|
经过上次的概率统计模型方法的介绍后,相信你对于自然语言的生成已经有了初步的了解,今天我们来侃侃Word2Vec,这是一种将单词表示为向量的方法,由 Google 于 2013 年提出。它为自然语言处理提供了一种将单词表示为向量的方式,使得计算机能够更好地理解单词间的语义关系。
一、Word2Vec 的基本概念
定义
两种模型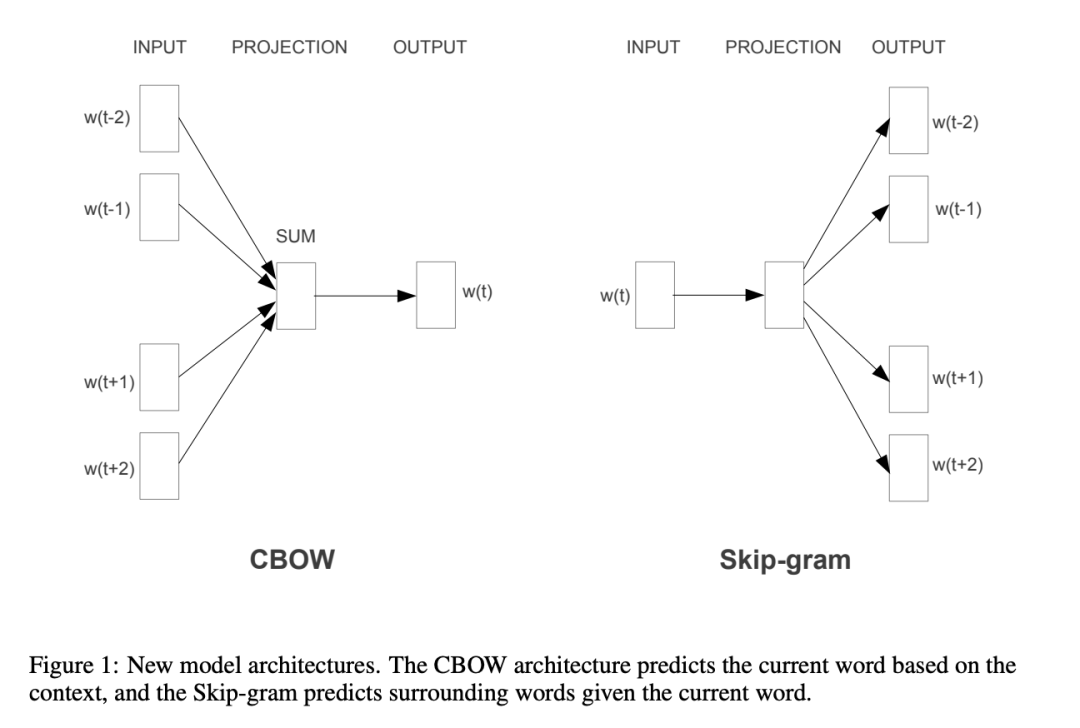
二、Word2Vec 模型的实现
CBOW 模型 输入是上下文单词,输出是目标单词。
目标是最大化目标单词在上下文下的条件概率。使用 Softmax 函数计算概率
损失函数:
利用 Gensim 库,我们可以轻松实现 CBOW 模型并训练自己的词向量。下面是一个简单的例子:
from gensim.models import Word2Vecimport reimport stringimport jieba# 示例文本text = """一个男人和一个女人在打猎,吃树上的果实亚当和夏娃在远远看着他们我在写从零基础到精通大语言模型"""
# 数据预处理def preprocess(text): text = text.lower() text = re.sub(f"[{string.punctuation}]", "", text) return list(jieba.cut(text, cut_all=False)) # 修改这里,将生成器转换为列表
# 预处理数据sentences = [preprocess(sentence) for sentence in text.split("\n") if sentence]print(sentences)# 使用 Gensim 训练 CBOW 模型model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, sg=0) # sg=0 代表使用 CBOW 模型
# 查看词向量print(f"Vector for '男人':\n {model.wv['男人']}")
# 寻找相似的单词similar_words = model.wv.most_similar("男人")print(f"Words most similar to '男人':\n {similar_words}")# 计算机输出 [('模型', 0.25292226672172546), ('和', 0.17017711699008942), ('亚当', 0.15016482770442963), ('女人', 0.13886758685112), ('他们', 0.10851667821407318), ('基础', 0.09937489777803421), ('打猎', 0.034764934331178665), ('写', 0.033063217997550964), ('夏娃', 0.01984061673283577), ('看着', 0.0160182137042284)]
CBOW模型的优缺点及改进方法
优点
缺点 对CBOW模型的改进
Skip-gram 模型:Skip-gram 是 CBOW 的逆模型,通过目标词预测上下文单词。接下来就会说说。 子词建模:使用 FastText 等模型可以捕捉词的子结构信息。 上下文相关的词向量:使用 BERT、GPT 等模型获取上下文相关的词向量。
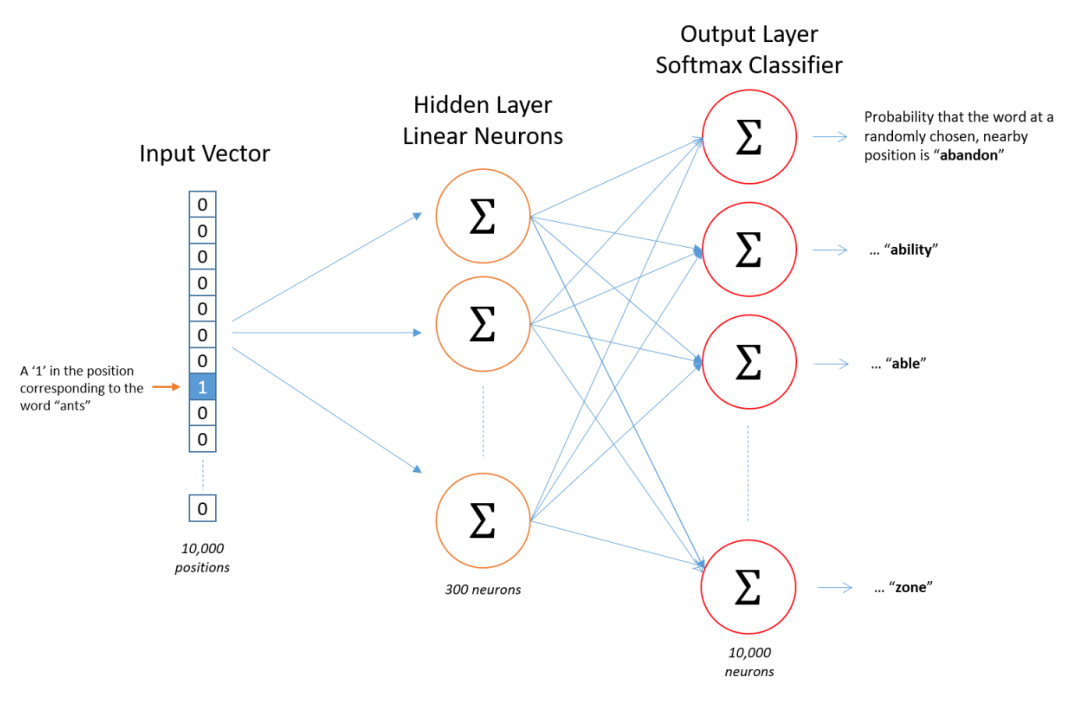 Skip-gram 模型
输入是目标单词,输出是上下文单词。 目标是最大化上下文单词在目标单词下的条件概率。 损失函数:
模型结构
输入层: 目标词的单词索引。 隐藏层: 目标词映射到一个词向量。 输出层: 输出上下文词的概率分布。
Skip-gram 模型的应用场景
相似性计算与推荐
词类比与推理
result = model.wv.most_similar(positive=["king", "woman"], negative=["man"])print(f"Words similar to 'King - Man + Woman':\n {result}")
文本分类与聚类
from sklearn.svm import SVCfrom sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import classification_reportimport numpy as npfrom gensim.models import Word2Vecimport re, string
