链载Ai
标题: RAGChecker为你的RAG系统提供全方位诊断 [打印本页]
作者: 链载Ai 时间: 昨天 11:08
标题: RAGChecker为你的RAG系统提供全方位诊断
由于RAG系统的模块化特性、对长文本响应的评估需求以及现有评估指标的可靠性不足,对RAG系统进行全面评估存在挑战。
亚马逊AWS AI开源了RAGChecker,一个基于声明级别蕴含性检查的细粒度评估框架,涉及从响应和真实答案中提取声明并与其他文本对照。
RAGCHECKER中提出的指标的说明。上面的维恩图展示了模型响应与真实答案之间的比较,显示了可能的正确(O)、错误(X)和缺失的声明(V)。检索到的块根据它们包含的声明类型被分类为两类。下面,定义了整体、检索器和生成器的指标,说明了如何评估RAG系统的每个组件的性能。
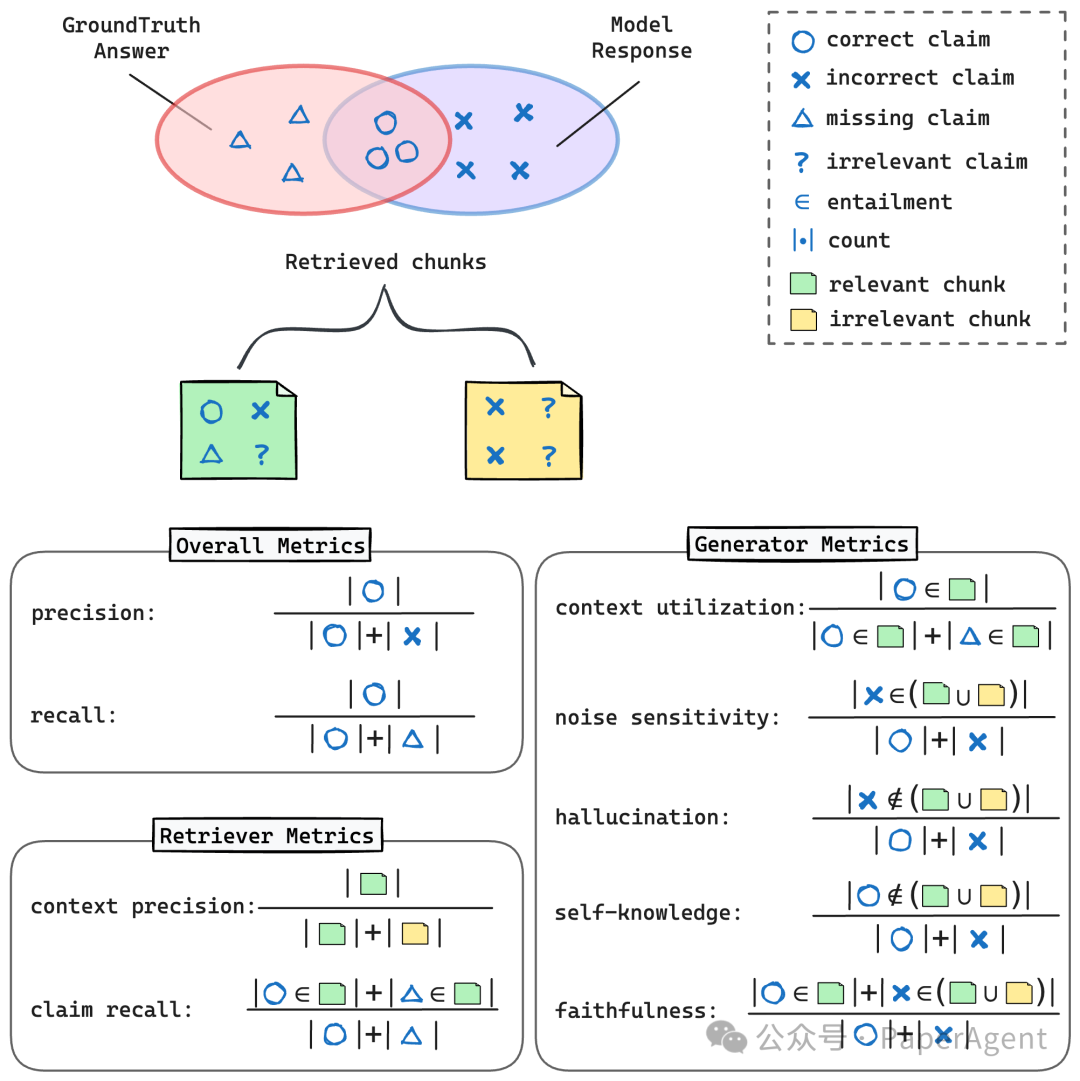
RAGChecker使开发者和研究人员能够精确深入地全面评估、诊断和增强他们的RAG系统:- 全面评估:RAGChecker提供整体指标,用于评估整个RAG流程。
- 诊断指标:用于分析检索组件的诊断检索器指标。用于评估生成组件的诊断生成器指标。这些指标为针对性改进提供了有价值的见解。
- 细粒度评估:利用声明级别的蕴含操作进行细粒度评估。
