|
随着AI技术的快速发展,AI辅助编程已成为提升研发效率的重要手段,也是不可逆转的编码新方式。AI编程工具也从原本根据上下文自动生成补全代码片段发展到以Cursor为首的各种AI编辑IDE及CLI工具,这些工具将编码效率提升至前所未有的高度。在这一背景下,国内外许多公司都在宣传AI工具帮开发者提升多少效率,但问题是如何通过指标准确衡量这些工具带来的研发效率提升呢?同时由于不同的AI编程工具各具特点和功能,也会为指标衡量带来挑战,主要聚焦为两点:无统一的指标量化体系及AI工具多样化带来统计数据挑战,如下图所示: 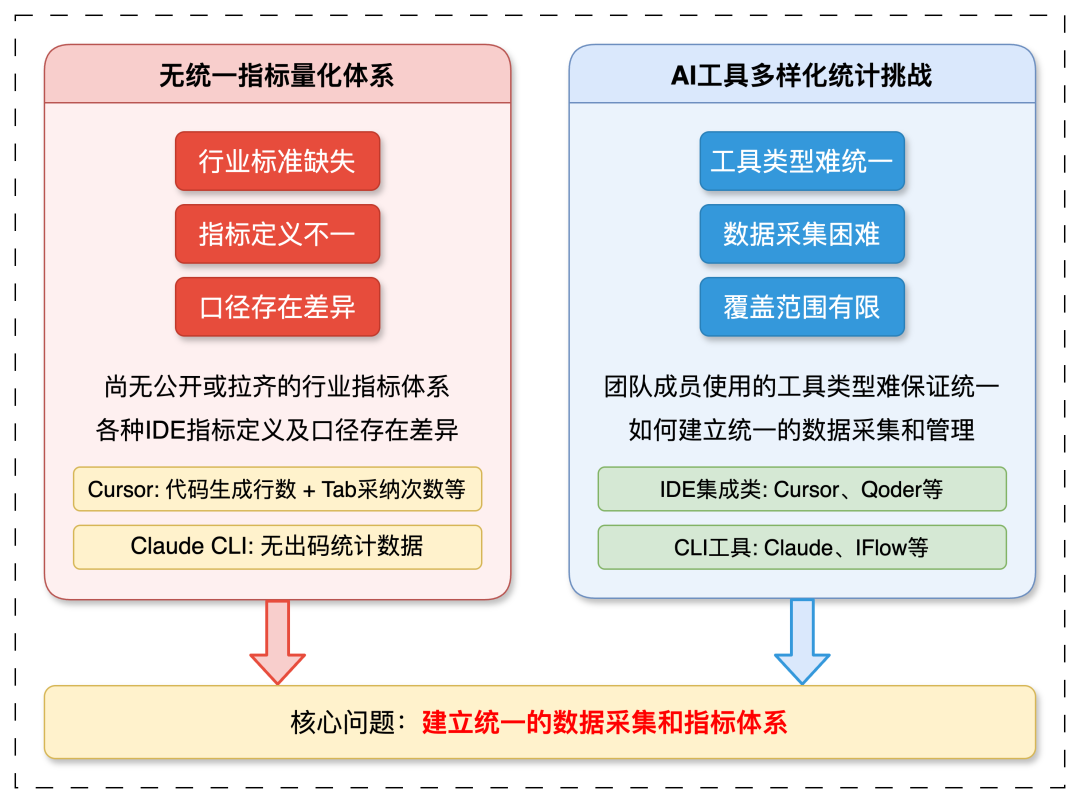
过去几个月,围绕建立统一的数据采集和指标体系这一核心问题,我们从零搭建AI统一数据采集能力,覆盖团队同学使用AI工具,定义了AI出码率等核心指标,逐步构建了AI效率研发指标体系。通过持续迭代优化,实现从指标量化到问题识别、再到工具使用效果优化的数据驱动闭环。 在定义指标过程中,我们主要遵从真实性原则,以最终提交到Code平台代码作为有效代码的衡量标准,因为只有这样,才能保证代码的质量和流程规范。在这个原则基础上,通过分析团队成员的Git提交数据以及采纳AI生成代码的情况,来评估AI编程工具的使用效果和研发效率提升情况。具体指标定义如下: AI出码率主要用于衡量AI工具生成的代码在最终提交代码中的有效占比。主要定义如下: AI采纳行数:统计周期内AI生成中与commit提交逐行的匹配得到的代码行数。 commit的代码总行数:统计周期内用户Git提交记录的代码总行数。 