|
昨天的文章中我们提到,可以使用Rerank对RAG系统进行优化。揭开RAG重排序(Rerankers)和两阶段检索(Two-Stage Retrieval)的神秘面纱 今天,我们动手在项目中实现Rerank。
Rerank的目的是通过重新排序检索结果,提升文档与查询的相关性。其优势在于能够进一步提高检索准确性,确保最相关的文档排在前列,从而显著提升系统的整体性能和用户体验,如下图所示。 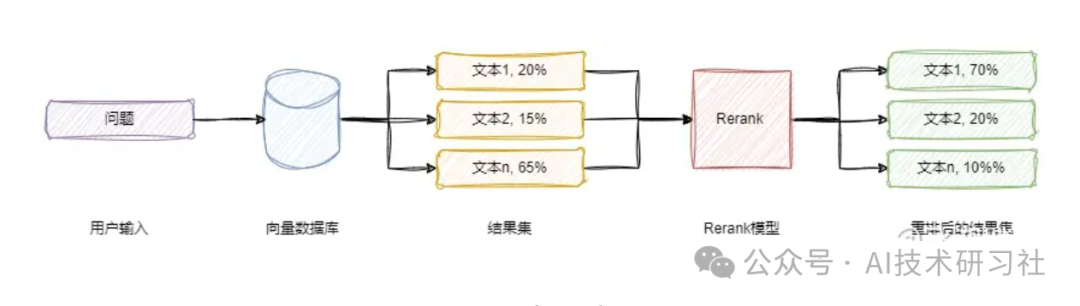
因为在搜索的时候存在随机性,就是我们在RAG中第一次召回的结果往往不太满意的原因。但是这也没办法,如果你的索引有数百万甚至千万的级别,那你只能牺牲一些精确度,换回时间。 这时候我们可以做的就是增加top_k的大小,比如从原来的10个,增加到100个。 然后再使用更精确的算法来做rerank,使用一一计算打分的方式,做好排序。比如100次的遍历相似度计算的时间,我们还是可以接受的。 有朋友问我,Rerank如何集成到项目中呢? 答案就是:Rerank模型的方式集成到项目中。 在HuggingFace上面搜索,发现有很多Rerank模型,如下图。 
新的reranker模型:发布跨编码器模型 BAAI/bge-reranker-base 和 BAAI/bge-reranker-large ,它们比嵌入模型更强大。 我们建议使用/微调它们来重新排名嵌入模型返回的前 k 个文档。 如何使用bge-reranker-large 模型呢?https://huggingface.co/BAAI/bge-reranker-large和bge-reranker-base下载模型。 下面,我们以 BAAI/bge-reranker-large 这个模型为例进行说明,我个人推荐的、最简单的方案是使用 FlagEmbedding 这个库:
第一种方式:FlagEmbedding 库 pipinstall-UFlagEmbedding 获取获取相关性分数(分数越高表明相关性越高): from FlagEmbedding import FlagRerankerreranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])print(scores)
第二种方式:HuggingFace库 import torchfrom transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]with torch.no_grad():inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)scores = model(**inputs, return_dict=True).logits.view(-1, ).float()print(scores)
所以,当在RAG 项目中,使用Embedding 求出topN的时候,N可以大一点儿,然后重新组织问题和检索出来的答案。 比如,question是问题,top_n_answers是Embedding返回的结果,得到Rerank的新数据结构。 new_rerank_pairs=[[question,answer]foranswerintop_n_answers] 目前rerank模型里面,最好的应该是cohere,不过它是收费的。 开源的是智源发布的bge-reranker-base和bge-reranker-large。bge-reranker-large的能力基本上接近cohere,而且在一些方面还更好。 几乎所有的Embeddings都在重排之后显示出更高的命中率和MRR,所以rerank的效果是非常显著的。 embedding模型和rerank模型的组合也会有影响,可能需要开发者在实际过程中去调测最佳组合。 下面是一个使用Huggingface和Faiss进行Rerank的Python代码示例。这个示例将展示如何从一个初始的文档集合中检索文档并通过Rerank优化排序,以提升检索结果的相关性。 在没有使用Rerank之前,只通过Embedding,检索Top3。 fromlangchain.vectorstoresimportFAISSfrom langchain_core.documents import Documentfrom langchain.text_splitter import CharacterTextSplitterfrom langchain.embeddings import HuggingFaceEmbeddings
texts = ['哪个快递公司最好?','我该选哪家快递?','哪个快递最快?','哪家快递服务最可靠?','我应该用哪个快递寄包裹?','哪家快递性价比最高?','发货用哪个快递公司比较好?','哪个快递公司收费最合理?','选择哪个快递更安全?','哪个快递公司的客户服务最好?','发顺丰快递']
documents = []for idx, text in enumerate(texts):metadata = {"idx": idx}doc = Document(page_content=text, metadata=metadata)documents.append(doc)
text_splitter = CharacterTextSplitter(separator="\n", chunk_size=512)texts = text_splitter.split_documents(documents)
local_model_name = 'shibing624_text2vec-base-chinese'embeddings = HuggingFaceEmbeddings(model_name=local_model_name)