- 基准数据集:一个包含4000个问题、涵盖10个领域的全面的RAG基准数据集(即将推出)。
- 元评估:一个用于评估RAGChecker结果与人类判断相关性的人工标注偏好数据集。
通过在10个领域的公共数据集上对8个最先进的RAG系统进行综合实验,RAGCHECKER显示出与人类评估者有更强的相关性,并提供了关于RAG系统组件行为和设计中固有权衡的深刻见解。RAG基准统计信息。此基准测试是从涵盖10个领域的公共数据集中重新调整用途构建的,包含4,162个问题。对于财务、生活方式、娱乐、科技、科学和小说到领域的数据,简短的答案已使用GPT-4扩展为长篇答案。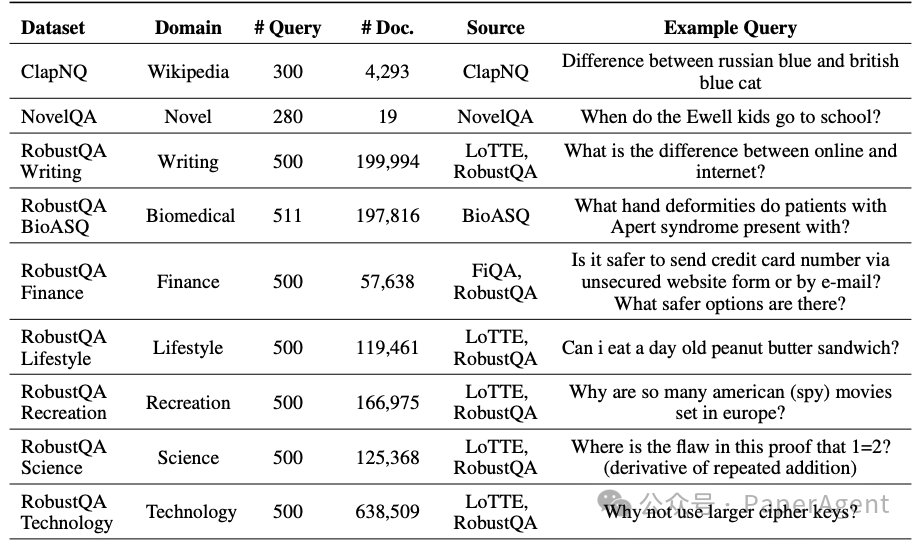
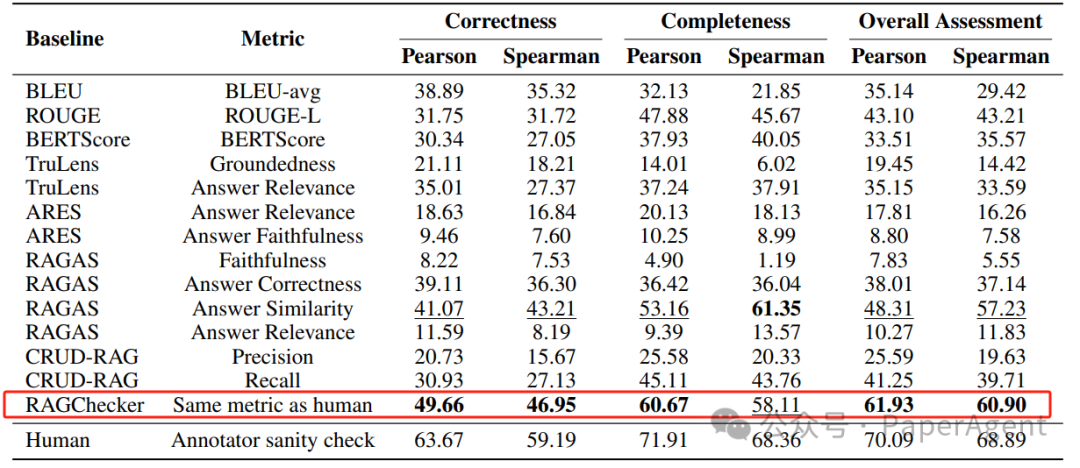
与人类评估的正确性、完整性和整体评估的相关性结果。展示了每个基线框架(TruLens、RAGAS、ARES、CRUD-RAG)相关指标。
RAGCHECKER的指标可以帮助研究人员和实践者开发更有效的RAG系统,并通过调整RAG系统的设置(如检索器的数量、块大小、块重叠比例和生成提示)来提供改进建议。
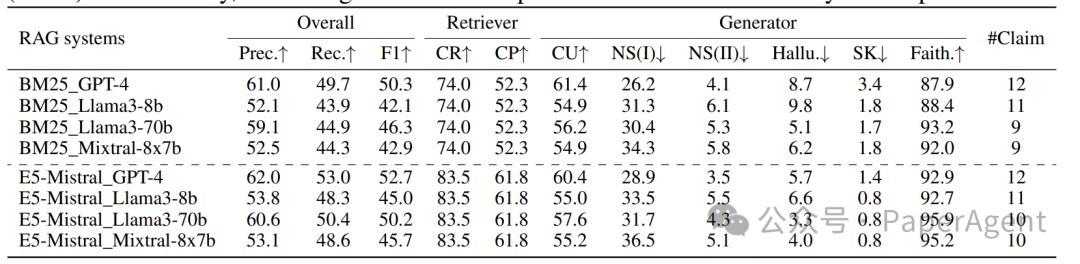
