链载Ai
标题: 万字长文:OpenAI 发展史 [打印本页]
作者: 链载Ai 时间: 8 小时前
标题: 万字长文:OpenAI 发展史
在这篇文章正式开始前,我想先给个相关阅读,主要是我也没想到《OpenAI 系列》我已经写这么多内容。写得越多,了解越深,感慨也越多。在公司早期可以聚集一批顶尖天才去做一件结果未知的事情,真的很酷,虽然随着公司的发展,大家的分歧越来越大,只能通过离开这种方式来解决(聚是一团火,散是满天星)。但不管 OpenAI 未来如何,都衷心祝福它可以渡过难关,因为它对全人类的贡献是有目共睹的(算是为数不多的真正在通过技术改变世界的公司了,尤其是将冷冰冰的论文转化为可供普通人使用的产品)。话又说回来,OpenAI 过早宣传还在开发中的半成品的毛病真该改改,Sora 和 SearchGPT 到现在还没个影,上线的高级语音也是个阉割版。
一文读懂 OpenAI
OpenAI 大地震:Sam Altman 和 Greg Brockman 离职,微软加强与 OpenAI 合作!
没有员工,OpenAI 什么也不是!
Sam 重回 OpenAI,Q-star 被曝光!
AGI 里程碑:OpenAI Sora 从文字图像到视频
OpenAI 发布 Elon Musk 起诉事件公告
OpenAI 审核完毕,董事会扩充!ChatGPT 发不出消息怎么办?
GPT-4o:OpenAI 发布最强人机交互模型
OpenAI 首席科学家 Ilya 宣布离职
OpenAI 生态布局:GPT-4o 免费或许只是一个开始...
SearchGPT:OpenAI 内测 AI 搜索引擎
OpenAI o1 模型:AI 复杂推理新突破
OpenAI o1:使用限额提高,o1 模型深度解析
短短半个月,OpenAI 发生的事情有点多:从 o1 模型发布、Sam 小作文、高级语音、再到多名高管离职(? 难道是 AGI 真的要来了,需要通过这种方式来减缓 AI 的进化吗?)。以下是整理的最新推文事件线,Mira、Bob 和 Barret 相继离职,Sam 发了一条通知,在表示伤心难过之余,还宣布了公司最新任命:
我刚刚向 OpenAI 发布了这条通知:
大家好——
