ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", Arial, sans-serif;">周ingFang SC", "Hiragino Sans GB", "Microsoft YaHei", Arial, sans-serif;">五好呀米娜桑!今天迎来了双倍快乐,是周末,也是儿童节!愿你永葆童心,永远快乐!
今天我们一起学习讨论一个“老生常谈”但却值得不断去研究的话题,那就是“基于大模型如何生成测试用例,是否能真的提升测试效率”!据京东零售团队研究发现,基于Langchain生成测试用例,结果效率提升了50%!
我们今天就来从研究背景、实现的过程思路、实践效果以及大模型自动生成的优缺点方面来学习讨论,希望对你有所启发!
它是一个开源框架,用于构建基于大型语言模型(LLM)的应用程序。LLM 是基于大量数据预先训练的大型深度学习模型,可以生成对用户查询的响应,例如回答问题或根据基于文本的提示创建图像。
LangChain 提供各种工具和抽象,以提高模型生成的信息的定制性、准确性和相关性。例如,开发人员可以使用 LangChain 组件来构建新的提示链或自定义现有模板。LangChain 还包括一些组件,可让 LLM 无需重新训练即可访问新的数据集。
在研究开源框架LangChain之前,公司最先普及的是JoyCoder,但是在把相关需求及设计文档信息拷贝到JoyCoder,让其生成测试用例时,却发现人工操作步骤较多(如:复制粘贴文档,编写提示词,拷贝结果,保存用例等)、响应时间久,而且当需求或设计文档内容较大时,提示词太长或超出 token 限制!
因此开展了基于LangChain的研究!
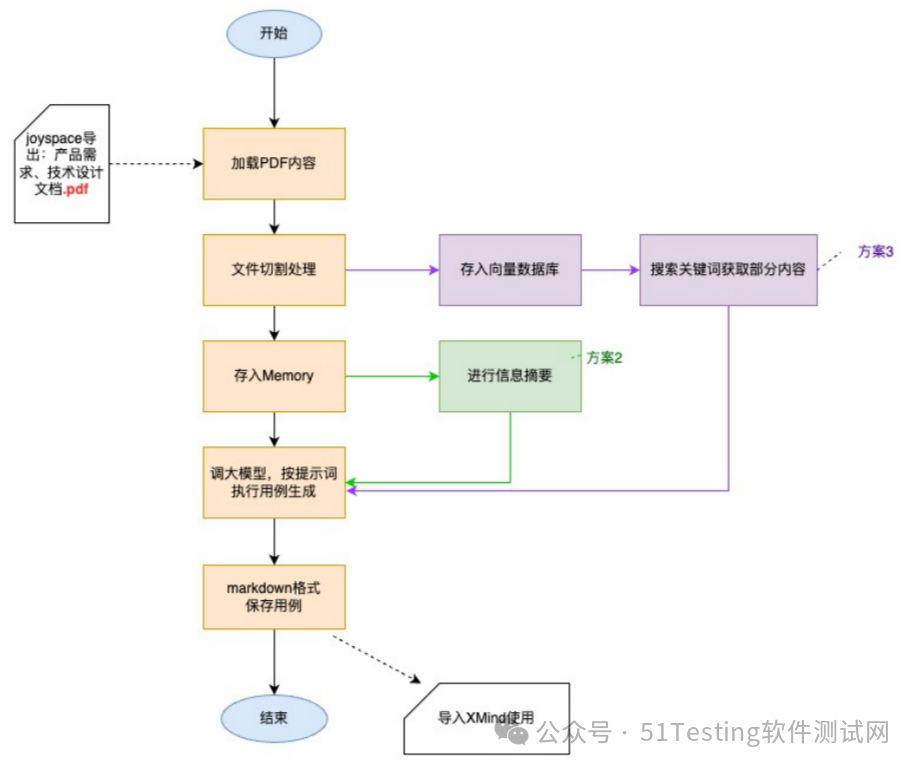
Memory 的使用:这个是大多数大模型都会有的一个功能,就像我们平常在使用的ChatGPT、Kimi等聊天,不需要把每次上面的内容都重复再输入一遍,大模型会自动记忆我们上述的对话内容。
本次我使用Langchain的ConversationBufferMemory与ConversationSummaryBufferMemory来实现,将需求文档和设计文档内容直接存入 Memory,可减少与大模型问答的次数(减少大模型网关调用次数),提高整体用例文件生成的速度。ConversationSummaryBufferMemory 主要是用在提取“摘要”信息的部分,它可以将将需求文档和设计文档内容进行归纳性总结后,再传给大模型。
用例生成后是否真的能帮助我们节省用例设计的时间,是大家重点关注的,因此我随机在一个小型需求中进行了实验,此需求的 PRD 文档总字数 2000+,设计文档总字数 100+(因大部分是流程图),结果效率提升 50%。
本次利用大模型自动生成用例的优缺点:
优势:
全面快速的进行了用例的逻辑点划分,协助测试分析理解需求及设计;
降低编写测试用例的时间,人工只需要进行内容确认和细节调整;
用例内容更加全面丰富,在用例评审时,待补充的点变少了,且可以有效防止漏测;
如测试人员仅负责一部分功能的测试,也可通过向量数据库搜索的形式,聚焦部分功能的生成。
劣势:










