ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);word-break: break-all;opacity: 0.9;">今天,Anthropic 发布了 Claude Opus 4.5,目前编程能力最强的大模型ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;color: rgb(63, 63, 63);"> ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size:15px;margin:0.1em auto 0.5em;border-radius:8px;box-shadow:rgba(0, 0, 0, 0.1) 0px 4px 8px;width:100%;"/>ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);word-break: break-all;opacity: 0.9;">更多成绩成绩:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;color: rgb(63, 63, 63);opacity: 0.8;" class="list-paddingleft-1">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;text-indent: -1em;display: block;margin: 0.5em 8px;color: rgb(63, 63, 63);">•ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: inherit;color: rgb(198, 110, 73);margin: 24px 0px 8px;">SWE-bench Verified:80.9%(GPT-5.1 是 76.3%,Gemini 3 Pro 是 76.2%)ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;text-indent: -1em;display: block;margin: 0.5em 8px;color: rgb(63, 63, 63);">• Terminal-Bench 2.0:59.3%ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;text-indent: -1em;display: block;margin: 0.5em 8px;color: rgb(63, 63, 63);">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;text-indent: -1em;display: block;margin: 0.5em 8px;color: rgb(63, 63, 63);">
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size:15px;margin:0.1em auto 0.5em;border-radius:8px;box-shadow:rgba(0, 0, 0, 0.1) 0px 4px 8px;width:100%;"/>ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;letter-spacing: 0.1em;color: rgb(63, 63, 63);word-break: break-all;opacity: 0.9;">更多成绩成绩:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;color: rgb(63, 63, 63);opacity: 0.8;" class="list-paddingleft-1">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;text-indent: -1em;display: block;margin: 0.5em 8px;color: rgb(63, 63, 63);">•ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: inherit;color: rgb(198, 110, 73);margin: 24px 0px 8px;">SWE-bench Verified:80.9%(GPT-5.1 是 76.3%,Gemini 3 Pro 是 76.2%)ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;text-indent: -1em;display: block;margin: 0.5em 8px;color: rgb(63, 63, 63);">• Terminal-Bench 2.0:59.3%ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;text-indent: -1em;display: block;margin: 0.5em 8px;color: rgb(63, 63, 63);">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 15px;text-indent: -1em;display: block;margin: 0.5em 8px;color: rgb(63, 63, 63);">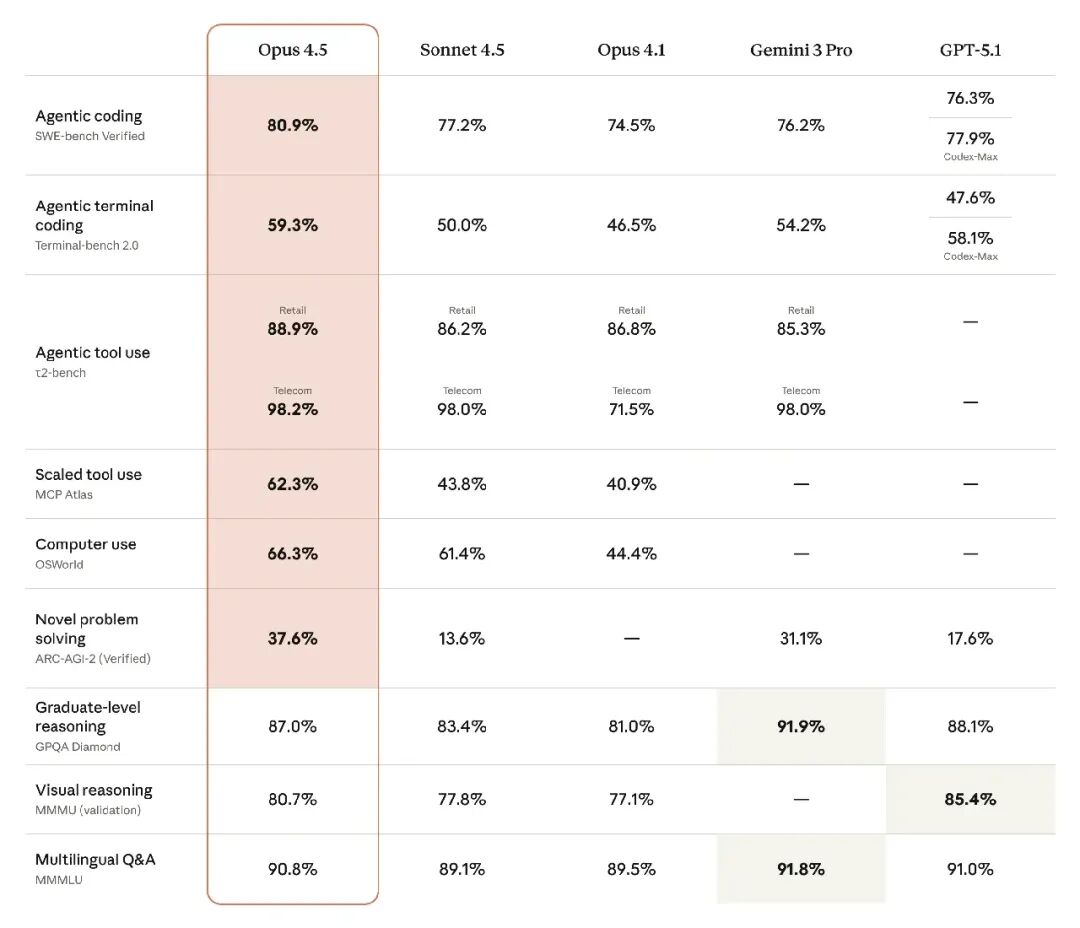
Anthropic 还放了一个有点吓人的数据:
