01
之前我分享过一篇文章,也是Embedding模型选型,一年过去了,这个领域变化也比较大。
Embedding模型选型思路:决定知识库与RAG的准确率上限!
以前我们选择 Embedding 模型往往只看一个指标:MTEB(Massive Text Embedding Benchmark)综合得分。
但今年随着 RAG系统的普及,工业界对 Embedding 的要求已经从单一的“语义相似度”演变为对 “检索正确性(Correctness)”、“推理延迟(Latency)”以及“多模态/多语言能力”的多维考量。
例如,Cosine Similarity 高不代表检索正确。
在 RAG 中,如果用户问“推荐一款适合肠胃的益生菌”,模型检索到了“益生菌对肠胃不好”的文章(语义高度相关,但事实相反),这肯定有问题。
本文将结合最新的AIMultiple 2025 Benchmark以及MTEB 2025 榜单,深入剖析当前主流的开源 Embedding 模型,为你提供一份面向生产环境的选型指南。
02
在进行选型之前,我们先看下 2025 年 Embedding 模型的底层架构发生了哪些关键变化。
从 BERT 到 LLM-based Embedding:
传统的 Embedding 模型(如BERT,RoBERTa)通常采用Bi-Encoder架构,参数量在 100M-300M 之间。
今年LLM-based Embedding(如NV-Embed-v2,Qwen3-Embedding)成为了“屠榜”的主力。这类模型直接使用 Decoder-only 的 LLM(参数量 7B+)作为基座,通过指令微调(Instruction Tuning)生成向量。
- 优势:拥有极其强大的语义推理能力,能理解复杂的 Instruction(如“为这段法律文本生成一个用于检索判例的摘要向量”)。
- 劣势:推理成本极高,延迟是传统模型的 10-100 倍。