# 数据预处理def preprocess(text): text = text.lower() text = re.sub(f"[{string.punctuation}]", "", text) return text.split()
# 示例数据data = [ ("Machine learning is great", "tech"), ("The stock market is booming", "finance"), ("Football is very popular", "sports"), ("Deep learning is a branch of machine learning", "tech"), ("Investing in stocks is risky", "finance"), ("Basketball is fun", "sports"),]
# 预处理数据sentences = [preprocess(text) for text, _ in data]labels = [label for _, label in data]
# 训练 Word2Vec 模型model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, sg=1)
# 将文本转化为向量def get_vector_base(sentence): return np.mean([model.wv[word] for word in preprocess(sentence) if word in model.wv], axis=0)
def get_vector(sentence): words = preprocess(sentence) word_vectors = [model.wv[word] for word in words if word in model.wv] if not word_vectors: return np.zeros(model.vector_size) return np.mean(word_vectors, axis=0)
X = np.array([get_vector(text) for text, _ in data])y = np.array(labels)
# 训练分类模型X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)clf = make_pipeline(StandardScaler(), SVC())clf.fit(X_train, y_train)
# 评估模型y_pred = clf.predict(X_test)print(classification_report(y_test, y_pred))
4. 聚类与可视化
from sklearn.decomposition import PCAimport matplotlib.pyplot as plt
# 获取所有词向量words = list(model.wv.index_to_key)word_vectors = model.wv[words]
# PCA 降维pca = PCA(n_components=2)word_vectors_pca = pca.fit_transform(word_vectors)
# 可视化plt.figure(figsize=(10, 8))plt.scatter(word_vectors_pca[:, 0], word_vectors_pca[:, 1], marker='o')for i, word in enumerate(words): plt.text(word_vectors_pca[i, 0], word_vectors_pca[i, 1], word)plt.show()
三、Word2Vec 模型的改进与替代
FastText
GloVe
其他预训练词向量
负采样(Negative Sampling): 为加速训练,将多分类任务简化为二分类任务。对每个正样本,随机采样负样本(非上下文单词)进行二分类训练。层次Softmax(Hierarchical Softmax): 使用Huffman树实现高效的Softmax计算。
|