在过去的 6.5 年里,Mira 对 OpenAI 的进步和成长发挥了关键作用;她是我们从一个不知名的研究实验室发展为重要公司的重要因素。
今天早上,Mira 告诉我她要离开,我很难过,但支持她的决定。在过去的一年中,她一直在培养强大的领导班子,以确保我们持续进步。
我还想分享的是,Bob 和 Barret 也决定离开 OpenAI。Mira、Bob 和 Barret 都是独立做出这个决定的,且都是友好的。但 Mira 的决定时机使得一次性处理这一切显得合适,这样我们可以一起努力,确保顺利交接给下一代领导。
我非常感激他们的贡献。
在 OpenAI 担任领导职务是全身心投入的。一方面,能够建立 AGI 并成为发展最快的公司,将我们的先进研究成果交付给数亿人,是一种荣幸。另一方面,带领团队应对这一切是极具挑战的,他们为公司付出了超出职责的努力。
Mark 将成为我们的新研究高级副总裁,并将与首席科学家 Jakub 合作领导研究团队。这是我们长期以来为 Bob 准备的接班计划;虽然这一变化比预期来得更早,但我对 Mark 接任这个角色感到非常兴奋。Mark 不仅具备深厚的技术专长,过去几年他也以令人印象深刻的方式学会了如何成为一个领导者和管理者。
Josh Achiam 将担任新的使命协调负责人,跨部门工作,以确保我们在文化和各个方面都能顺利实现我们的使命。
Kevin 和 Srinivas 将继续领导应用团队。
Matt Knight 将担任我们的首席信息安全官,已经在这个职位上工作了很长时间。这是我们早就有的计划。
Mark、Jakub、Kevin、Srinivas、Matt 和 Josh 将向我汇报。过去一年多,我主要专注于我们组织的非技术部分;现在我期待更多地投入到公司的技术和产品部分。
今晚,我们将在 575 号楼聚会,从下午 5:30 开始。Mira、Bob、Barret 和 Mark 都会在场。这将是一次表达感激和反思我们共同成就的机会。明天,我们将举行全员大会,届时可以回答任何问题。日历邀请会很快发出。
领导层的变动是公司的自然部分,尤其是像我们这样快速成长、要求严格的公司。我显然不会假装这样的变化是自然的,但我们并不是一家普通公司,我认为 Mira 向我解释的原因(没有好时机,任何非突发的变动都可能泄露消息,而她希望在 OpenAI 上升期进行变动)是合理的。明天的全员大会上,我们可以进一步讨论这个问题。