套娃表示学习 (Matryoshka Representation Learning, MRL):
这是 2025 年最实用的技术创新之一(如Nomic-Embed-v1.5,OpenAI text-embedding-3)。
原理:训练时强制模型的前维(如前 64, 128, 256 维)也能包含足够的信息。
数学表达:
损失函数不再仅针对全维度,而是对一组嵌套维度集合求和:
这类模型允许你在向量数据库中仅存储前 256 维以节省 75% 的存储和检索开销,而在重排序(Rerank)阶段使用全维度,实现了成本与精度的完美平衡。
03. 主流开源模型深度解析
基于 AIMultiple 的最新评测(针对 RAG 场景的正确性测试)和 MTEB 数据,我们将模型分为三个梯队。
3.1 效率王者:E5 系列 (e5-small / e5-base-instruct)
令人惊讶的是,在 2025 年的 AIMultiple 评测中,e5-small(118M 参数) 在特定 RAG 场景(Amazon 产品检索)中击败了许多 7B 级别的模型。
- 性能表现:Top-5 正确率:100%(在特定测试集中),63 QPS,是同类竞品的 7 倍。
- 适用场景:高并发的 C 端搜索推荐、实时电商搜索、边缘设备部署。
3.2 全能战神:BGE-M3 (BAAI)
BAAI(智源)发布的bge-m3依然是 2025 年最通用的选择。
- 核心架构:支持Dense(稠密向量)、Sparse(稀疏向量,类似 BM25)、Multi-Vector(ColBERT 模式)三种检索方式。
- 多语言能力:支持 100+ 种语言,是跨国业务的首选。
- 适用场景:如果你的 RAG 系统需要同时处理关键词匹配(如零件型号)和语义匹配(如故障描述),BGE-M3 的混合检索能力是无法替代的。
3.3 精度怪兽:NV-Embed-v2 & Qwen3-Embedding
