模型架构模型整体架构与mBART类似,遵循vision-encoder-decoder架构,这点和之前字节开源的dolphin架构类似。 - 视觉编码器:ViT-H模型(https://huggingface.co/nvidia/C-RADIO)
- 适配层:一维卷积和归一化,以压缩潜在空间的维度和序列长度(13184个token到3201个token)
- 分词器:使用此模型中包含的分词器受CC-BY-4.0许可证的约束
功能版式分析识别的标签:标题、节、图例、索引、脚注、列表、表格、参考文献、图像  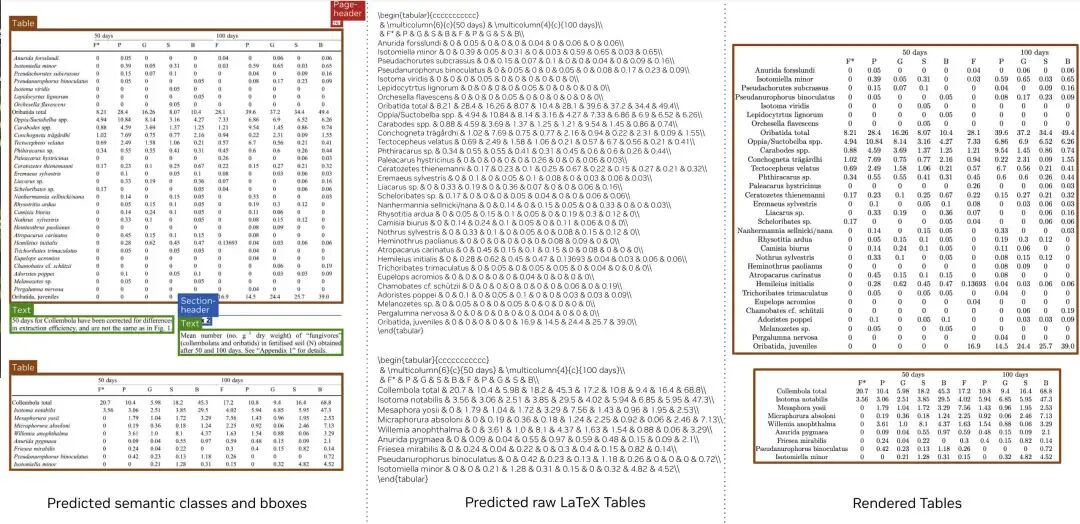 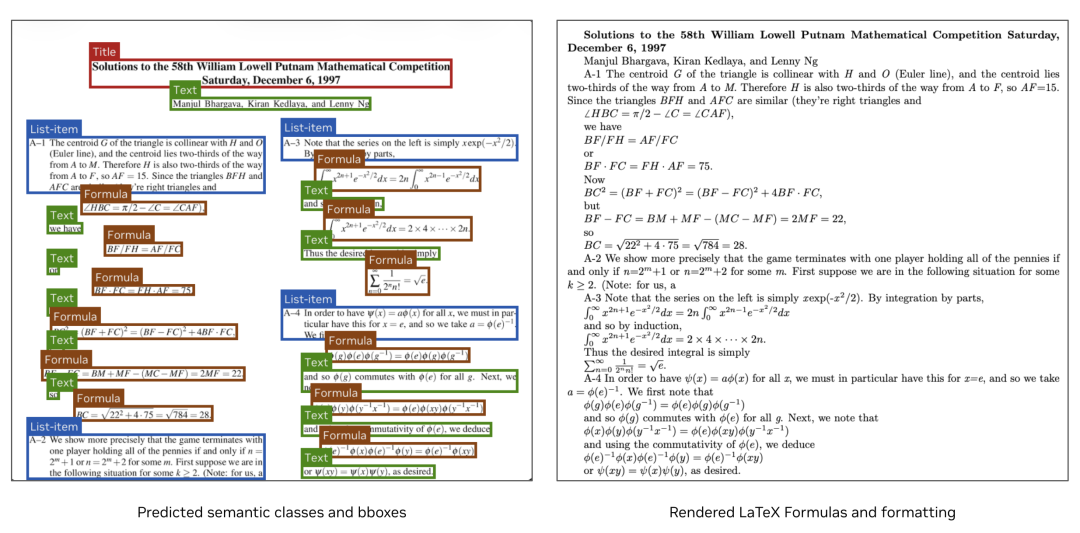 权重(已支持vllm推理):https://huggingface.co/nvidia/NVIDIA-Nemotron-Parse-v1.1
| 