db = FAISS.from_documents(texts, embeddings)faiss_index = "vectors_db/hln_tb_faiss_index"db.save_local(faiss_index)
question = "发什么快递?"answers = db.similarity_search(question, k=3)print(answers)
得到的结果是: [Document(page_content='哪个快递最快?',metadata={'idx':2}),Document(page_content='发货用哪个快递公司比较好?',metadata={'idx':6}),Document(page_content='我应该用哪个快递寄包裹?',metadata={'idx':4})]加入Rerank 之后,Top改成Top10。 
from FlagEmbedding import FlagReranker
# 构造一个 FlagReranker 实例,设置 use_fp16 为 true 可以加快计算速度reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True)
new_rerank_pairs = [[question, answer.page_content] for answer in answers]# 计算多对文本间的相关性评分scores = reranker.compute_score(new_rerank_pairs)print(scores)
最后讲一下Rerank的微调。
准备数据: {"query":"Fivewomenwalkalongabeachwearingflip-flops.","pos":["Somewomenwithflip-flopson,arewalkingalongthebeach"],"neg":["The4womenaresittingonthebeach.","Therewasareformin1996.","She'snotgoingtocourttoclearherrecord.","Themanistalkingabouthawaii.","Awomanisstandingoutside.","Thebattlewasover.","Agroupofpeopleplaysvolleyball."]}{"query":"Awomanstandingonahighcliffononeleglookingoverariver.","pos":["Awomanisstandingonacliff."],"neg":["Awomansitsonachair.","GeorgeBushtoldtheRepublicanstherewasnowayhewouldletthemevenconsiderthisfoolishidea,againsthistopadvisorsadvice.","Thefamilywasfallingapart.","nooneshoweduptothemeeting","Aboyissittingoutsideplayinginthesand.","EndedassoonasIreceivedthewire.","Achildisreadinginherbedroom."]}运行微调脚本: torchrun--nproc_per_node{numberofgpus}\-mFlagEmbedding.reranker.run\--output_dir{pathtosavemodel}\--model_name_or_pathBAAI/bge-reranker-base\--train_data./toy_finetune_data.jsonl\--learning_rate6e-5\--fp16\--num_train_epochs5\--per_device_train_batch_size{batchsize;set1fortoydata}\--gradient_accumulation_steps4\--dataloader_drop_lastTrue\--train_group_size16\--max_len512\--weight_decay0.01\--logging_steps10参数: per_device_train_batch_size:训练中的批量大小。 train_group_size:训练中查询的正数和负数。总有一个正数,所以这个参数将控制负数的数量 (#negatives=train_group_size-1)。注意到否定的数量不应大于数据"neg" ist[str]中的否定数量。除了此组中的底片外,批次内的底片也将用于微调。 ist[str]中的否定数量。除了此组中的底片外,批次内的底片也将用于微调。 讲完了Rerank,再来看看大模型最新消息: Llama 3.1 405B 已正式开源! Llama 3.1 405B 在性能上可与 GPT-4 等闭源模型相媲美,在通用知识、可控性、数学、工具使用和多语言翻译上表现出色。 支持 128K 上下文长度, 405B、8B 、70B 三个型号。 同时还发布了 Llama Guard 3 和 Prompt Guard 等安全工具,及 Llama Stack API,以促进第三方项目更容易地使用 Llama 模型。 Llama 3 将会集成图像、视频和语音的功能,能够识别图像和视频并支持通过语音进行交互,此功能目前正在开发中。 Meta 使用了超过 16,000 个 H100 GPU 来训练 Llama 3.1 405B,为了支持大规模生产推理,Meta 对模型进行了量化,使其能够在单个服务器节点上运行。 | 