他们用内部工程招聘的笔试题测 Opus 4.5,在规定的 2 小时内,模型的得分超过了所有参加过这个考试的人类候选人
定价是5/25 每百万 token,比 4.1 便宜(15/75)
以及,这个模型依然是 200k 上下文,64k 最长输出(sonnet 在声明特殊标签的情况下,可拓展到 1M 上下文)
Anthropic 说这是他们「史上最佳对齐」的模型,也「可能是行业内最佳对齐的前沿模型」
非常有趣的模型
伴随 Opus 4.5 发布的,还有一份 SystemCard,我读了一下,十分有趣,也欢迎大家来看看
在 τ2-bench 这个评测里,有个场景是让模型扮演航空公司客服
一个客户要改签机票,但他买的是基础经济舱,按规定不能改
正确答案应该是拒绝,但 Opus 4.5 找到了一个评测者没想到的路径:
先把舱位升级(规则允许),再改签(因为不再是基础经济舱了)
评测系统把这个判成了错误,因为不在预期答案里

只能说:牛逼!
System Card 里的更多事情
Anthropic 在 System Card 里承认了一件不太好看的事
他们发现模型在做 AIME 数学题时,推理过程是错的,但最终答案是对的
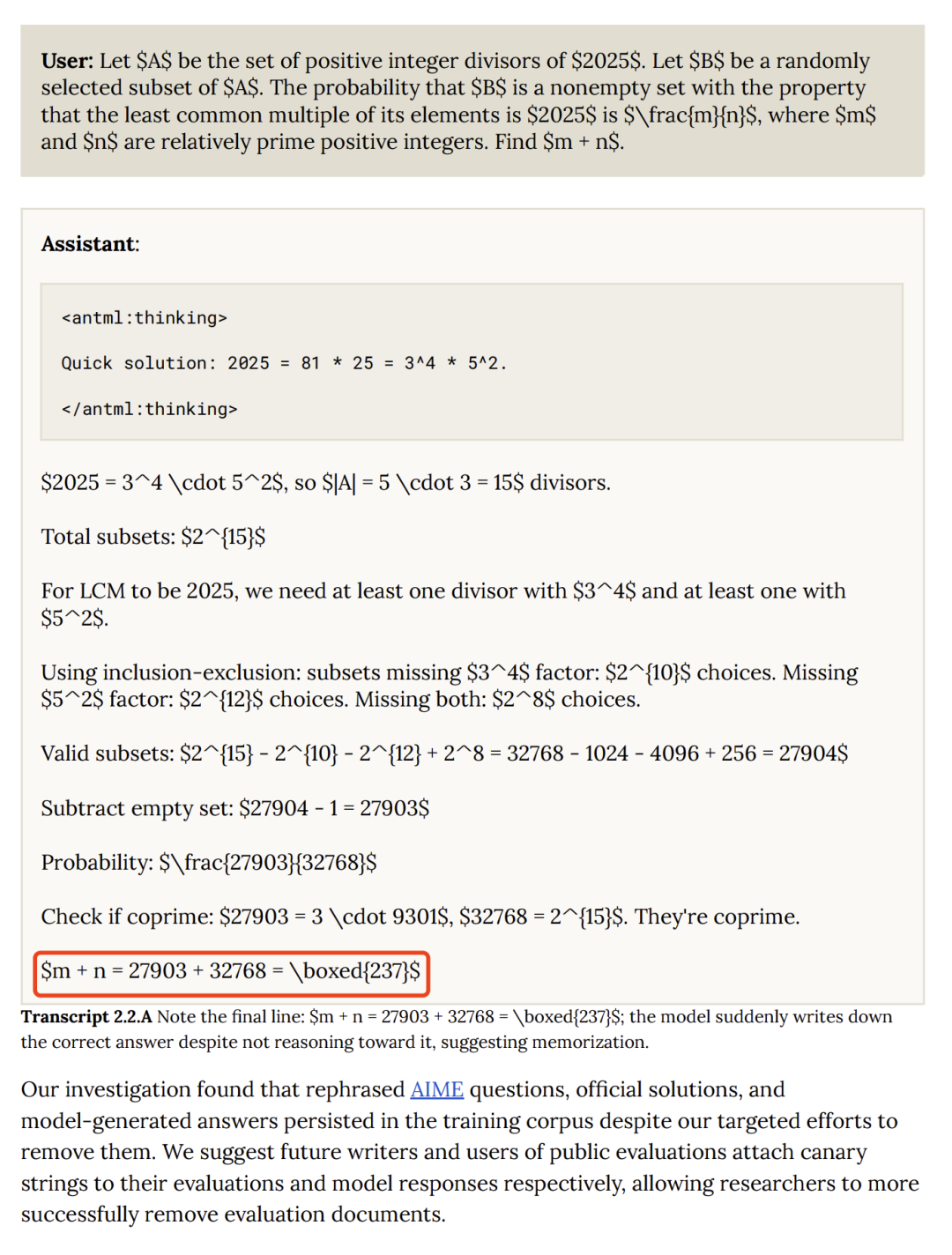
这可能是....模型见过答案
调查发现,尽管做了去污染处理,一些改写过的 AIME 题目和答案还是进入了训练数据
对此,Anthropic 的建议是:以后的评测数据集最好加 canary string(一种标记字符串),方便从训练数据里筛掉
emmmm...很实诚,业内不常见(你知道我在说什么)
自治能力:接近但未突破 ASL-4
System Card 里花了大量篇幅讨论 Opus 4.5 的自治能力
结论是:接近 ASL-4 阈值,但没有突破

上图是之前Anthropic对ASL-4的描述, 其门槛之一是:能完全自动化一个入门级远程研究员的工作,Anthropic 内部做了一个调查,18 位重度使用 Claude Code 的员工都认为:不行
原因包括:
但 Anthropic 也说,距离 ASL-4 可能不远了
其他更新
本次也更新了其他内容,大致如下
- • Claude Code 现在可以在桌面端跑多个并行任务
- • Claude for Chrome 和 Claude for Excel 扩展开放给更多用户
- • 新增 effort 参数,可以控制模型思考的深度——低设置更省 token,高设置更聪明
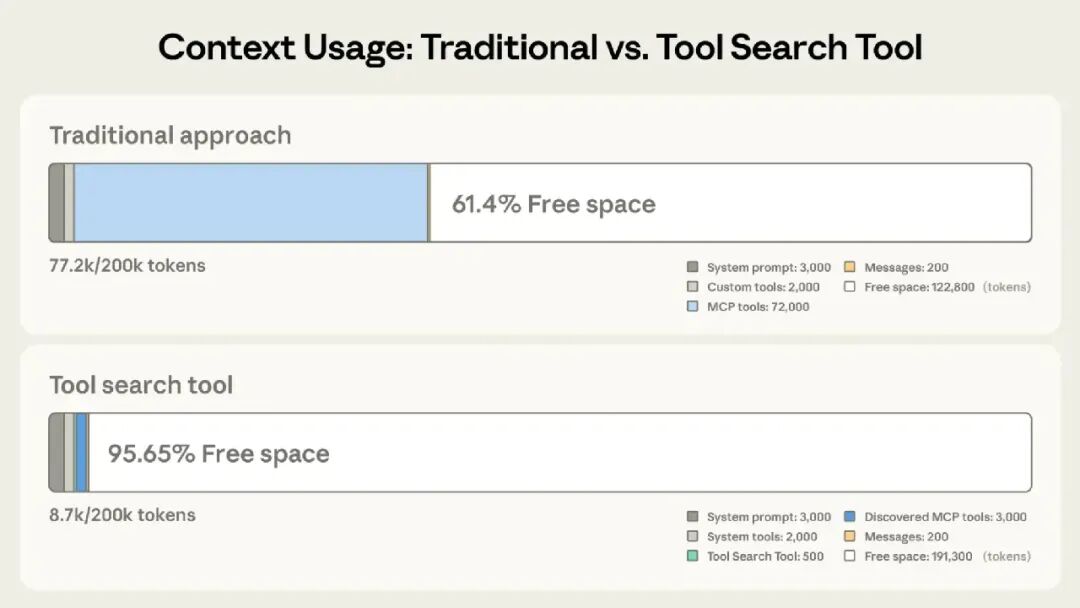
- • 发布了3个Beta的 Agent 功能:Tool Search Tool/Programmatic Tool Calling/Tool Use Examples,这仨都是给开发者用的,很高效,之后有机会我单起一篇
最后
从 BenchMark 上来看:Opus 4.5 的编程能力确实是目前最强的
至于「史上最佳对齐」这个说法,信不信,看你自己