感谢大家的辛勤工作和奉献。
Sam
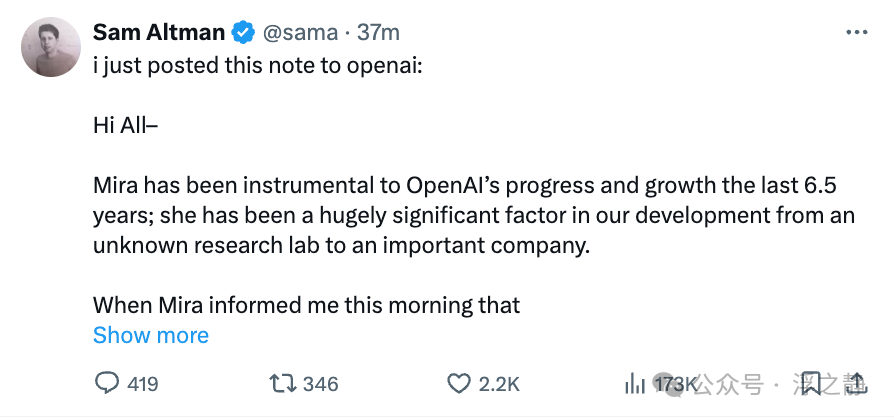
我今天与 OpenAI 团队分享了以下说明。
大家好,
我有一件事想要和大家分享。经过深思熟虑,我做出了离开 OpenAI 的艰难决定。
与 OpenAI 团队共度的六年半时光对我来说是非凡的荣耀。在接下来的日子里,我会对许多人表达我的感激之情,但我想先感谢 Sam 和 Greg,感谢他们信任我领导技术团队,并在这些年里给予了我支持。
永远没有一个理想的时刻去离开一个自己珍视的地方,但此刻感觉是对的。我们最近发布的语音到语音和 OpenAI o1 标志着交互和智能领域新时代的开始——这些成就得益于你们的创造力和精湛技艺。我们不仅仅是构建了更智能的模型,我们从根本上改变了 AI 系统如何通过复杂问题进行学习和推理。我们将安全研究从理论领域带入实际应用,创建了比以往更具鲁棒性(robust)、对齐性(aligned)和可控性(steerable)的模型。我们的工作使前沿的 AI 研究变得直观和易于访问,开发出能够根据每个人的输入进行适应和进化的技术。这些成功是我们杰出团队合作的证明,正是因为你们的才华、奉献和承诺,OpenAI 才能站在 AI 创新的顶峰。
我选择离开是因为我想为自己创造时间和空间去探索。现在,我的首要任务是尽我所能确保平稳过渡,保持我们已经建立的势头。
我将永远感激能够与这样一个非凡的团队一起建设和工作的机会。我们共同推动了科学认知的边界,致力于改善人类福祉。虽然我可能不再与你们并肩作战,但我依然会为你们加油。
怀着对友谊、成就,尤其是我们共同克服的挑战的深深感激之情,
Mira (注:Mira 曾任职 OpenAI CTO)
我回复了这条信息。Mira,谢谢你所做的一切。
很难用语言形容 Mira 对 OpenAI、我们的使命以及我们每个人的重要性。
我对她帮助我们建立和完成的一切充满感激之情,但我最感激的是她在所有艰难时刻给予的支持和关爱。我很期待她接下来的成就。
我们很快会详细说明过渡计划,但此刻,我只想表达感激之情。
Sam
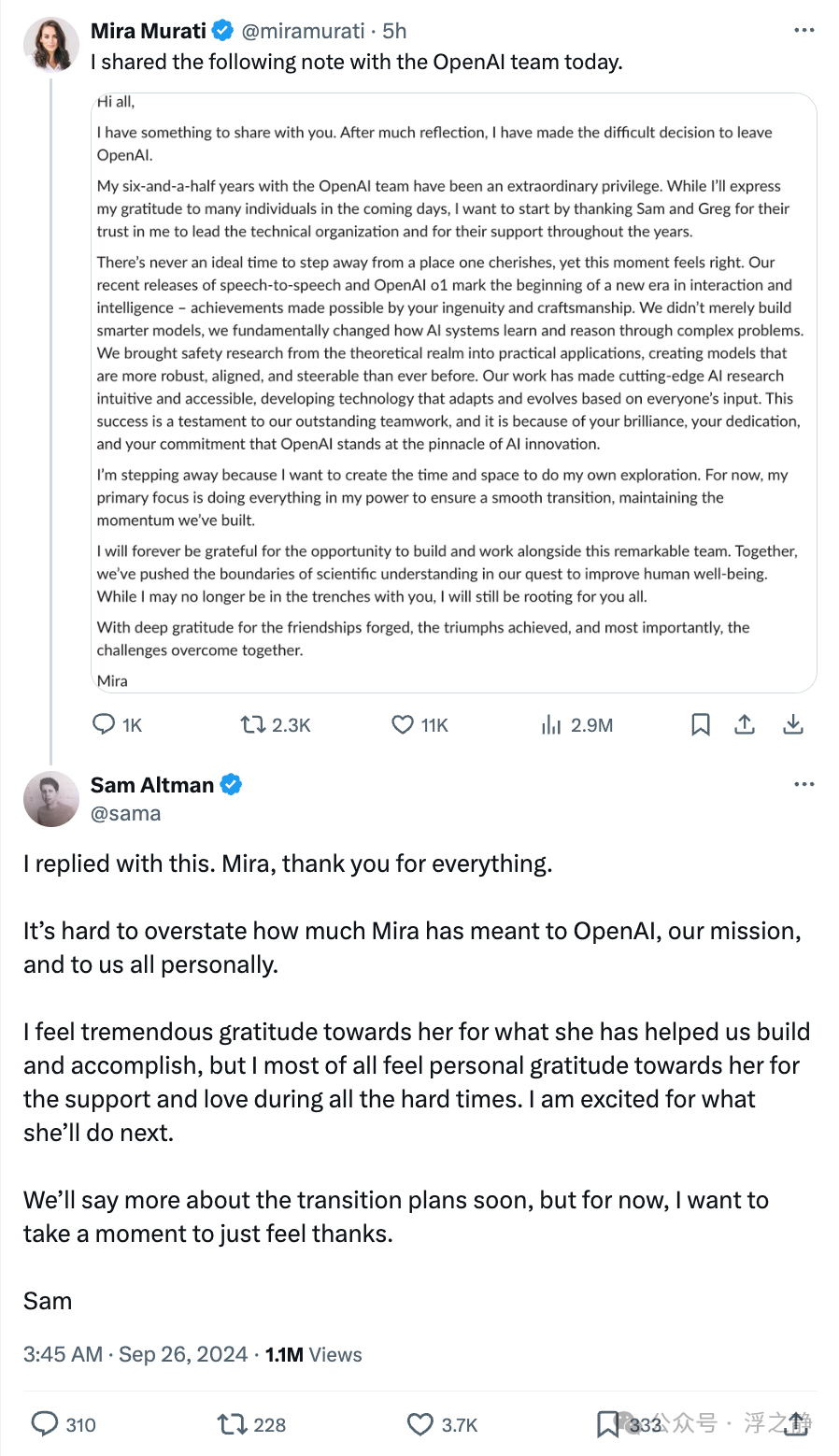
