识别没有太大问题。但是如果自己部署的话,恐怕也需要必要的资源。(现在MinerU的官网有免费的额度,大家需要的话可以到官网去看看)
- 2.PaddleOCR: 使用HuggingFace上的Demo(https://huggingface.co/spaces/PaddlePaddle/PP-OCRv5_Online_Demo)
- 3.DeepSeekOCR: 使用HuggingFace上的Demo(https://huggingface.co/spaces/khang119966/DeepSeek-OCR-DEMO)
使用Hugging Face上的Demo,好处是免费,而且是运行在GPU环境上,但是也正因如此,有时会需要排队处理。 建筑预缴凭证建筑预缴凭证是在建筑行业广泛使用到的一种税务凭证,一般在当地税局打印或复印,然后业务人员扫描或拍照提交给总部,总部进行处理。 这些凭证有时的效果会非常差,我们原来在系统中添加这块时,识别的成功率达不到要求,如下面这张凭证:  这张凭证有如下的一些问题: - 3. 在中间
税款所属时期的栏目,下面的内容是分行的。原来因为这个原因导致过很多识别失败。
MinerU的识别效果 所有主要信息识别都是非常准确的。 但是也有一些问题: - 2. 下面的一些信息没有识别出来。(不过这个可能与MinerU对头尾的处理相关)
MinerU的优点是,可以导出多种格式:  Deepseek OCR的识别效果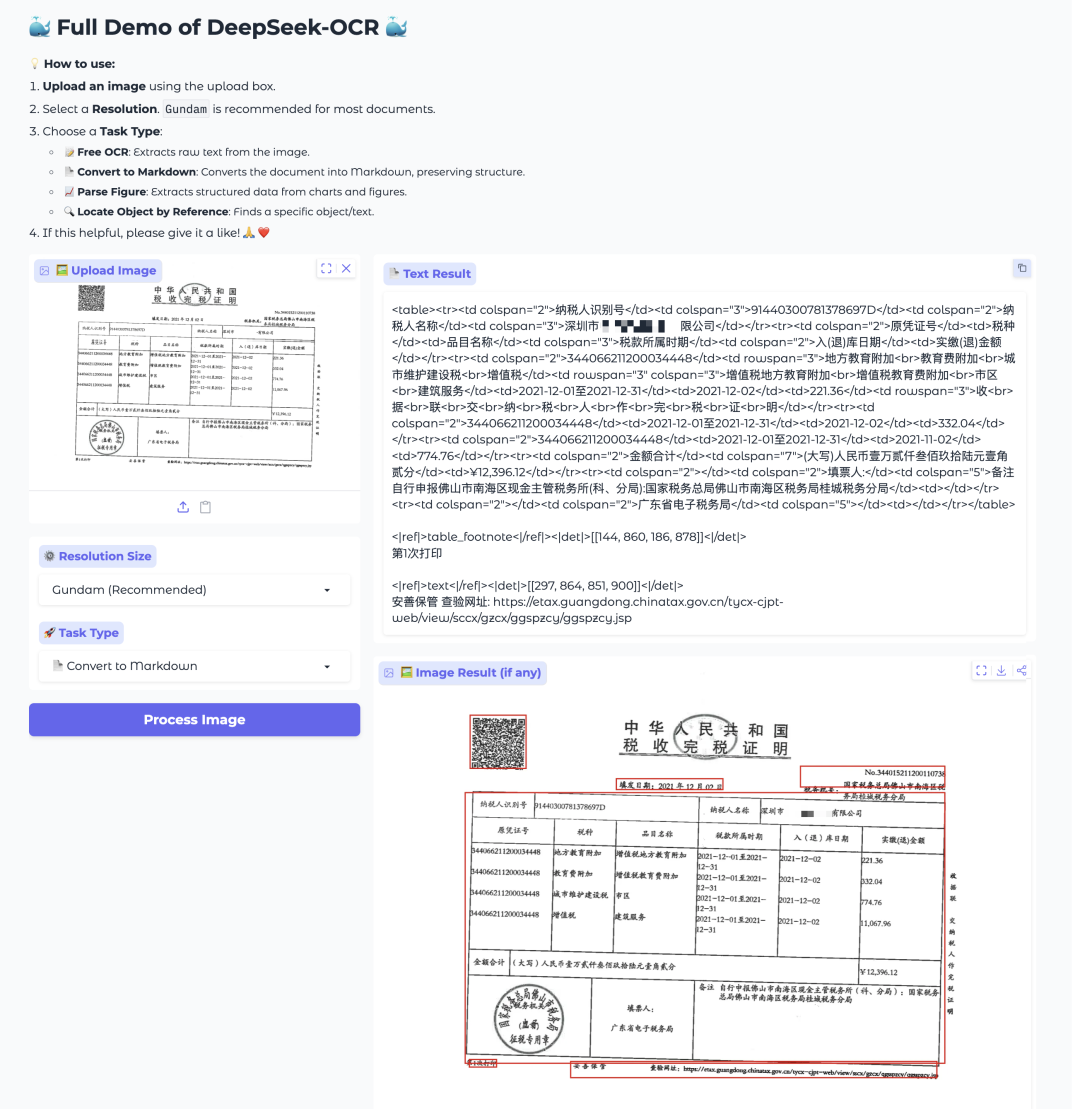
可以看到下面对图片上的信息进行了分块处理,但是由于Demo中没有markdown格式的预览,把它的内容拷贝出来,在vscode中通过预览展示出来如下: (可能也是Demo的问题)上面的图片没有单独整理出来。不过,有一个最大的问题,是凭证中的项目总共有四项,只识别出三项。 这个还是要找机会本地部署后再深入测试才行,使用这个Demo只能看到一些简单的效果。 Baidu PaddleOCR-VL的识别效果从对识别分区的显示上看,也很清晰。
而在HuggingFace这个Demo中有预览的功能,效果非常好。  不仅所有项目(4个)都识别的非常准确,而且凭证号等也都识别得很准确,还有连左上角凭证的二维码也以图片的方式识别出来。 不仅所有项目(4个)都识别的非常准确,而且凭证号等也都识别得很准确,还有连左上角凭证的二维码也以图片的方式识别出来。如下的源文件,可以看到,它确实识别并另存为一张图片:  这对技术人员就非常友好了!所有的信息识别得非常完整!! 带数学公式的图文这张图片是PaddleOCR源代码包中的一张测试图片,  它是包含文字加公式的教科书,其中的微积分公式非常复杂。 MinerU的识别效果 图片和数学公式都没有问题,标红的那些复杂公司识别的也很准确,效果还不错! Deepseek OCR的识别效果 在HF的demo中,由于Markdown的预览做得不好,在Text Result那里只显示了markdown原文,但是在下面的图形分割显示中可以看到模块的切分是非常准确。 将markdown原文在vscode中预览后,看到的情况如下:  对数学公式的解析是没有问题的。 Baidu PaddleOCR-VL的识别效果再看看PaddleOCR-VL的情况,它对模块的识别也非常准确:  再看看markdown预览的情况,  大段大段的文字和复杂的数学公式的识别非常准确。 小小的总结MinerU是我自己使用最多的识别工具,因为它可以本地安装使用,非常方便。在转换时,它应当是访问了后台的服务进行处理的,所以速度非常快。(这样是在白嫖MinerU服务器的算力吗?),它生成的结构也可以直接拿来使用,如下:  - • full.md:转换后的markdown全部内容
