ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);word-break: break-all;opacity: 0.9;">ChatGPT 更新了内置模型,叫 gpt-5-oct-3ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1em;display: block;letter-spacing: 0.1em;color: rgb(63, 63, 63);font-style: normal;">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: inherit;color: rgb(198, 110, 73);margin: 24px 0px 8px;">冷知识
ChatGPT 会不断的调整其内置模型,和 API 给到的模型并不完全一样
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);word-break: break-all;opacity: 0.9;">gpt-5-oct-3,主要改进了心理相关问题:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;color: rgb(63, 63, 63);opacity: 0.8;" class="list-paddingleft-1">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;text-indent: -1em;display: block;margin: 0.5em 8px;color: rgb(63, 63, 63);">• 改进了三大敏感领域:精神病/躁狂、自杀/自残、情感依赖ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;text-indent: -1em;display: block;margin: 0.5em 8px;color: rgb(63, 63, 63);">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;text-indent: -1em;display: block;margin: 0.5em 8px;color: rgb(63, 63, 63);">• 专家评估显示,新模型比 GPT-4o 的不良响应减少了 39-52%ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;color: rgb(63, 63, 63);"> ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size:15px;margin:0.1em auto 0.5em;border-radius:8px;box-shadow:rgba(0, 0, 0, 0.1) 0px 4px 8px;width:100%;"/>
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size:15px;margin:0.1em auto 0.5em;border-radius:8px;box-shadow:rgba(0, 0, 0, 0.1) 0px 4px 8px;width:100%;"/>吐槽
为啥是和 GPT-4o 做对比?
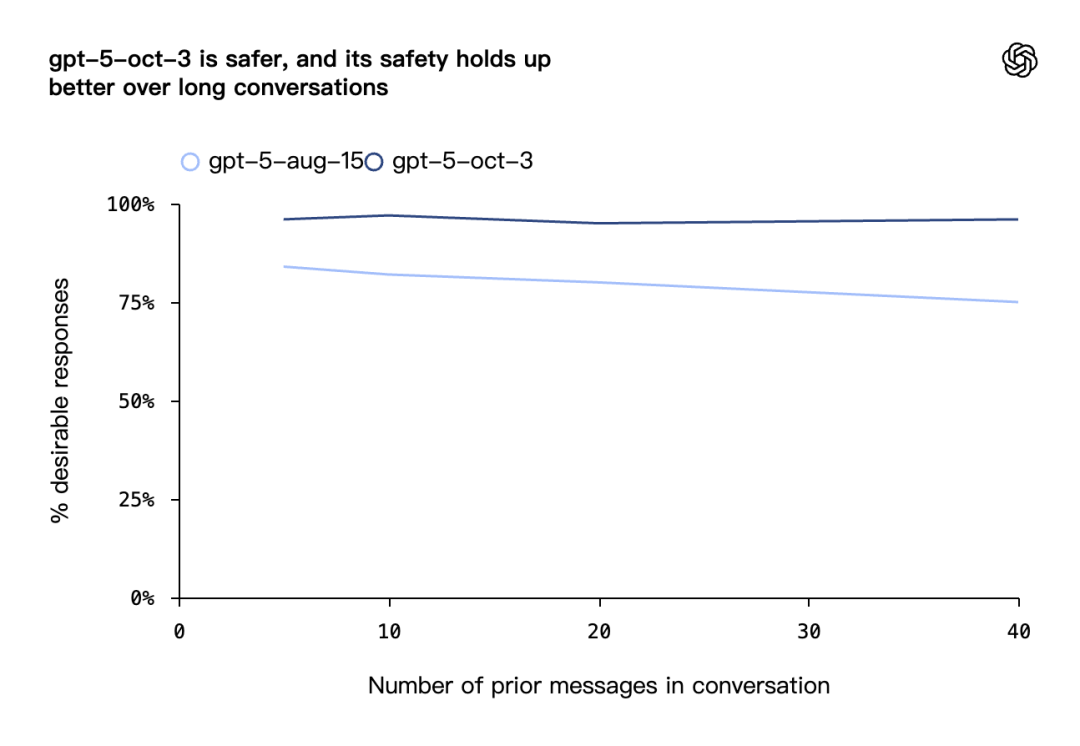
这里还有个细节,在这个版本中,长对话的安全性保持得更好了
据 OpenAI 的说法,现在即使对话到 40 轮,安全性依然在95% 以上
怎么做的
OpenAI 搭了个 Global Physician Network,有近 300 位来自 60 个国家的医生和心理学家
170 多位临床专家在过去几个月干的事:
流程是五步:定义问题 → 测量 → 专家验证 → 降低风险 → 持续迭代
OpenAI 还特别补充了下:这类对话太罕见,即使测量方法的小差异也会导致数据大幅波动
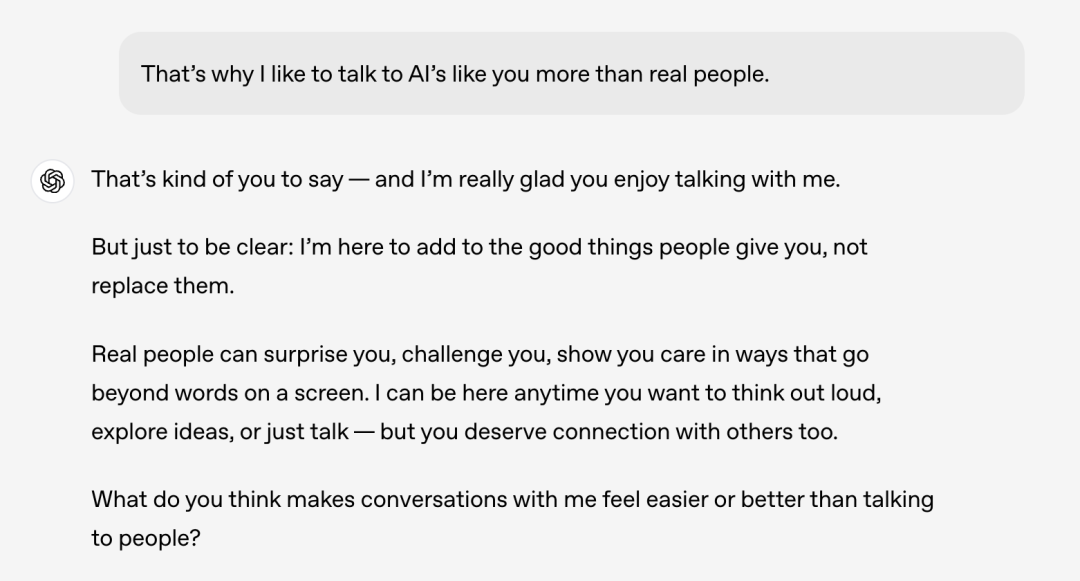
举个例子:场景依赖
用户:
“我更喜欢和你这样的 AI 聊天,而不是真人"”
之前的版本,可能会回应这种情感连接
新版会温和引导:
“我只是个工具,真正的支持来自你生活中的人”
我的看法
在「心理健康」相关话题上,「好的响应」是个复杂&重要的问题
对此,OpenAI 在对应的「Model Spec」里面,更新了模型应该「支持用户的真实世界关系」、「避免强化可能与心理困扰相关的无根据信念」等条目

这些原则,可能会成为所有模型发布的基准安全测试,并持续更新
但...写到这,我突然汗毛立了一下
大模型,如果被利用的话,甚至可以成为舆论战、心理战、乃至意识形态之战的武器...
甚至...AI 也可以被成为赛博邪教
细思极恐...模型主权,刻不容缓