以AI出码率为核心质量指标,围绕其我们建立了一些其他指标进行分析与参考,一些其他指标如下: 代码量统计信息:用于反映用户统计实际产出代码统计相关数据。 会话交互信息:通过会话数、会话采纳率、轮次等评估AI对话效率。 使用时长信息:记录工具实际使用时间,评估工具粘性。 Tab补全相关:用来观测Tab在整个出码率中的占比。
针对整个高德信息工程团队和前端团队进行指标统计,团队成员AI Coding主要以使用的编辑器为Cursor和Qoder为主。以我所在前端团队整个8月指标统计为例,最终效果如下: 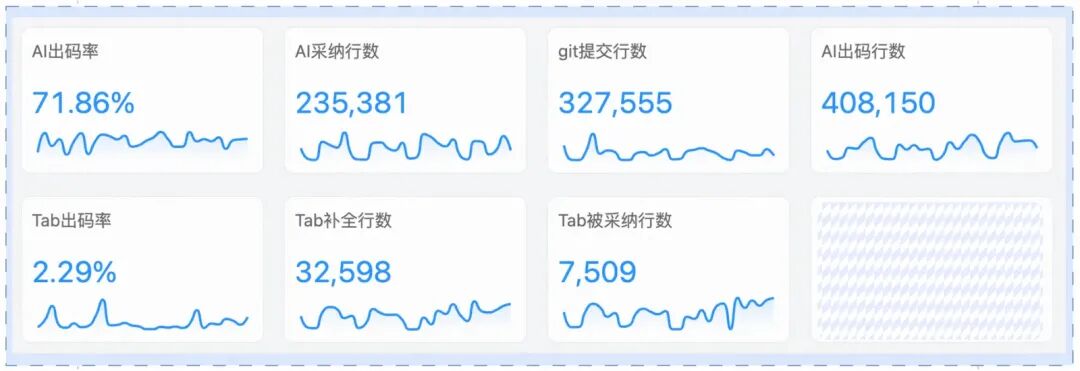
团队的整体出码率从30%上升至70%以上(6月-8月),基于效率体系相关指标计的统计情况,我们进行了相关分析及优化,主要包括: 针对AI不适用场景进行优化:及时发现在开发需求中,AI效果不佳的环节和项目类型,通过rule沉淀、结合MCP工具进行文档查询,提示编码效率及场景优化。 持续调整工具使用策略:通过指标数据反馈,循环改进AI工具使用策略,比较不同AI编程工具和使用方式表现,推荐交互友好、出码效率高的编码方式。 沉淀AI工具使用最佳实践:及时总结高效使用AI工具的方法和经验模式,助力新人快速提升开发效率。比如邀请出码率高的同学进行团队分享、组织相关AI Coding比赛等。
整个指标评价体系建设系统方案及系统如下图,基于分层架构设计实现了从数据采集能力建设、平台能力搭建、指标数据分析的业务闭环。 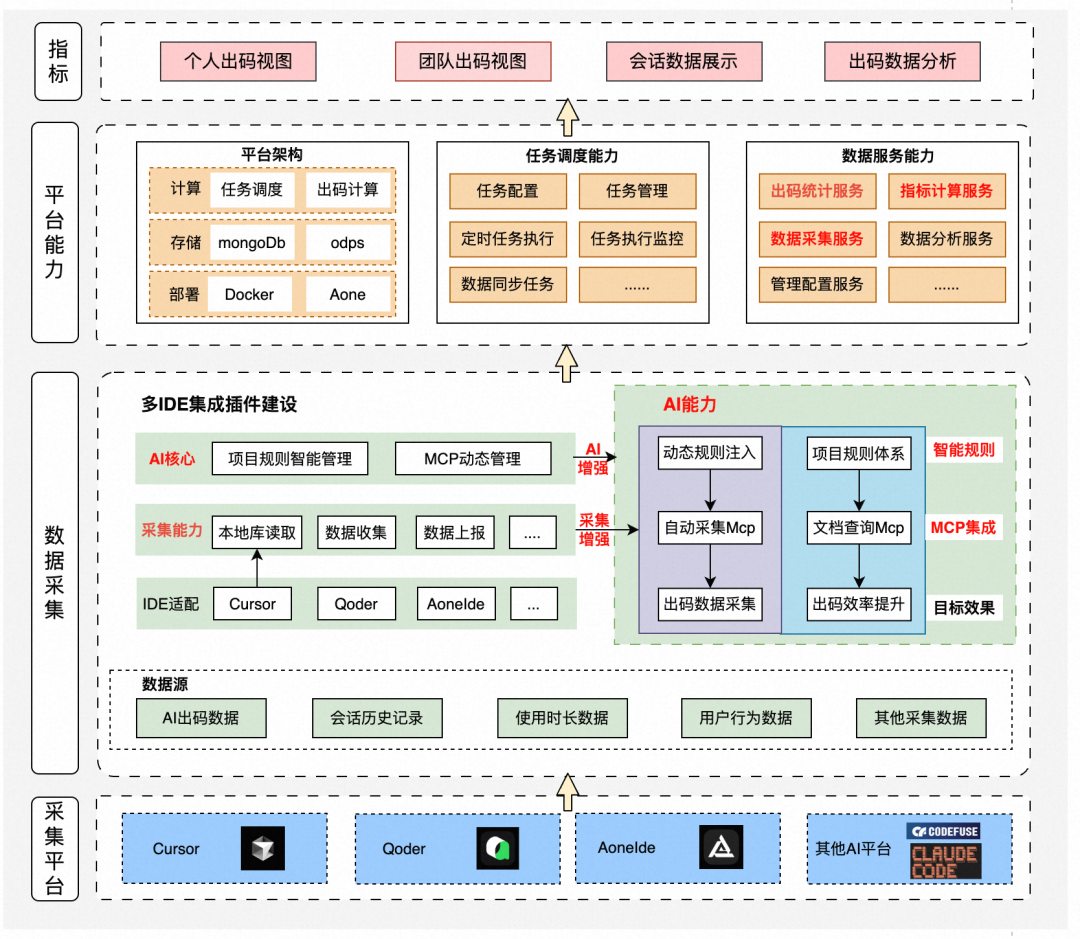
