链载Ai
标题: 图解DeepSeek-R1推理模型实现原理 [打印本页]
作者: 链载Ai 时间: 昨天 17:15
标题: 图解DeepSeek-R1推理模型实现原理
ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;margin: 10px 0px;letter-spacing: 0.1em;white-space: pre-line;color: rgb(63, 63, 63);font-size: 17px;">DeepSeek-R1的发布在AI发展进程中具有里程碑式的意义,尤其对机器学习研发社区而言意义重大,主要原因有二:- ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;margin: 10px 0px;letter-spacing: 0.1em;white-space: pre-line;color: rgb(63, 63, 63);font-size: 17px;">开源策略:提供了经过轻量化处理的蒸馏版本
- ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;margin: 10px 0px;letter-spacing: 0.1em;white-space: pre-line;color: rgb(63, 63, 63);font-size: 17px;">技术透明:公开分享了如何构建类似OpenAI O1这样对的推理模型的完整训练方法
ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;margin:10px 0px;letter-spacing:0.1em;white-space:pre-line;color:rgb(63, 63, 63);font-size:17px;">
ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;margin:10px 0px;letter-spacing:0.1em;white-space:pre-line;color:rgb(63, 63, 63);font-size:17px;">接下来,让我们深入了解这个模型是如何构建的。
ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 22px;font-weight: bold;margin: 40px auto 40px 0px;width: fit-content;text-align: left;color: rgb(63, 63, 63);">
ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 22px;font-weight: bold;margin: 40px auto 40px 0px;width: fit-content;text-align: left;color: rgb(63, 63, 63);">目录
- ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;margin: 10px 0px;letter-spacing: 0.1em;white-space: pre-line;color: rgb(63, 63, 63);font-size: 17px;"> 2.1专注于长链式推理的监督数据集
- ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;margin: 10px 0px;letter-spacing: 0.1em;white-space: pre-line;color: rgb(63, 63, 63);font-size: 17px;"> 2.2构建专精推理的过渡模型
- ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;margin: 10px 0px;letter-spacing: 0.1em;white-space: pre-line;color: rgb(63, 63, 63);font-size: 17px;"> 2.3基于大规模强化学习的核心技术
一、大语言模型的基本训练流程
DeepSeek-R1与其他大语言模型一样,采用逐词生成的方式工作。它之所以在数学和推理问题上表现出色,关键在于它会生成详细的思维过程,通过更多的推理步骤来解决问题。

通用大模型训练通常包含三个阶段:
