链载Ai
标题: MinerU | 上海AI lab 开源的pdf内容提取工程 [打印本页]
作者: 链载Ai 时间: 前天 10:46
标题: MinerU | 上海AI lab 开源的pdf内容提取工程
MinerU 是一款一站式、开源、高质量的数据提取工具,主要包含以下功能:
Magic-PDFPDF文档提取
Magic-Doc网页与电子书提取
- ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;letter-spacing: 0.5px;text-align: start;background-color: rgb(255, 255, 255);line-height: 1.75em;white-space-collapse: preserve !important;word-break: break-word !important;">ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;letter-spacing: 0.5px;text-align: start;background-color: rgb(255, 255, 255);line-height: 1.75em;white-space-collapse: preserve !important;word-break: break-word !important;">项目地址:https://github.com/opendatalab/MinerU
Magic-PDF 是一款将 PDF 转化为 markdown 格式的工具。支持转换本地文档或者位于支持S3协议对象存储上的文件。
 ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;white-space-collapse: preserve;letter-spacing: 0.578px;text-align: center;"/>
ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;white-space-collapse: preserve;letter-spacing: 0.578px;text-align: center;"/>Magic-PDF框架示意图
主要功能包含
支持多种前端模型输入
删除页眉、页脚、脚注、页码等元素
符合人类阅读顺序的排版格式
保留原文档的结构和格式,包括标题、段落、列表等
提取图像和表格并在markdown中展示
将公式转换成latex
乱码PDF自动识别并转换
支持cpu和gpu环境
支持windows/linux/mac平台

ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: start;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);text-align: justify;">可以看到这里面最核心的部分是基于模型的解析模块:PDF-Extract-Kit而根据官方链接介绍的PDF-Extract-Kit包括以下几个模块:
布局检测:使用LayoutLMv3模型进行区域检测,如图像,表格,标题,文本等,由于文档类型的多样性,现有开源的布局检测和公式检测很难处理多样性的PDF文档,为此作者团队采集多样性数据进行标注和训练,使得在各类文档上取得精准的检测效果;
公式检测:使用YOLOv8进行公式检测,包含行内公式和行间公式;
公式识别:使用UniMERNet进行公式识别,这个方法是上海AI lab前段时间开源的公式识别模型,作者自己说法是可以媲美商业软件,在各种类型公式识别上均匀很高的质量,实际体验效果确实不错,;
光学字符识别:使用PaddleOCR进行文本识别;
ingFang SC", miui, "Hiragino Sans GB", "Microsoft Yahei", sans-serif;font-size: 14px;letter-spacing: 0.5px;text-align: start;background-color: rgb(255, 255, 255);white-space-collapse: preserve !important;word-break: break-word !important;">ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);text-align: justify;">流程图如下:
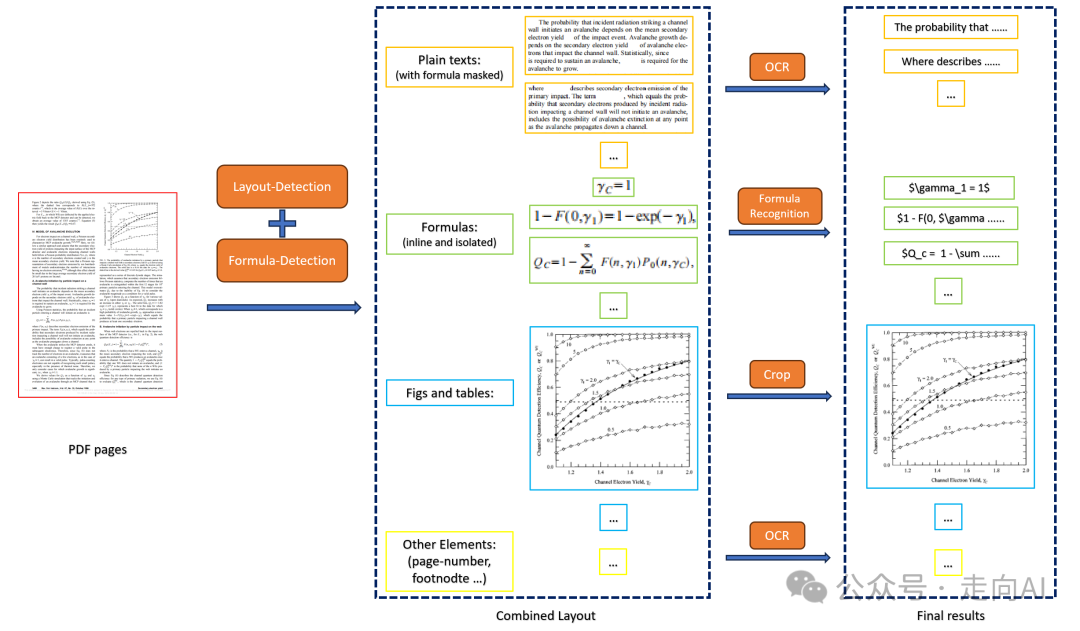
PDF-Extract-Kit流程图
ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;letter-spacing: 2px;text-align: left;background-color: rgb(255, 255, 255);line-height: 1.75em;">Magic-DocMagic-Doc 是一款支持将网页或多格式电子书转换为 markdown 格式的工具。
主要功能包含
ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;letter-spacing: 2px;text-align: left;background-color: rgb(255, 255, 255);line-height: 1.75em;">点评这里只点评PDF文档解析相关部分,因为 Docx / Html / epub / mobi 转 markdown 是一个纯工程问题,不涉及算法识别,不做评论。
根据上面PDF-Extract-Kit的流程图可知,本项目的流程与我之前写的PDF文档解析流程(突破大语言模型语料瓶颈:如何从专业PDF文件中挖掘高质量数据)有两个区别:
- 版式布局检测标签不包含公式:而是用了一个单独的公式检测模型,用于检测行间公式和行内公式,注意:这里的公式有两个标签。正是因为公式有两种标签,导致后面需要复杂的后处理逻辑将基于PaddleOCR识别的行文本与行内公式识别结果拼接成正确的结果;
- 没有阅读顺序模块:这也是导致这个开源工程严重依赖后处理模块的原因,看作者的框架图写到了阅读顺序(layout 顺序)模块正在开发中,说明他们也意识到了这个问题。没有阅读顺序的话,一方面需要通过各种规则后处理来得到输出顺序,另一方面文档版式非常复杂,可以想象一下报纸、杂志的版式,多栏混合排列,靠规则是无法解决这类文档的输出顺序的。
整体上看,这个开源工程相比之前推荐过的开源项目Marker(历史专业出身的开发者开源Marker狂揽8.2K star),增强了版式布局检测和公式识别能力和文本识别能力,可以推荐用于一般的PDF文档解析使用工具,比如常见的单栏双栏文档。
| 欢迎光临 链载Ai (https://www.lianzai.com/) |
Powered by Discuz! X3.5 |