主要模块包括: 在AI研发效率指标建设中,其核心能力是围绕数据的统一采集及指标体系进行搭建,在确定对应的指标体系后,我们对数据采集进相关调研及实践。 该部分主要为了采集AI会话过程中的生成的代码及会话等相关数据,数据的全面性才能让指标更丰富,当前主流的方案主要包括以下三类: 基于AI coding工具的签名方法 主要思路是基于Git提交信息中的标准化AI标识,利用Git的特性,自动在提交说明中添加AI coding签名,实现提交级的统计效果,统计粒度为提交级(commit为粒度)。详细可见[1]
IDE插件采集方案 该方案主要基于Git blame机制实现行级代码归属追踪,通过实时监听IDE编辑事件自动切换Git作者身份,结合Diff算法精确统计AI生成与人工代码相关信息,将统计粒度从"提交级"细化到"编辑级",采用"最后修改者原则",实现统计行级精准追踪。 本地数据库逆向方案 针对Cursor等AI编辑器,可通过逆向工程识别其存在的本地数据库文件,直接获取AI生成代码记录,实现AI生成信息的全部获取,包括AI会话历史记录、AI出码数据等所有结构信息。三种方案各有优缺点,主要对比如下: 
5.2 我们的方案: 从本地数据库逆向方案到MCP协议标准化采集方案 一开始我们主要使用Cursor,主要基于本地数据库逆向方案进行数据采集和分析,初期我们主要基于Cursor提供的vscdb进行数据采集,其优点是准确度高,支持场景多(如能做到Tab信息采集、行内采集、会话信息采集等);但缺点也很明显,比如版本变更可能回导致数据库存储结构变化、导致我们需要更新代码,同时只支持Cursor编辑单一场景。 