链载Ai
标题: 探索Graph RAG:知识图谱与大语言模型的智能融合! [打印本页]
作者: 链载Ai 时间: 2 小时前
标题: 探索Graph RAG:知识图谱与大语言模型的智能融合!
自然语言与知识图谱的交互已成为热门话题,备受瞩目。而且这一趋势将持续存在,并深刻改变我们所熟悉的计算机系统交互方式。而这一变革的起点,便是自然语言查询(NLQ),如今,人们纷纷渴望利用自己的数据提出自然语言问题。在企业中,直接运用现成的大型语言模型(LLM)聊天机器人进行问题解答往往收效甚微,因为它们缺乏针对特定领域和组织活动的专有知识,而这些知识恰恰能够为对话式信息提取接口带来真正的价值。正因如此,Graph RAG方法应运而生,它提供了一种理想的解决方案,能够定制化地调整LLM,以满足您的个性化需求。
检索增强生成(RAG)是一种新兴的自然语言查询技术,它通过引入外部知识来增强现有的大型语言模型(LLMs),使得在需要特定知识时,问题的答案更加精准和相关。RAG包含一个检索信息组件,它能够从外部源抓取额外的“锚定上下文”信息,这些信息随后被整合进LLM的提示中,以提升回答的准确性。这种方法以其低成本和标准化的特点,成为增强LLMs回答能力的首选方案。同时,RAG还显示出减少LLMs产生幻觉倾向的能力,因为它使生成的内容更加贴近可靠的上下文信息,从而提高了输出的可信度。正因如此,RAG已成为增强生成模型输出的最流行方式。RAG的应用不仅限于问答,它还广泛应用于自然语言处理的多个领域,包括文本信息提取、推荐、情感分析和摘要等任务。例如,当我们向LLM提出“谁是第一个登上月球的人?”这一问题时,LLM已经知道答案是“尼尔·阿姆斯特朗”。此时,RAG技术便发挥了其作用,它允许LLM访问外部资源,以获取更多关于尼尔·阿姆斯特朗的详细信息,比如他的生平、出生地以及他如何成为登月第一人的故事。通过这种方式,LLM能够生成一个包含更多细节和相关信息的更优质答案。在下图中,整个流程的起点是:接收用户的问题或提示。紧接着,计算机将这一查询转化为计算机能够理解的数值格式——嵌入。这些嵌入信息被高效地存储于向量数据库中,为下一步的检索工作打下基础。系统利用这些嵌入信息,对外部数据库进行精准搜索,寻找与问题紧密相关的信息。当这些信息被搜集齐全后,它们将被传递给大型语言模型(LLM),以生成更为精确和贴切的查询答案。这一过程不仅提高了信息检索的效率,也确保了答案的质量和相关性。要实现问题回答的Graph RAG,关键在于挑选合适的信息,发送给大型语言模型(LLM)。这一过程通常基于用户提问中的意图,通过查询数据库来完成。而最适合这一目的的,莫过于向量数据库,它们利用嵌入技术,在连续的向量空间中捕捉潜在的语义含义、句法结构以及项目间的联系。随后,系统会将用户的问题与预先选定的额外信息结合,形成一个丰富的提示,确保生成的答案能够综合考虑这些信息,从而提供更为精准和全面的回答。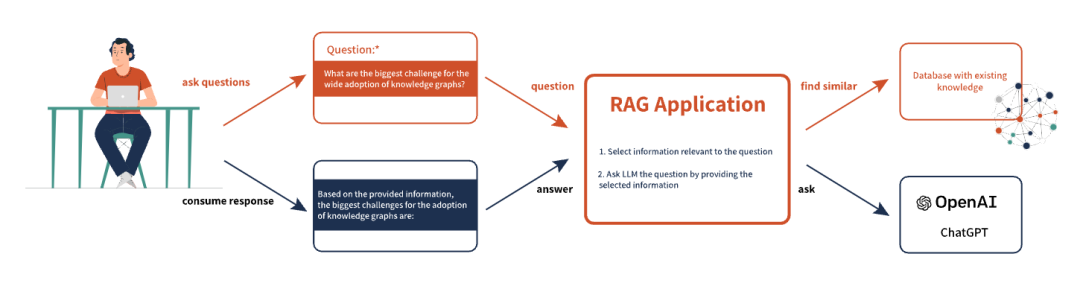
