|
彻底告别Claude Code失忆。 
之前使用 Claude Code 写了一整天的代码,解决了棘手的 Bug,或者重构了核心模块。 一不小心关闭了终端,再次打开 Claude Code 时,一切都忘了。 不得不重新把项目背景喂给它,Token费用像流水一样。 这就是当前 AI 编程助手最大的痛点:上下文无法持久化。 今天介绍的开源项目 claude-mem 正是为了解决这个问题而生。 它为 Claude Code 装上了一个永久的外部大脑。 claude-mem 是一个为 Claude Code 构建的持久化内存压缩系统。 它通过自动捕获工具使用记录,生成语义摘要,并将这些信息存储在本地。当你开启一个新的会话时,它会自动检索并注入相关的上下文。 因为使用了本地的sqlite,所以记忆是永远保存的。 它的核心价值可以概括为三点: 1.上下文在会话结束后依然存在。
2.分层检索信息,大幅节省 Token。
3.支持自然语言查询项目历史。 渐进式披露是 claude-mem 最精妙的设计哲学,很多类似工具的做法是把所有历史记录一股脑塞进 Context Window。 这不仅贵,而且会因为噪音太多干扰 AI 的判断。 claude-mem 采用了一种模仿人类记忆的 渐进式披露 策略。 第一层:索引 会话开始时,Claude 只会看到有哪些类型的记忆存在,以及读取它们需要消耗多少 Token。 第二层:摘要 如果 Claude 认为这些记忆相关,它会通过 MCP 工具获取详细的叙述性摘要。 第三层:完全回忆 只有在绝对必要时,Claude 才会调取原始的代码变更记录和完整的对话脚本。 这种设计让它在保持全知全能的同时,极大地降低了 Token 消耗。 5.0 版本后,claude-mem 引入了 Chroma 向量数据库,实现了混合搜索架构。 不再需要精准匹配关键词。现在的 Claude 可以理解语义。 你可以直接问它: “我们上次是怎么修复那个内存泄漏问题的”
“这周我们在鉴权模块上做了哪些改动” 它会自动调用 mem-search 技能,在本地的 SQLite 和 Chroma 数据库中检索,把最相关的上下文呈现给你。 官方数据,这比传统的全量上下文加载平均节省 2250 个 Token。 Claude Code,大约 50 次工具调用后,上下文窗口就会报警。因为每次回复都需要重新计算之前的所有输出,计算复杂度是 O(N²)。 无尽模式试图解决这个问题。它将工具的输出实时压缩成约 500 Token 的观察记录,同时将原始数据归档到磁盘。 上下文占用减少 95%!!! 单个会话的工具调用次数上限提升 20 倍。计算复杂度降低为线性的 O(N)。 为了让你看得更清楚它的记忆结构,它还自带了一个运行在 localhost:37777 的 Web 可视化界面。 可以实时查看记忆流,管理配置,甚至在稳定版和 Beta 版之间一键切换。 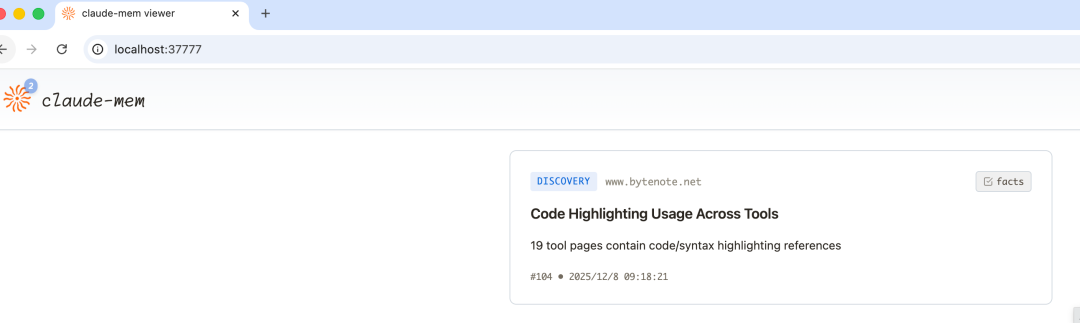
安装非常简单,只要你的 Claude Code 支持插件功能。 在终端中输入以下命令: /pluginmarketplaceaddthedotmack/claude-mem
/plugininstallclaude-mem 安装完毕后,你几乎不需要学习复杂的指令。 
每次启动 Claude Code,它会自动分析当前目录。你会在终端看到它默默加载了相关的项目记忆。无需人工干预,它已经准备好了。 当你想回忆细节时,可以这样问。 上一次修改数据库结构是什么时候
帮我梳理最近的Bug修复记录 它会自动调用搜索工具,从历史记忆中提取答案。 | 