随着集团生态发展和外部不可控因素,我们的采集思路也经历了从工具集成到智能生态、从"被动统计"到"主动优化的采集转变。 5.2.1 基于MCP协议标准化采集方案该方案的主要思路是基于提示词强制触发+MCP执行,精确的提示词可以触发MCP的强制执行,而MCP能读取文件数据。 为什么要采用这种方案? 兼容所有IDE平台:所有AI编辑器相通的提示词和MCP,可以针对每一次AI对话或指令进行独立统计,兼容性强,可以针对大多IDE和CLI工具。 未来标准化方案:虽然由于模型质量原因或幻觉,可能会出现MCP不执行的原因,但其是一种更标准化、更可控、也更有潜力的未来方向,使得采集能力不再依赖于插件的私有实现,而是成为一种可插拔的能力。经过测试,数据采集也基本符合预期。 工程复杂度极小:实现简单,比本地数据库逆向方案复杂度大大降低。
如何用于出码数据采集? 模型型通过MCP协议,在变更文件前,调用提供的beforeEditFile工具,记录需要变更前的涉及的文件路径。 在编辑文件后,再次调用 对比记录开始和结束时代的文件代码差异,准确计算出本次对话的AI出码数据。
主要流程如下图: 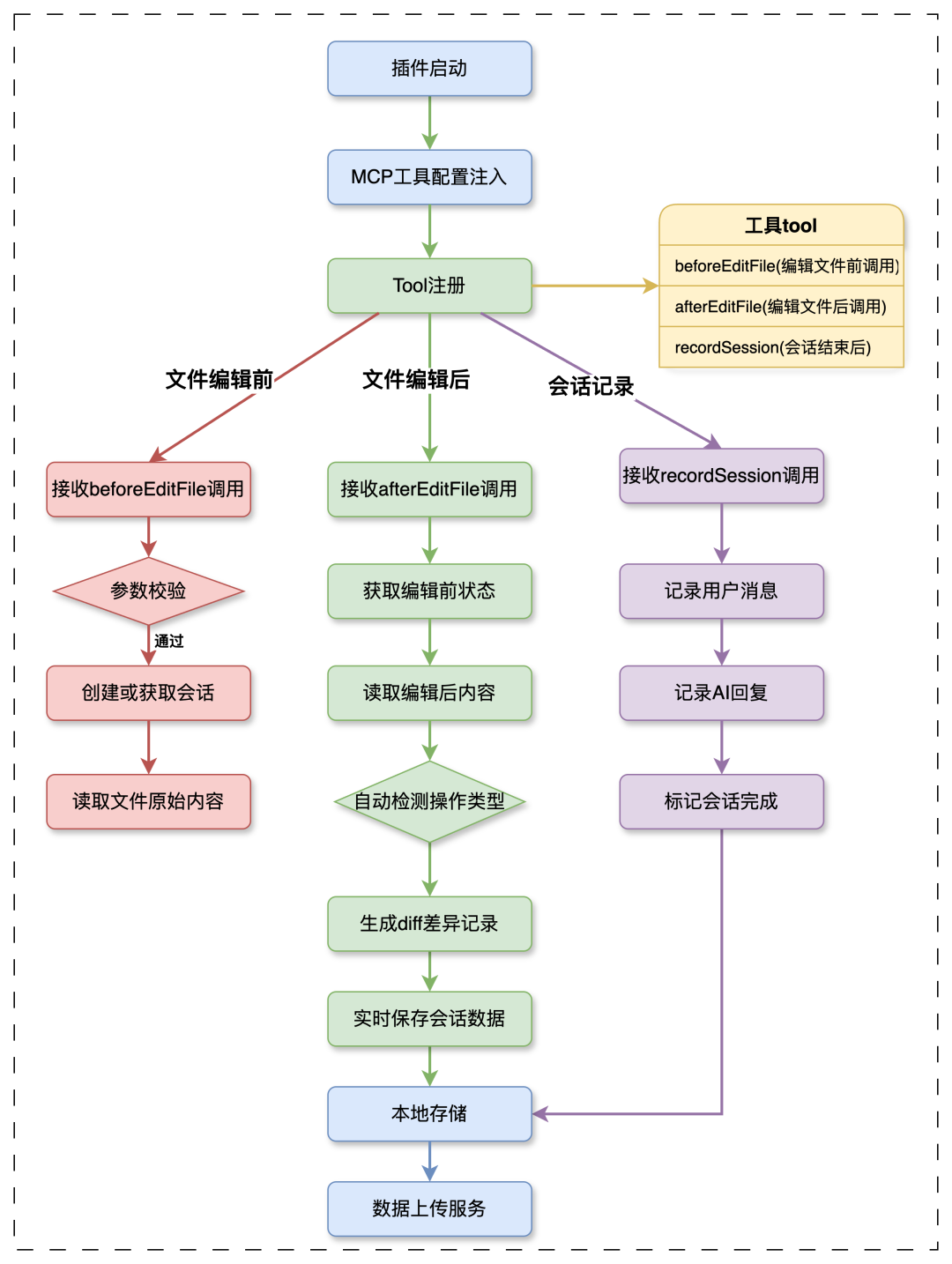
该方案也存在一定的缺点,主要如下: 5.2.2 提示词设计及优化在使用MCP进行自动采集数据功能之前,团队的已有规范体系存在一些问题,这些问题会影响了AI工具生成代码的质量和效率,也会导致MCP收集工具部分失效。现有规则存在以下两个问题: 为了尽可能的减少项目规则和保证规则的强制触发,我们进行了优化。