trick 4:关于调参
调参一定要做好笔记,每次只调1个参数。
有哪些参数可以调呢?
4.1 关于 Loss function 调参策略
是Model和数据之外,第三重要的参数。具体使用MSE、Cross entropy、Focal还是其他自定义,需要具体问题具体分析。
4.2 关于 Learning rate 和 batch size 调参策略
- Learningrate和batch size是两个重要的参数,而且二者也是相互影响的,在反向传播时直接影响梯度。一般情况下,先调batchsize,再调learning rate。
- batch size不能太大,也不能太小,一般设置为16的倍数。
- 特殊情况:batch size 在表示学习,对比学习领域一般越大越好,显存不够上累计梯度,否则模型可能不收敛… 其他领域看情况;
- 一般nlp bert类模型在1e-5级别附近,warmup,衰减;
- cv类模型在1e-3级别附近,衰减;具体需要多尝试一下。
- learningrate设置上有很多trick,包括cosing learning rate,warmup,衰减等。
4.3 关于 Epoch number 和 early stopping 调参策略
- Epoch number和Early stopping是息息相关的,需要输出loss看一下,到底是什么epoch9时效果最好,及时early stopping;
- Epoch越大,会浪费计算资源;epoch太小,则训练模型提取特征没到极致;
- 此外,也要明自Epoch、lteration、batchsize的关系。
注:
不要过早的early stopping,有时候收敛平台在后段
对于数据量巨大的推荐系统的模型来说一个epoch足矣,再多就会过拟合。
4.4 关于 Optimizer 调参策略
- Adam和SGDM是最常用的两个,前者能快速收敛,后者收敛慢但最终精度更高。现在大家会先使用Adam快速收敛,后面再用SGDM提升精度。
注:nlp,抽象层次较高或目标函数非常不平滑的任务优先使用adam,其他可以尝试下sgd(一般需要的迭代次数高于sgd)
4.5 关于 Activation function 调参策略
- ReLu、Sigmoid、Softmax、Tanh是最常用的4个激活函数9。
- 对于输出层,常用sigmoid9和softMax激活函数,中间层Q常用ReLu激活函数,RNN常用Tanh激活函数。
4.6 关于 Weights initialization 调参策略
- 预训练参数是最好的参数初始化方式,其次是Xavir。
4.7 关于 Regularization 调参策略
- Dropout虽然思想很简单,但效果出奇的好,现在大部分任务都需要使用预训练型,要注意型内部dropout ratio是一个很重要的参数,首选0.5,使用默认值不一定最优,有时候dropoutreset到0有奇效;
4.8 关于 Validation 调参策略
- 在 Validation 筛选模型参数时,可以除loss函数9外,设置某种规则引导模型向某个想要的方向去更新参数。
trick 5:模型训练过拟合和欠拟合问题?
模型训练过程中的过拟合(Overfitting)和欠拟合(Underfitting)是两个常见的问题,它们影响模型的泛化能力,即模型在未见过的新数据上的表现。
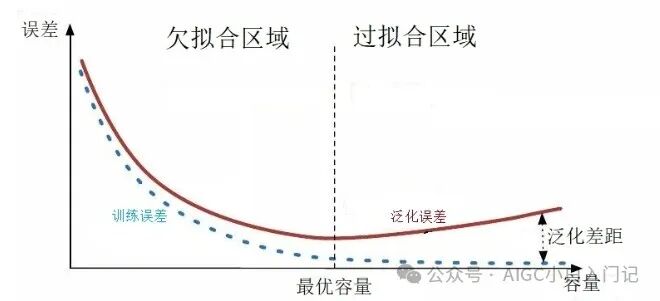
5.1 欠拟合(Underfitting)
- 欠拟合(Underfitting)判断:欠拟合发生时,模型无法捕捉数据中的底层模式,导致模型在训练数据上表现不佳,同时在测试数据上的表现也会较差
- 欠拟合(Underfitting)发生原因:其主要原因是模型过于简单,不足以表达数据集中的复杂关系。欠拟合的迹象包括训练误差和验证误差都很高,且两者接近。
- 增加模型复杂度:通过增加网络层数、节点数或使用更复杂的模型结构来提高模型的表达能力。
- 增加特征:引入更多相关特征,帮助模型更好地理解数据。
- 调整模型参数:优化模型参数设置,如学习率、批次大小等,以促进更好的学习。
- 减少正则化强度:如果使用了正则化但模型依然欠拟合,可能需要减小正则化参数。
5.2 过拟合(Overfitting)
- 过拟合(Overfitting)危害:过拟合的特征是训练误差很低,而验证或测试误差较高
- 过拟合(Overfitting)发生原因:过拟合则是模型在训练数据上表现过于优秀,以至于它学习到了训练数据中的噪声和偶然特性,而不是数据的真实分布。这导致模型在未见过的测试数据上的表现显著下降。
- 正则化:通过在损失函数中加入正则项(如L1、L2正则化),限制模型参数的大小,避免参数过度优化训练数据中的细节。
- 早停法(Early Stopping):在验证集上的性能不再提升时停止训练。
- 交叉验证:使用K折交叉验证等方法更准确地评估模型性能,避免过拟合。
- Dropout:随机“丢弃”一部分神经元,减少模型对特定训练样本的依赖。
- 数据增强:通过变换原始数据生成额外的训练样本,增加模型的泛化能力。
- 简化模型:减少模型复杂度,如减少神经网络的层数或节点数,避免不必要的复杂性。
个人经验:如果过拟合,首先是dropout,然后batchnorm,过拟合越严重dropout+bn加的地方就越多,有些直接对embedding层加,有奇效。
trick 6:模型参数初始化方法
linear/cnn一般选用kaiminguniform 或者normalize,embedding一般选择截断normalize,论文很多,可以去看看。
trick 7:Normalization 选择问题
GN,BN和LN都是在神经网络训练时的归一化方法,BN即Batch Normalization,LN即Layer Normalization。
- BatchNorm:batch方向做归一化,计算NHW的均值
- LayerNorm:channel方向做归一化,计算CHW的均值
- InstanceNorm:一个channel内做归一化,计算H*W的均值
- GroupNorm:先将channel方向分group,然后每个group内做归一化,计算(C//G)HW的均值
GN与LN和IN有关,这两种标准化方法在训练循环(RNN / LSTM)或生成(GAN)模型方面特别成功。
trick 7:模型输出层选择问题
基于banckbone 构建层次化的neck一般都比直接使用最后一层输出要好,reduce function一般attention 优于简单pooling,多任务需要构建不同的qkv
trick 8:随机数种子设定问题
随机数种子设定好,否则很多对比实验结论不一定准确
trick 9:cross validation问题
cross validation方式要结合任务设计,数据标签设计,其中时序数据要避免未来信息泄漏
trick 10:新模型开发前期问题
做新模型的时候,最开始不要加激活函数,不要加batchnorm,不要加dropout,先就纯模型。然后再一步一步的实验,不要过于信赖经典的模型结构(除非它是预训练的),比如加了dropout一定会有效果,或者加了batchnorm一定会有提升所以先加上,首先你要确定你的模型处于什么阶段,到底是欠拟合还是过拟合,然后再确定解决手段。
trick 11:badcase 分析问题
对于图像和nlp,效果一直不提高,可以尝试自己标注一些模型经常分错的case,然后加入训练会有奇效。