安装完成开始运行,使用命令ollama ps可以看到deepseek-r1:32b完全运行在GPU上。GPU使用的是2张A10 NVIDIA卡。提个问题试试。

回复测试没问题。回复/bye或者按Ctrl+D退出。
3、外部网络访问
一开始直接启动,默认访问地址是127.0.0.1:11434,只允许本地访问。如果要放开外部访问,需要进行Ollama设置。
sudo vim /etc/systemd/system/ollama.service
在[Service]下面加上:
Environment="OLLAMA_HOST=0.0.0.0:11434" #运行所有地址访问
Environment="OLLAMA_ORIGINS=*"#运行跨域访问
sudo systemctl daemon-reload
sudo systemctl restart ollama
4、使用Chrome浏览器插件访问
在本地浏览器上安装Page Assist作为web ui,访问插件地址https://chromewebstore.google.com/search/Page%20Assist?hl=zh-CN&utm_source=ext_sidebar
安装完成后打开
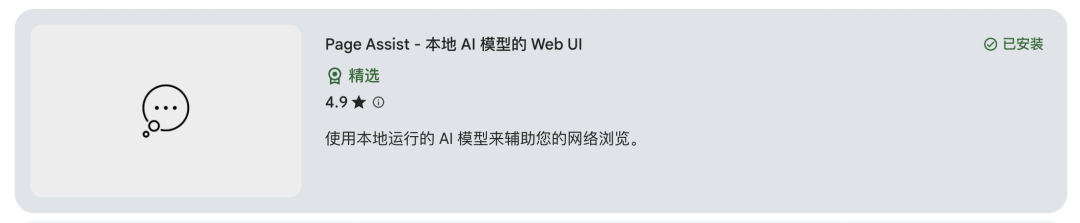
5、使用DeepSeek联网搜索
当在没开启联网搜索时,询问当前日期是多少,它是无法回答的,只有开启才可以。

我本地deepseek模型是运行在服务器上的,且切断了互联网,它不可能直接联网查询。
Page Assist作为浏览器扩展,它的联网功能是独立于DeepSeek模型运行的,当用户开启联网搜索时,Page Assist会通过预设置的浏览器直接访问互联网,用搜索引擎先进行实时查询,把获取的网络信息作为上下文,然后将这些信息与用户问题一起发送给本地的DeepSeek模型进行问题回答生成,最后再反馈给用户。大体流程如下图。