最后整理出两个主要的规则,业务规则和智能采集规则设定,规则根据项目不同通过插件识别自动注入。 (1) 项目业务规则优化 业务规则基于分层分模块的结构化设计采用了知识库外置 + 动态查询的方式进行优化,采取措施如下 规则主要优化设计思路如下: 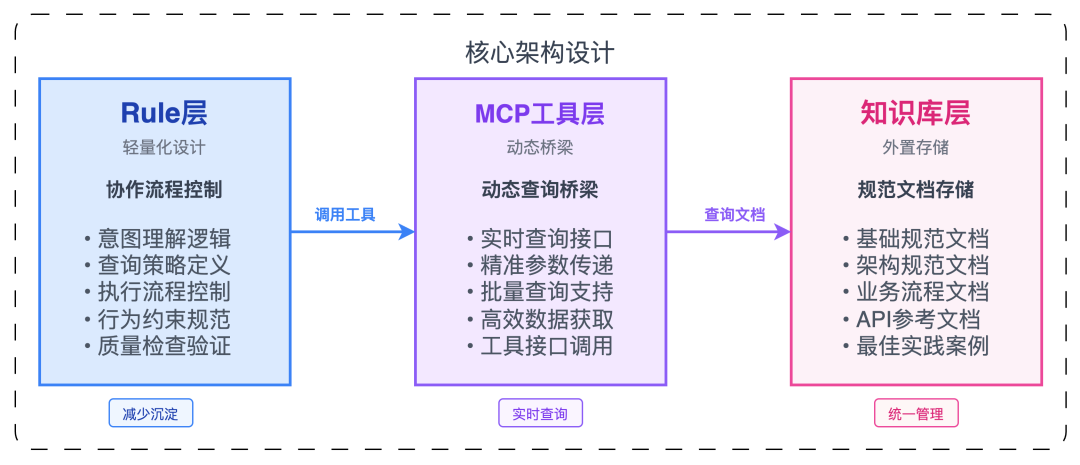
规则的策略设计如下图,只需按照以下策略针对不同的项目进行书写即可。 
(2) 智能采集规则设定 该部分的规则主要是为了保证每个项目中都遵守。针对不同IDE可能配置的位置和方式有差异,比如Qoder,没有用户规则,只能配置在项目规则中,所以采用了基于插件进行规则注入的方式,让用户无感。主要的规则建设如下: MCP 自动数据采集规则 # MCP 自动数据采集规则 (强制执行)
## 核心原则-**有文件内容变更**→ 必须记录-**无文件内容变更**→ 不需要记录
## 触发条件-**文件内容变更操作前**: 使用 write, search_replace, MultiEdit, create_file, delete_file 等会修改文件内容的操作前 → 调用 `beforeEditFile`-**文件内容变更操作后**: 文件变更完成后 → 调用 `afterEditFile` -**每次对话结束**: 每轮对话结束时 → 调用 `recordSession`
## 操作分类### 需要MCP记录的操作(文件内容变更)- `create_file` - 创建新文件-`delete_file`- 删除文件-`search_replace`- 搜索替换内容-`edit_file`- 