虽然Graph RAG的基本实现过程并不复杂,但要确保其输出结果的质量,我们必须面对并克服一系列挑战:
数据的质量和相关性是Graph RAG发挥作用的关键。我们必须深思熟虑,如何从海量信息中筛选出最贴合用户需求的内容,并决定向大型语言模型(LLM)发送多少信息,以确保其能够提供精准的反馈。
动态知识的处理往往颇具挑战,因为它要求我们持续不断地用最新数据更新向量索引。这一过程,尤其是在处理大规模数据时,可能会对系统的效率和可扩展性提出更高的要求。
生成结果的透明度对于建立用户对系统的信任至关重要。我们可以通过一些提示工程的技术,引导LLM在提供答案时解释所含信息的来源,从而使系统更加可靠、易于使用。
Graph RAG作为RAG方法的升级版,引入了图数据库作为向大型语言模型(LLM)提供上下文信息的新渠道。传统上,向LLM提供从大型文档中抽取的文本片段,可能因缺乏充分的上下文、事实准确性和语言精确性,而无法让LLM深入理解所接收的信息。Graph RAG的独到之处在于,它不仅能够向LLM提供文本信息,还能提供结构化的实体信息,将实体的描述与它的属性和关系一并呈现,激发LLM进行更深层次的分析和理解。通过Graph RAG,向量数据库中的每条记录都能获得丰富的上下文描述,这极大提升了特定术语的理解度,使得LLM能够更准确地把握专业领域的知识。此外,Graph RAG还能与标准的RAG方法相辅相成,融合图表示的结构性和准确性以及文本内容的广泛性,发挥出1+1>2的效果。我们可以根据不同的问题类型、领域特点以及现有知识图谱中的信息,概括出Graph RAG的几种应用形态:- 作为内容仓库的图(Graph as a Content Store):从文档中提取关键片段,让LLM据此作出回答。这一形态要求知识图谱(KG)中包含与问题相关的文本内容及其元数据,并且需要与向量数据库实现无缝对接。
- 作为领域专家的图(Graph as а Subject Matter Expert):提取与自然语言(NL)问题相关的概念和实体描述,并将这些信息作为额外的“语义上下文”提供给LLM。理想情况下,这些描述应涵盖概念间的相互联系。这一形态要求知识图谱具备全面的概念模型,涵盖相关的本体论、分类体系或其他实体描述,并需要通过实体链接或其他机制来识别与问题相关的各种概念。
- 作为数据库的图(Graph as a Database):将自然语言问题的部分内容转化为图查询,执行查询后让LLM对结果进行总结。这一形态要求图谱中存储有相关的实际信息。实现这种模式,需要一种能够将自然语言转换为图查询的工具,以及进行实体链接的技术。