不同RAG系统在10个数据集上的平均评估结果。使用精确度(Prec.)、召回率(Rec.)和F1分数来量化RAG系统的整体性能。检索器组件基于声明召回率(CR)和上下文精确度(CP)进行评估,而生成器组件则通过上下文利用度(CU)、相关噪声敏感性(NS(I))、不相关噪声敏感性(NS(II))、幻觉(Hallu.)、自我知识(SK)和忠实度(Faith.)进行诊断。此外,还提供了每个RAG系统的平均响应声明数量。
RAGCHECKER和RAGAS答案相似性预测分数分布的比较。图中的每个点代表元评估数据集中的一个实例,其中x轴是相应方面的人类偏好标签,y轴是RAGCHECKER和RAGAS答案相似性的预测分数。预测分数的分布由彩色区域表示,虚线是平均线。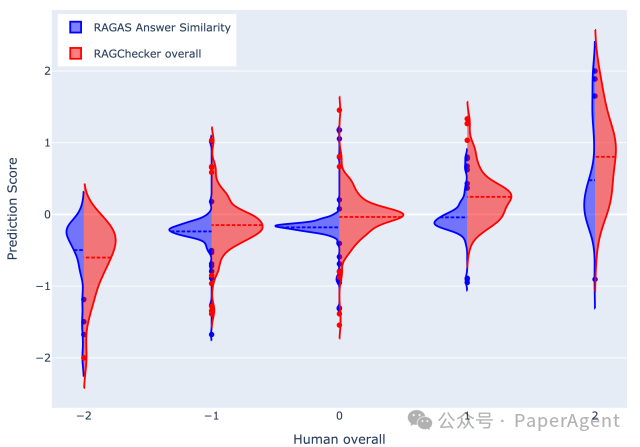
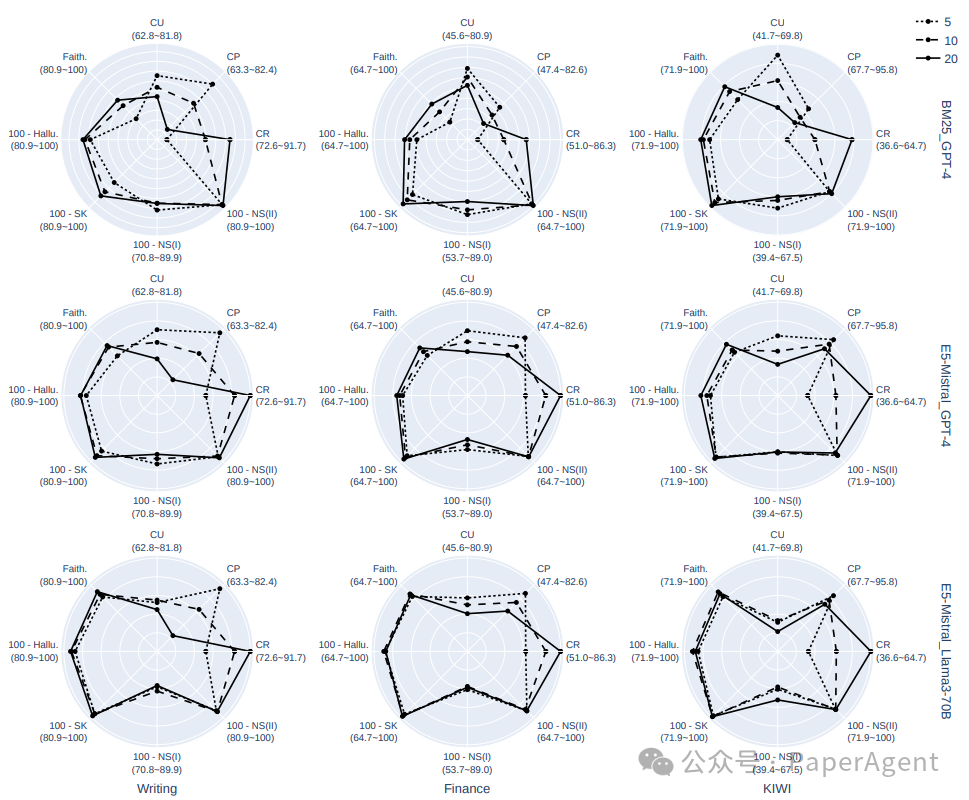
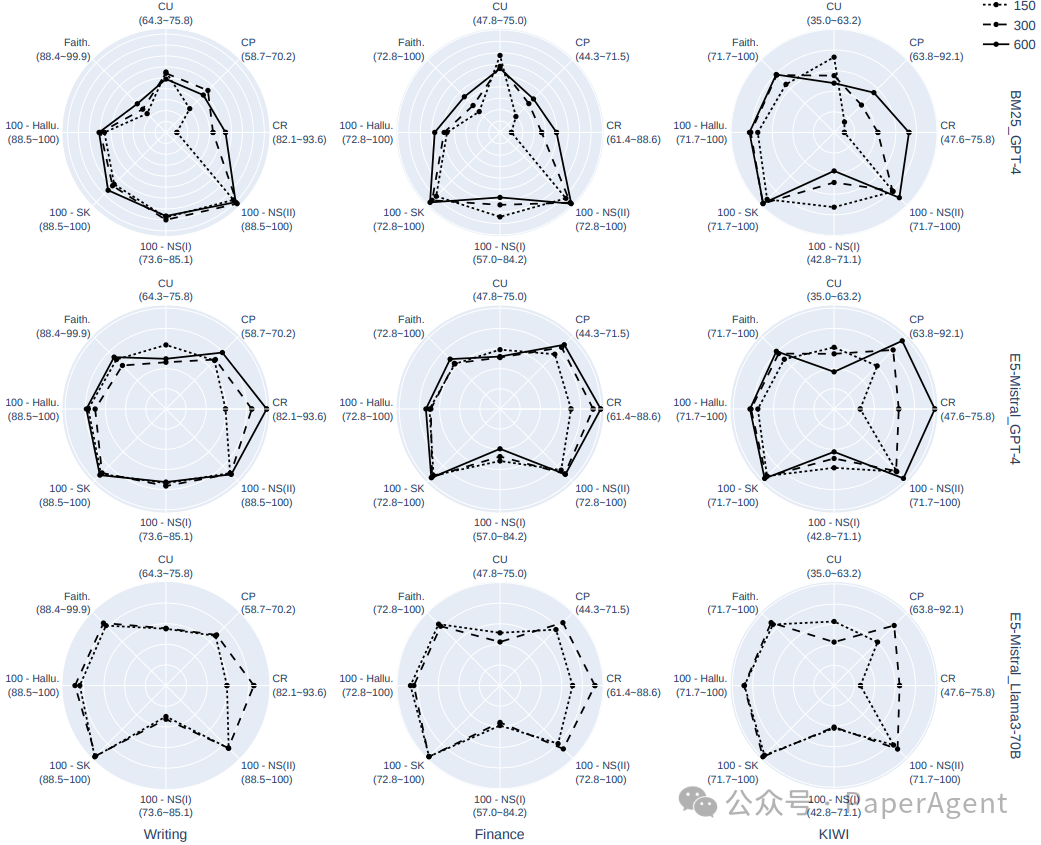
Top-k选择和片段大小都平衡了呈现给生成器的噪声量和有用信息量,但方式不同。相应的结果在下面两张图中展示。- 增加k会增加可能不太相关的更多上下文,而增加片段大小则提供了更多相关事实的周围上下文。因此,随着k的增大,上下文精确度会降低,但随着片段大小的增大而提高。尽管如此,它们都会导致检索中更好的声明召回率。
- 生成器在提供更多上下文时往往更加忠实,尽管这一趋势对于Llama3来说不太明显,因为它已经表现出很高的忠实度。由于噪声的增加,上下文利用度通常随着更多上下文而恶化,导致更高的相关噪声敏感性。
- 端到端的RAG性能在更多上下文的情况下略好,主要是由于召回率的提高。建议适度增加这两个参数以实现更忠实的生成,同时要注意在高值时会出现饱和,因为有用信息的数量是有限的。在上下文长度有限的情况下,更倾向于选择较大的片段大小和较小的k,特别是对于较容易的数据集(金融、写作)。这在比较片段大小为150且k=20与片段大小为300且k=10时尤为明显。
片段大小的诊断
https://arxiv.org/pdf/2408.08067RAGCHECKER:AFine-grainedFrameworkforDiagnosingRetrieval-AugmentedGenerationhttps://github.com/amazon-science/RAGChecker
| 欢迎光临 链载Ai (https://www.lianzai.com/) |
Powered by Discuz! X3.5 |