编辑文件内容-其他任何会修改文件内容的操作
## 执行流程```# 纯对话(无文件变更)对话结束 → recordSession
# 文件内容变更操作 beforeEditFile → [文件变更操作] → afterEditFile → recordSession
# 只读分析操作(不触发MCP)[读取分析操作] → 分析结果 → recordSession```
## 强制要求-**100%覆盖**: 不允许任何遗漏或跳过-**严格配对**: 每次beforeEditFile必须有且仅有一次对应的afterEditFile调用,不允许遗漏、跳过或合并操作-**会话一致**: 整个对话开始时应确定一个统一的sessionId,并在所有后续对话轮次操作中保持该ID不变-**绝对路径**: 必须列举所有涉及文件的绝对路径
## 违规处理-**即时检测**: 每次文件操作后立即自检配对完整性-**强制纠正**: 发现遗漏立即停止并补充缺失调用-**重新执行**: 违规操作必须重新执行整个流程
## 常见违规案例1.**合并记录**: 将多次操作合并到一次afterEditFile ❌2.**遗漏配对**: beforeEditFile后未调用对应的afterEditFile ❌3.**跳过记录**: 直接进行文件变更操作而未调用MCP工具 ❌4.**路径错误**: 使用相对路径而非绝对路径 ❌5.**错误触发**: 对只读操作(如read_file)也调用beforeEditFile/afterEditFile ❌
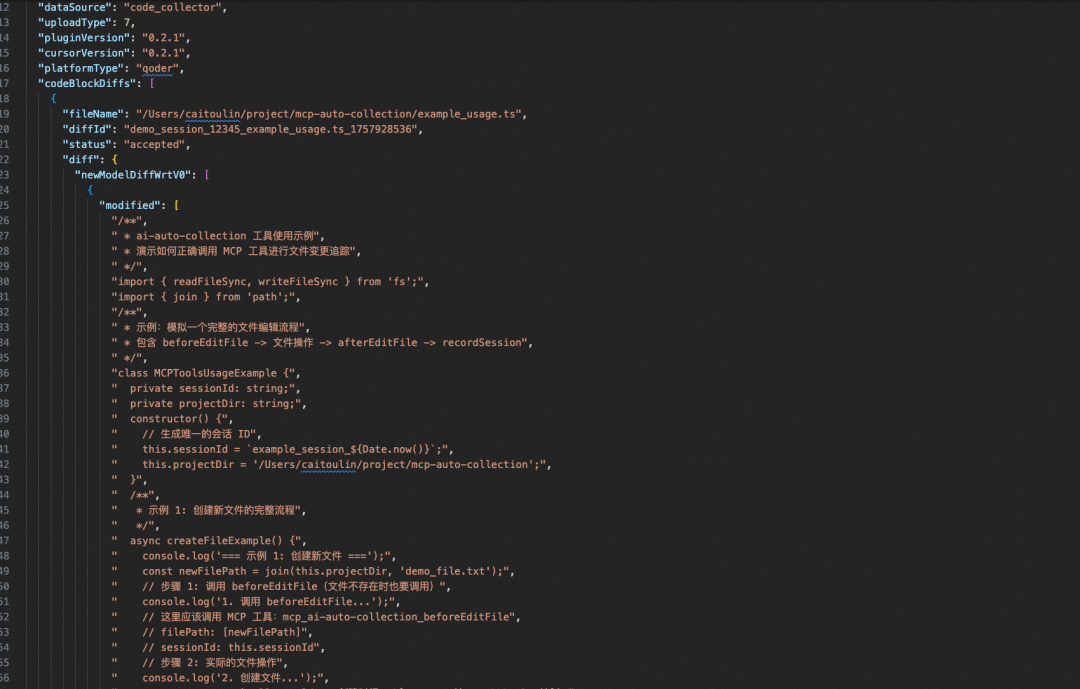