向量数据库是一处专门用来存储和处理非结构化数据,例如文本、图像、音频等,将其转化为高维的向量嵌入形式。这些向量嵌入能够捕捉数据点之间的语义联系。如此一来,RAG便能够识别并检索出意义相近的向量,而不再依赖于关键词匹配进行搜索。向量数据库的显著优势在于其处理海量数据的能力,以及快速提取最相关信息的速度。然而,它也存在局限,即在将信息转化为向量的过程中可能会丢失一些上下文和细节,这可能会影响到搜索的准确性和所需时间。知识图谱与向量数据库有所区别,它采用节点和边的方式来表示数据,构建起一个庞大的、相互连接的网络来存储和管理信息。在这个网络中,节点代表实体,边则代表实体之间的关系。除此之外,知识图谱还拥有属性的概念,它能够为实体提供额外的详细信息。例如,在某个图像中,实体“牛”可能就拥有“身高”、“体重”、“性别”等属性。
结构化数据与关系:当需要管理和利用结构化数据实体之间的复杂关系时,请使用知识图谱。知识图谱非常适合于数据点之间的相互联系与数据点本身同等重要的场景。
特定领域应用:对于需要深入、特定领域知识的应用,知识图谱尤其有用。它们能够有效地表示医学、法律或工程等领域的专业知识。
可解释性和可追溯性:如果你的应用需要高度的可解释性(即,理解如何得出结论),知识图谱提供了更透明的推理路径。
数据完整性和一致性:知识图谱维护数据完整性,并且在数据表示的一致性至关重要时非常合适。
- 非结构化数据:面对大量非结构化数据,如文本、图像或音频,向量数据库是理想的选择。它们在捕捉这类数据的语义含义方面尤为有效。
- 可扩展性和速度:对于需要高可扩展性和从大型数据集中快速检索的应用,向量数据库更为合适。它们能够基于向量相似性迅速获取相关信息。
- 数据建模的灵活性:如果数据缺乏明确定义的结构,或者您需要灵活性以轻松整合不同类型的数据,向量数据库可能更为合适。
- 与机器学习模型的集成:向量数据库常与机器学习模型一起使用,特别是那些操作数据嵌入或向量表示的模型。
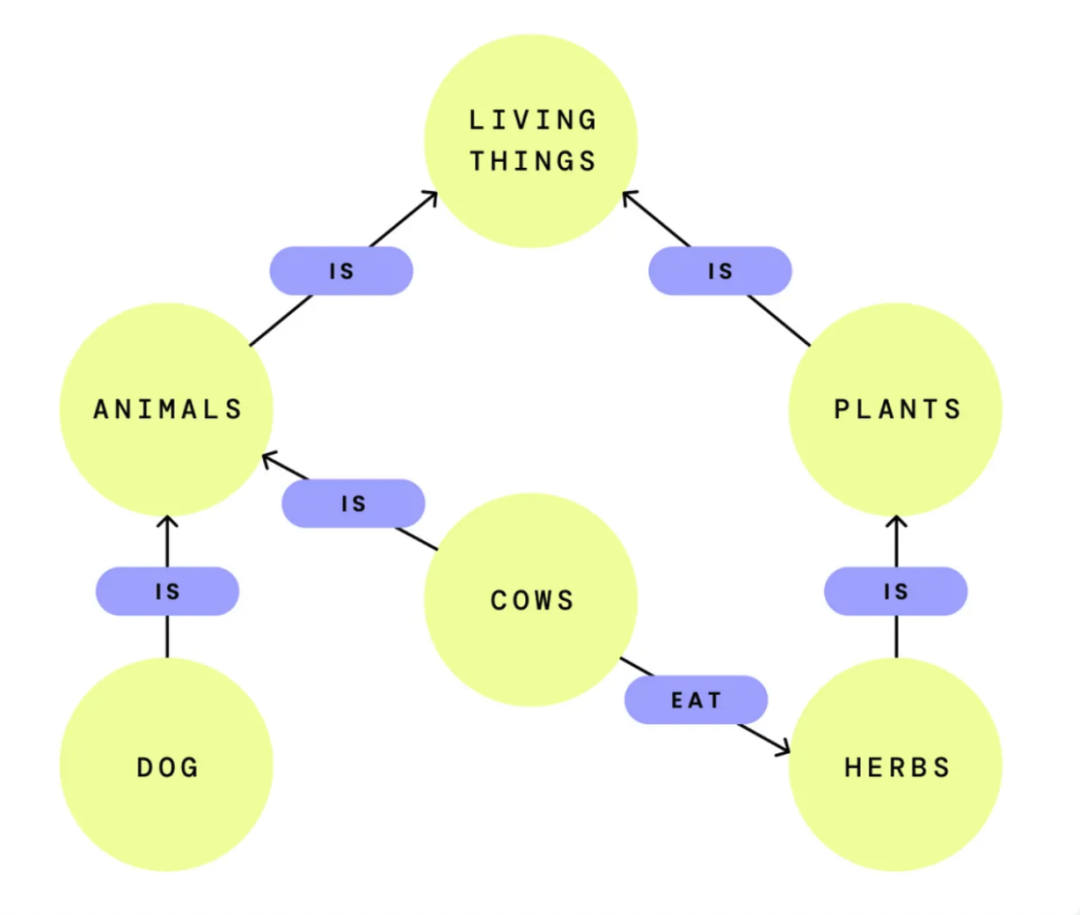
知识图谱(KG)的显著优势在于其强大的理解和解释能力。当RAG系统访问知识图谱中的某个节点时,它能够追踪到与该节点相连的周边节点以及它们之间的关系,从而呈现出一个宏观视角,并提供更多具有价值的相关信息,帮助系统实现更深层次的理解。例如,在解释“森林砍伐的影响”时,Graph RAG相较于传统的RAG,能够提供更加详尽和高效的信息。然而,知识图谱也有其局限性。构建和维护这样一个图谱,其复杂性和成本都远高于向量数据库。这需要投入大量的资源和技术,以确保图谱的准确性和实时更新。
| 欢迎光临 链载Ai (https://www.lianzai.com/) |
Powered by Discuz! X3.5 |