- • layout.json:页面布局文件,就是上面那些标红的模块信息,在MinerU中显示控制使用
Deepseek OCR虽然它名字叫OCR,但是它的意义其实是超越OCR这块场景的,毕竟它创新的上下文光学压缩(Contexts Optical Compression),可能会带来对大模型Token管理方式的变革,从而大大减少Token的数量以及历史的保存方式。 现在这个版本是第一版,很快应当会有一些更新,并会带来更多的跟随者。 具体的技术分析可以看这篇:全新开源的DeepSeek-OCR,可能是最近最惊喜的模型。 Baidu PaddleOCR-VL从这次体验的感觉看,这可能是百度系最靠谱的一个产品! 它经过多年积累并结合现在的模型发展,在OCR领域的识别能力上有了大幅度提升。 从它的结构看,基本上涵盖了OCR使用的绝大部分场景:  而这个VL后面的模型也只有0.9B,这使得部署的成本更低,应用场景非常广泛。 具体的技术分析可以看这篇:只有0.9B的PaddleOCR-VL,却是现在最强的OCR模型。 使用场景的畅想以我自己比较了解的建筑行业为例,在项目部的配置中资料员是非常关键的岗位,这就是因为项目周期长,在过程中会产生大量的文档,包括施工计划、联络单、申请单、结算单、图纸、劳务合同、工人劳动合同、身份证件等等等等。 在日常管理工作中,资料员需要对这些资料分门别类,放在不同的文件夹中,所以每个项目部都需要准备一个大的文件柜存放这些资料。 按建筑法规的规定,项目中的资料按不同的类别需要有不同的保存年限,所以不仅项目期间,在项目完成后这些资料还需要保存一段时间(有些关键资料是以年计)。 看看下面这种情况:
而这些资料有很多是根据模板填写的,现在有些项目部会配有一个扫描仪,可以将纸质的文档扫描为图片,保存在电脑中,结果资料员电脑里的图片文件夹就是现实文件柜的翻版。 不论纸质资料也好,图片资料也好,最大的问题还是不好检索。有些资料员细心,在扫描时对文件名有一些的规划,可以按文件夹或文件名查找,但是还是会涉及大量的工作。 而选择合适的OCR工具,则可以更进一步,在扫描成图片时,可以进入解读文件内容并进行总结,保存。  而OCR工具的改进带来得主要好处: - • 识别率的提升,为日常工作带来了极大便利,产品在应用中不是让一线人员去适应,而是真正能帮助他们减少大量重复性工作量
- • 通过OCR工具转换后的,除了电子文件的进一步生成,还可以形成内容的摘要等元数据,方便以后的资料检索
- • 在企业内部进一步完善资料管理规则后,所有的电子文档可以在处理过程中按企业的要求进行命令、整理、保存。原来的纸质文档只能保存在项目部,总部需要检查也大多是走马观花,而旦有效电子化,那么整个管理体系可以更加完善
另外,建筑企业会涉及大量的财税处理,现在有了数电发票,但是还有大量的凭证(如本文中的预缴凭证等)需要处理,如果这些都能通过OCR进行结构化,那么这肯定是行业AI应用的一个有用场景。 |