如果你不仅需要“找到”文档,还需要模型“理解”复杂的指令,这两个模型是目前的 SOTA(State of the Art)。
- 特点:基于 LLM 微调,支持超长上下文(32k+ token)。
- 代价:需要昂贵的 GPU 显存资源,不适合纯 CPU 推理。
- 适用场景:复杂的金融/法律文档分析、Agent 记忆检索、离线数据挖掘。
04. Embedding 选型决策矩阵
| | | |
|---|
| 高并发 RAG / 电商搜索 | e5-small / e5-base-instruct | | |
| 混合语言 / 全球化业务 | BGE-M3 / GTE-Multilingual | | |
| 复杂知识库 / 法律金融 | | | |
| 成本敏感 / 向量库巨大 | | | |
| 边缘端 / 本地部署 | | | |
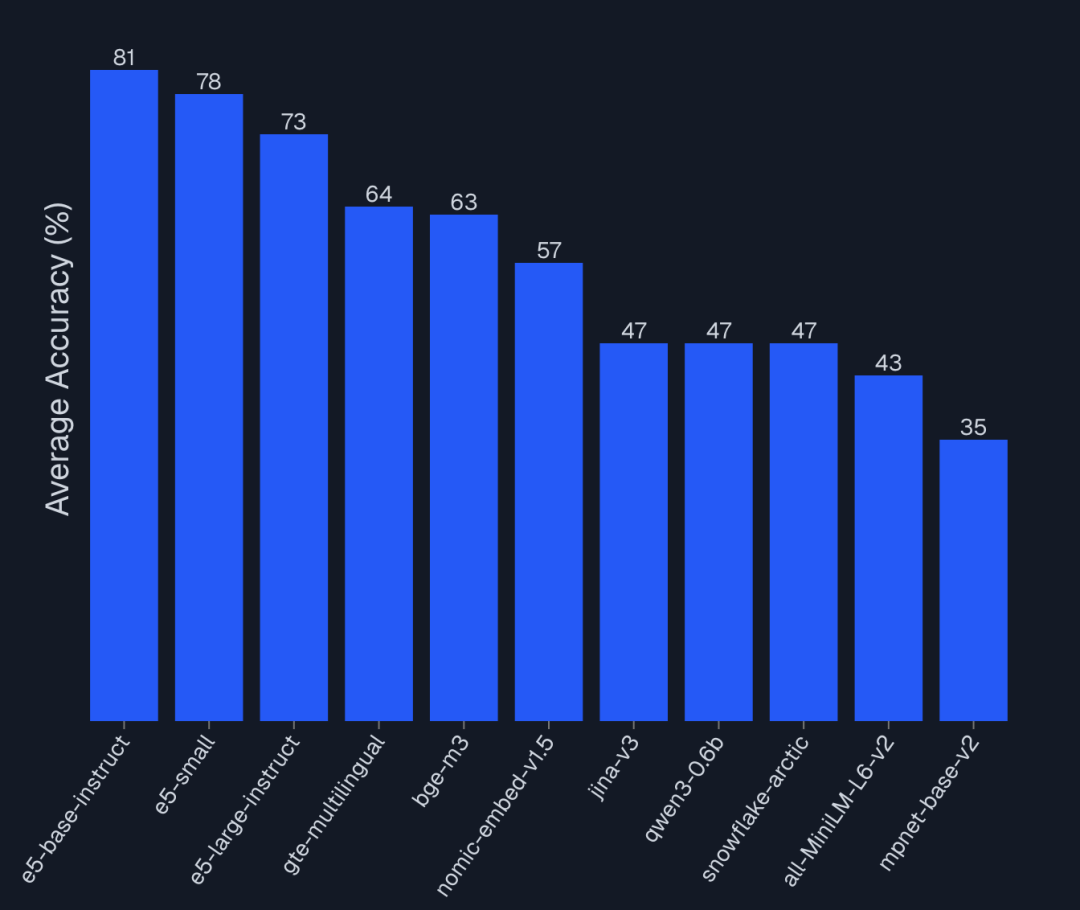
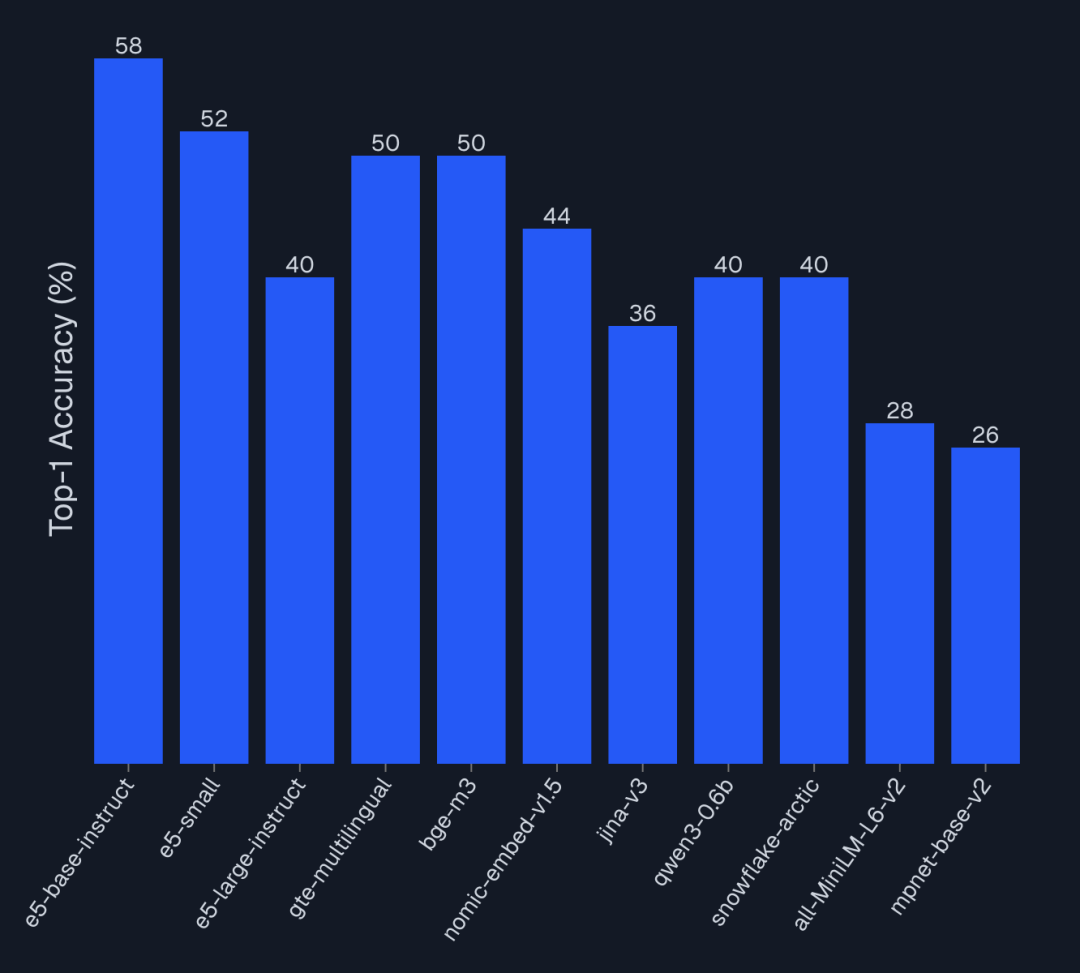


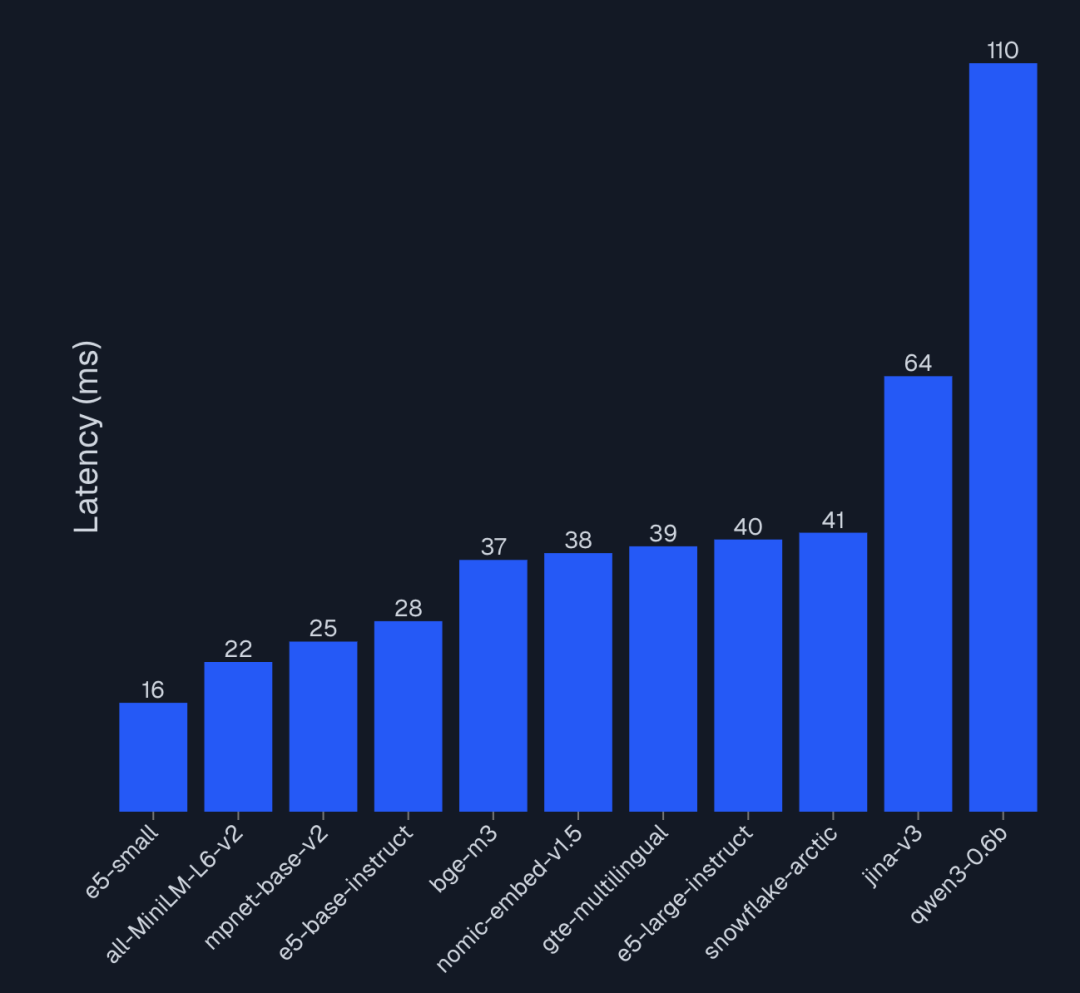
以上都是AIMultiple 2025年的Embedding模型榜单集合,大家具体到自己的业务,参考看看哪个Embedding模型最合适。
我们也可以结合 AIMultiple 的 Benchmark 数据,得出以下比较反直觉的结论:
- 大≠好:
e5-small(118M) 在产品级检索任务中,Top-5 正确率(100%)完胜Qwen3-0.6b(595M, 47%)。在垂直领域,针对性训练的小模型远胜通用大模型。 - 延迟是隐形成本:使用 7B 参数的模型做 Embedding,意味着每次查询可能有 200ms+ 的延迟。在 RAG 链路中,这会直接叠加在 LLM 生成之前,严重影响用户体验。