 1.预训练阶段:基于海量互联网数据的next-token预测,形成基础能力2.监督微调阶段:指令理解与执行训练,构建基础对话能力(SFT模型)3.偏好对齐阶段:依据人类偏好优化模型行为,产出可用版本
1.预训练阶段:基于海量互联网数据的next-token预测,形成基础能力2.监督微调阶段:指令理解与执行训练,构建基础对话能力(SFT模型)3.偏好对齐阶段:依据人类偏好优化模型行为,产出可用版本二、DeepSeek-R1的创新训练方法

DeepSeek-R1在遵循上述基本流程的同时,在具体实现上有很多创新:
2.1 专注于长链式推理的训练数据
模型使用了60万个包含详细推理过程的训练样本。这种规模的高质量推理数据通过人工标注的方式获取成本极高,因此团队采用了特殊的数据生成方法。
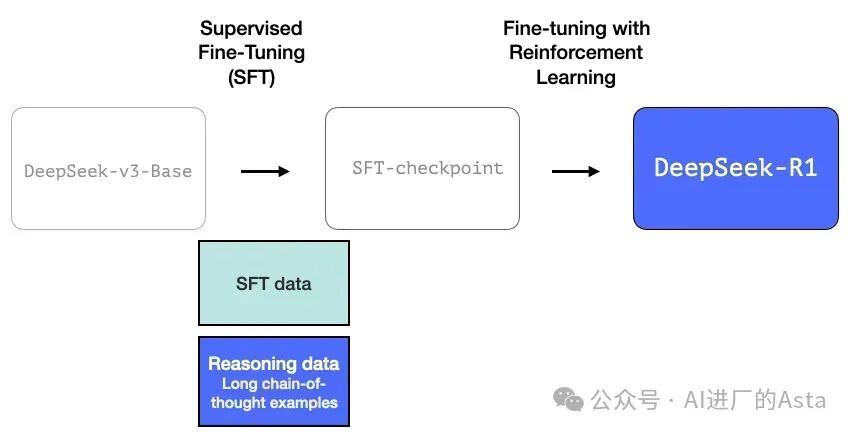
2.2 构建专精推理的过渡模型
团队首先开发了一个专注于推理能力的中间模型。这个未命名的模型虽然在其他方面表现一般,但它只需要少量标注数据就能在推理问题上表现出色。这个模型随后被用来生成大规模的训练数据,帮助训练出既擅长推理又能胜任其他任务的最终版本。
2.3 基于大规模强化学习的核心技术
强化学习训练分为两个关键阶段:
2.3.1 R1-Zero:推理导向的强化学习
通过强化学习构建中间推理模型,用于生成SFT训练样本。这一突破源于早期R1-Zero模型的实验成果。
DeepSeek团队首先开发了R1-Zero模型,它最特别的地方在于无需大量标注数据就能在推理任务上表现优异。它直接从预训练模型开始,通过强化学习达到了能与OpenAI O1竞争的水平。
这一突破性进展揭示了两个重要发现:
让我们通过一个具体例子来理解推理问题的自动验证过程:
假设向模型提供以下编程任务:
编写Python代码,接受一个数字列表,按排序顺序返回它们,但也在开头添加42。
这样的问题可以通过多种方式进行自动验证。假设我们将这个问题呈现给正在训练的模型,它生成一个完成:
我们可以在训练步骤中向模型呈现这样的问题,并生成多个可能的解决方案。
在训练过程中,模型会生成多个可能的解决方案,系统会自动评估每个方案的质量。比如:
这些都是可以直接用来改进模型的信号。当然,这是在许多示例(小批量)中完成的,并在连续的训练步骤中进行。
这些奖励信号和模型更新是模型在 RL 训练过程中继续改进任务的方式,如论文图 2 所示。
与这种能力的提高相对应的是生成响应的长度,其中模型生成更多思考词元来处理问题。
这个过程很有用,但 R1-Zero 模型尽管在这些推理问题上得分很高,却面临其他使其不如预期可用的问题。
尽管 DeepSeek-R1-Zero 表现出强大的推理能力,并自主发展出意想不到且强大的推理行为,但它面临几个问题。例如,DeepSeek-R1-Zero 在可读性差和语言混合等挑战方面存在困难。
R1 旨在成为一个更易用的模型。因此,它不是完全依赖 RL 过程,而是在我们之前在本节中提到的两个地方使用它:
创建一个中间推理模型来生成SFT数据点
训练R1模型以改进推理和非推理问题(使用其他类型的推理器)
2.3.2 利用过渡模型生成高质量训练数据
为了使中间推理模型更有用,它在几千个推理问题示例上进行监督微调(SFT)训练步骤(其中一些是从 R1-Zero 生成和筛选的)。论文将此称为"冷启动数据":
冷启动
与 DeepSeek-R1-Zero 不同,为了防止从基础模型开始的 RL 训练早期不稳定的冷启动阶段,对于 DeepSeek-R1,我们构建和收集少量长链思维数据来微调模型,作为初始 RL 参与者。为了收集这些数据,我们探索了几种方法:
这个初始数据集虽然只有约5000个样本,但它为后续扩展到60万个高质量训练样本提供了基础。这个"数据放大"过程正是中间推理模型的关键作用。
而监督微调(SFT)过程则确保了模型能够快速准确地完成任务。每个训练样本都包含了详细的问题解决过程,帮助模型形成清晰的思维链条。
2.3.3 全方位的强化学习优化
最终的R1模型采用了更全面的强化学习策略。除了继承前面阶段的推理能力,还引入了:
这使得R1不仅保持了强大的推理能力,还能够胜任各种日常对话和通用任务。
架构设计
就像 GPT2 和 GPT3 初期的前代模型一样,DeepSeek-R1 是一堆 Transformer 解码器块。它由 61 个块组成。前三个是密集的,但其余的是专家混合层。这种设计既保证了模型的性能,又提高了计算效率。
在模型维度大小和其他超参数方面,它们看起来是这样的:
| 欢迎光临 链载Ai (https://www.lianzai.com/) |
Powered by Discuz! X3.5 |