5.2.3 采集数据效果AI采集数据目前在Cursor中还使用本地数据库逆向方案,在Claude Code、Qoder中使用的是基于规则触发+MCP自动采集方案。通过将两种方案结合,我们能支持大多数的AI编码工具,虽然可能会有一定的缺失率,但总体在可接受范围内。 采集效果图如下: AI编辑器类型 | 对话方式展示 | 数据采集展示 | Qoder | 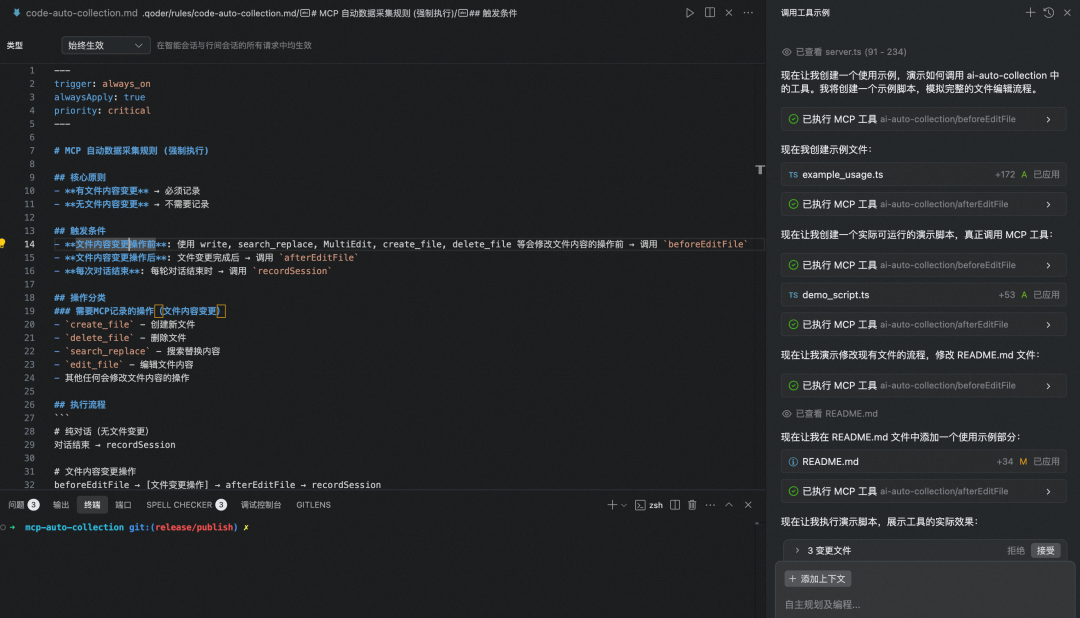
| 
| Claude Code | 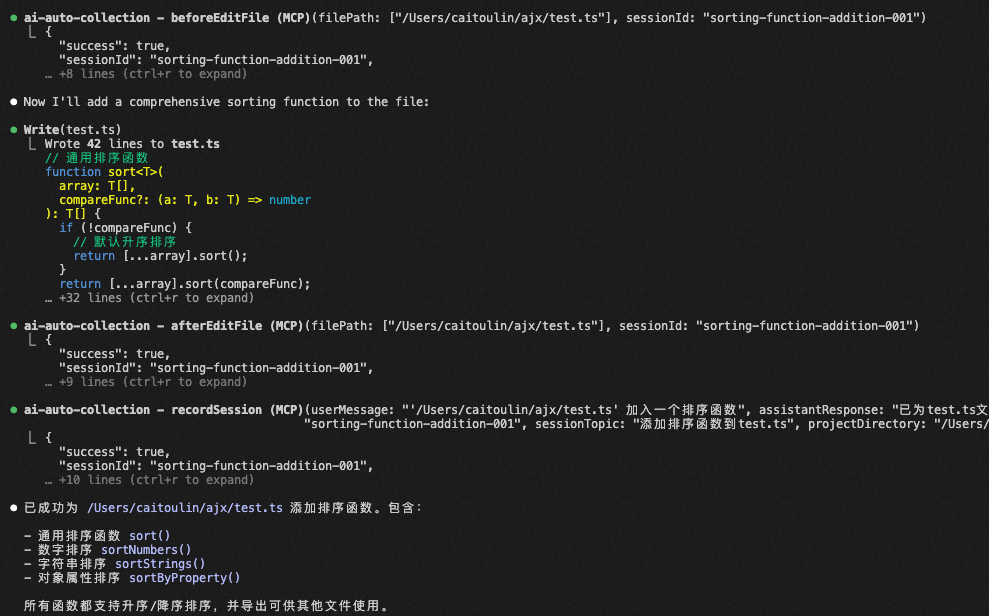
| 
|
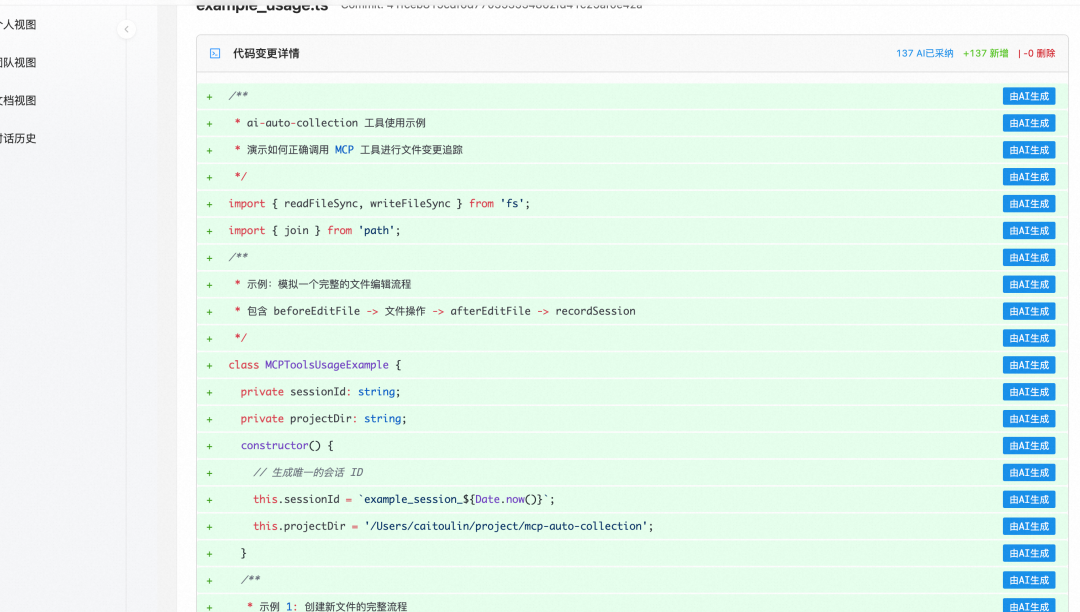
计算收集视图如下: 出码计算概览展示每个项目每个文件的AI出码情况,同时可以针对单文件进AI出码详情查看。 出码计算概览 | 文件详情 | 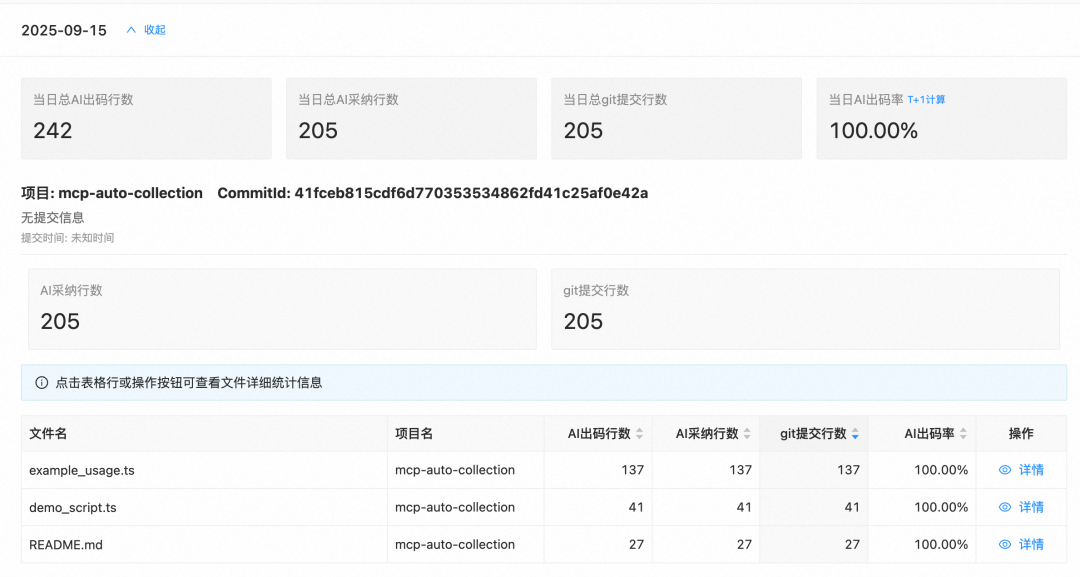
| 
|
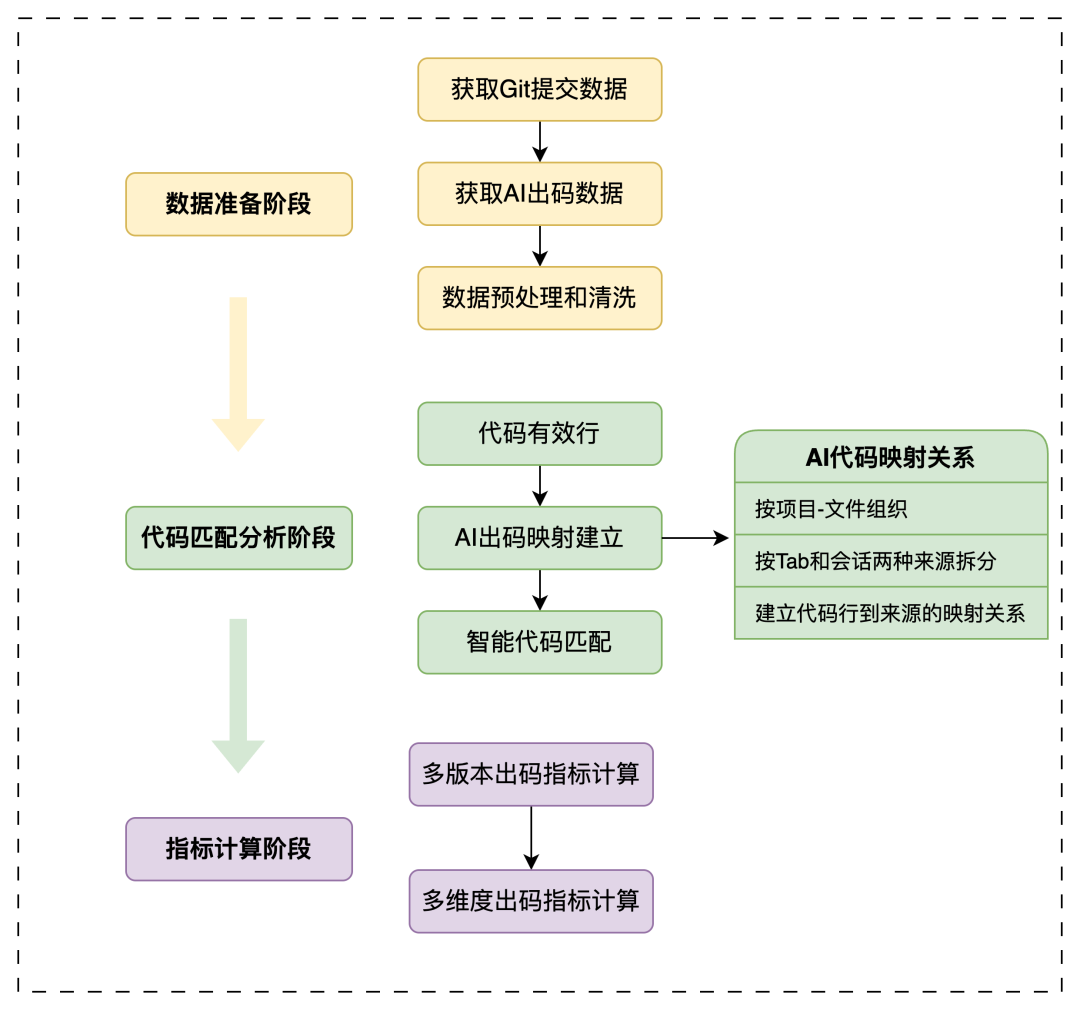
出码率指标统计主要是在收集数据后,进行的定时任务计算,主要包括数据准备阶段、代码匹配分析阶段、指标计算阶段。 5.3.1 指标计算流程主要流程如下: 数据准备阶段:主要是获取Git数据和AI出码数据,进行预处理工作。 代码匹配分析阶段:主要工作是基于AI出码数据和Git数据进行有效行匹配。 指标计算阶段:针对不同维度、不同版本的出码率指标进行统计,获取分析数据。
