|
谷歌研究院提出了Titans 架构与MIRAS 理论框架,为大模型带来一种全新的长期记忆能力:模型在运行过程中即可动态更新自己的核心记忆,而无需离线再训练。这一能力直指当前 Transformer 的核心瓶颈——超长上下文的计算成本。 Transformer 依赖注意力机制回看全部历史输入,但计算量会随序列长度平方级增长,因此难以处理动辄百万 Token 的上下文。研究界曾探索线性 RNN、Mamba-2 等 SSM 方向,以固定大小的状态来压缩上下文,但固定容量依然难以覆盖极长语料的丰富信息。 Titans + MIRAS 的突破在于:结合 RNN 的速度 + Transformer 的表达力,用“可实时学习的深度神经记忆”替代传统固定向量记忆。 Titans:边读边学的长程记忆系统文献链接:https://arxiv.org/pdf/2501.00663 一个有效的认知系统需要「短期记忆 × 长期记忆」。注意力机制适合短期精确记忆,而 Titans 引入了一个新的长期记忆结构——一个可被梯度即时更新的深度 MLP 记忆网络。 也就是说,模型不是简单“记录”历史,而是: 其中的关键机制是 “惊讶度指标(surprise metric)” ——当新输入与模型当前记忆偏差很大时,梯度就会变大,模型认为“这很重要”,并将其写入长期记忆。 例如: - 低惊讶:模型已在描述动物,“cat” 并不重要 → 不写入
- 高惊讶:严肃财报里突然出现“banana peel” → 强烈写入
此外 Titans 引入两项增强机制: - Momentum(动量):不仅记录突发的信息,也记录紧随其后的相关信息
- Forgetting(遗忘门/权重衰减):防止长期记忆无限膨胀,保持可控容量
MIRAS:统一所有序列模型的理论框架
文献链接:https://arxiv.org/pdf/2504.13173
MIRAS 提供了一套统一视角:所有序列模型(Transformer / RNN / SSM)本质上都是“关联记忆系统”。 它将模型的设计归纳为四个核心要素: - Memory architecture:记忆结构(向量 / 矩阵 / 深度网络)
- Attentional bias:模型决定“关注什么”的内部目标函数
- Retention gate:遗忘机制(各种正则化的重新解释)
- Memory algorithm:更新记忆的优化方法
MIRAS 的独特之处在于,它跳出了以往模型依赖 MSE 或点积相似度的限制,提出一个更丰富的设计空间,包括非欧几里得目标、鲁棒损失等。 基于 MIRAS,论文还构建了三个不依赖注意力的新模型: - YAAD:使用 Huber loss,降低对异常值的敏感性
- MEMORA:强制记忆表现为概率映射,保证更新平衡有序
实验:在长上下文任务中远超现有模型研究团队将 Titans 与上述 MIRAS 模型在 C4、WikiText、HellaSwag、PIQA 等任务上与 Transformer++、Mamba-2、Gated DeltaNet 对比,结果显示: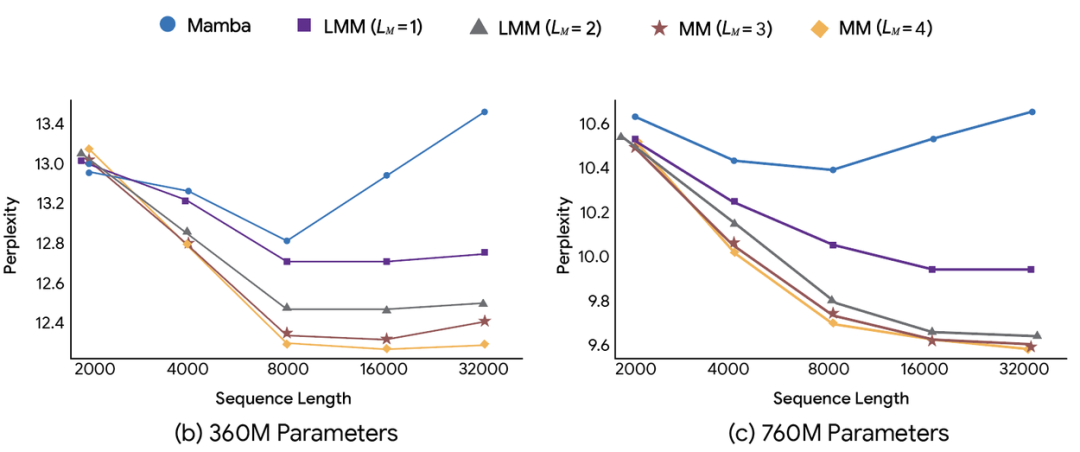 - 在极端长上下文(数百万 Token)仍能保持稳定性能
- 在BABILong基准上,Titans甚至超过 GPT-4,且参数量远小于 GPT-4
研究还发现:记忆网络越深,性能越强,扩展性越好。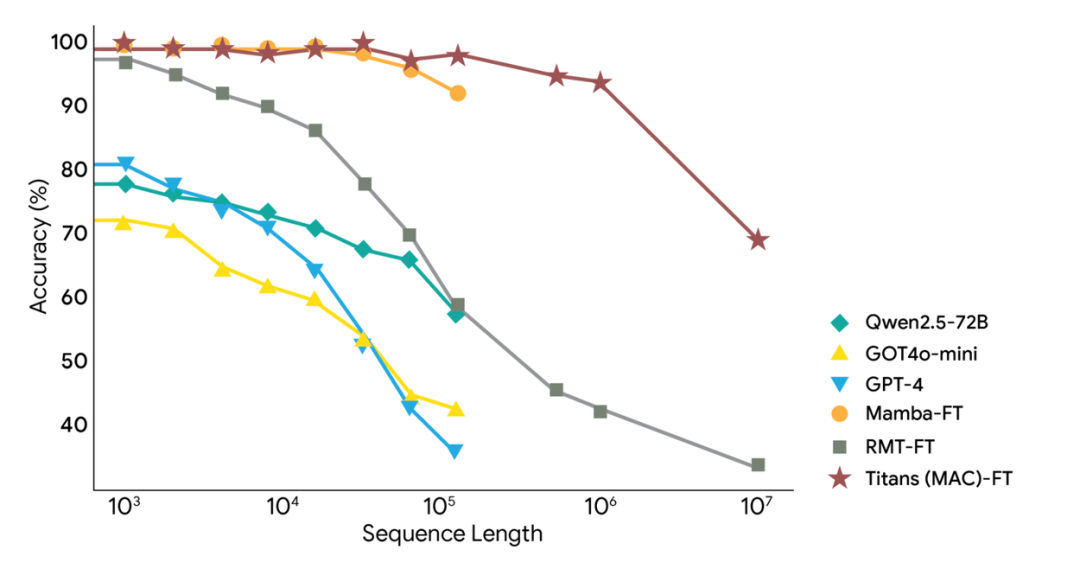 | 