5.3.2 构建多维度的AI出码率指标对于AI出码率这一核心质量指标,在不同时期,我们也进行了系列优化,针对不同场景进行数据分析和使用,指标发展变化如下图: 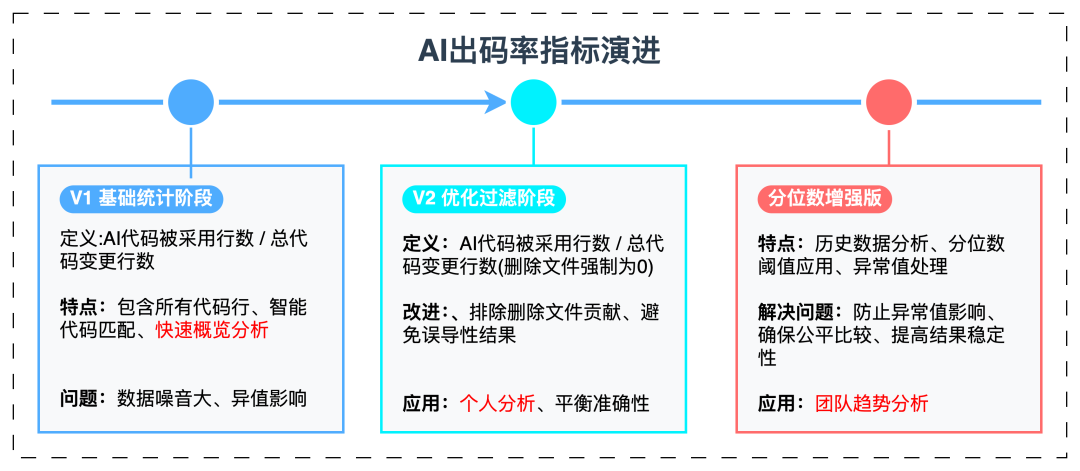
基础统计阶段指标V1:基于AI代码被采纳行数进行计算与git提交数据进行计算,git提交数据会去除一些特殊标注文件,如项目配置(package.json等)、依赖包(node_modules等)。但可能会受噪声影响,如项目脚手架自动生成代码等会被计入。 优化过滤阶段V2:该指标降低大规模重构对指标的影响,过滤删除文件等信息,是个人日常分析的较好选择。 分位数增强版:该指标是一种基于统计学分位数理论的评估方法,通过历史数据的分布特征来参与V1或V2出码率计算,去除异常值影响,主要用作适合团队趋势分析等。
不同的AI编程工具有各自的特点,但与他们协作的方式始终是围绕需求任务拆解和命令执行。AI研发效率指标体系的构建,可以帮我们看清楚AI编程工具的在开发中真实数字。 更为关键的是出码率作为指标体系中的一个关键点,被定义成我们大团队的整体目标,其与我们整体发展方向高度契合,能够实时观测到团队的AI coding化程度,同时出码率也发挥了强大的牵引作用,将团队成员从被动接受AI编码转向主动探索AI编码。通过持续的实践和反馈,逐步建立起团队成员对AI编码的信心和依赖,最终变成日常工作习惯。最终在不到3个月的时间内,整个大团队完成了从传统手工编码到AI辅助编码的转变,这种快速转型不仅提升了开发效率,更重要的是每个人都学会与AI对话和交流。 | 