我刚刚与 OpenAI 分享了这个:
过去的八年在 OpenAI 的经历让我感到谦卑和敬畏。我在 2017 年 1 月加入的那个小型非营利组织,如今已成为全球最重要的研究与部署公司。
我非常享受与一群才华横溢、全心投入的同事们一起工作——全世界没有任何地方能与之相比。我为我们研究团队这些年来的工作感到无比自豪,从早期在强化学习(RL)方面的成就,到开创大型语言模型(LLM),再到构建首个多模态生成模型,最终通过 ChatGPT 改变了世界。
现在是时候让我休息一下了。没有比推出 o1 给世界更好的方式来结束我在这里的工作了。
展望未来,Mark Chen 将担任高级副总裁,领导研究团队,Jakub 将继续担任首席科学家。我将在未来两个月内继续支持 Mark、Jakub 和团队完成过渡。我对他们的领导充满信心,他们将引领 OpenAI 的研究迈向 AGI 及更远的未来。我迫不及待想看到这个团队接下来会做些什么。
注:Bob McGrew 曾任职 OpenAI 首席研究官 (Chief Research Officer)
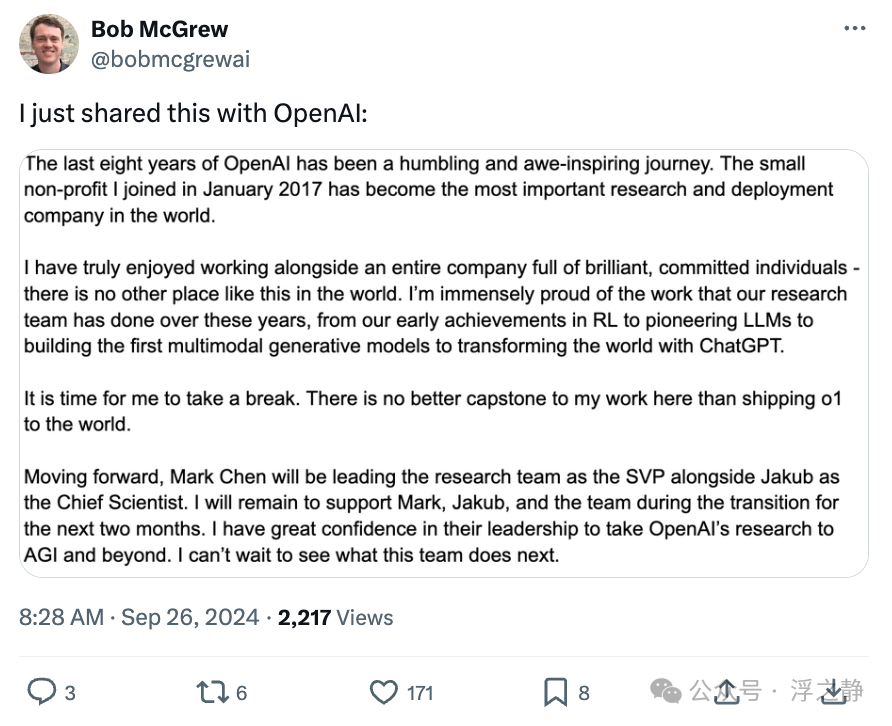
我在 OpenAI 发布了这条通知。
大家好,我决定离开 OpenAI。
做出这个决定非常困难,因为我在 OpenAI 的时光是如此美好。在 ChatGPT 推出之前我加入了团队,并与 John Schulman 及其他人一起从零开始建立了后训练团队。我非常感激能够有机会领导后训练团队,并帮助 ChatGPT 发展壮大至今天的规模。现在我觉得是时候在 OpenAI 之外探索新的机会了。这是基于我个人职业生涯下一阶段发展的选择。
我非常感激 OpenAI 为我提供的所有机会,以及从 OpenAI 领导层(如 Sam 和 Greg)那里得到的所有支持。尤其感谢 Bob 在我 OpenAI 职业生涯中给予的一切,他一直是出色的经理和同事。后训练团队中有许多优秀的领导者,我相信他们能够很好地接手工作。
OpenAI 正在做出并将继续做出令人难以置信的工作,我对公司的未来充满乐观,并会一直为大家加油。
注:Barret Zoph 曾任职 OpenAI 研究副总裁 (VP Research (Post-Training))
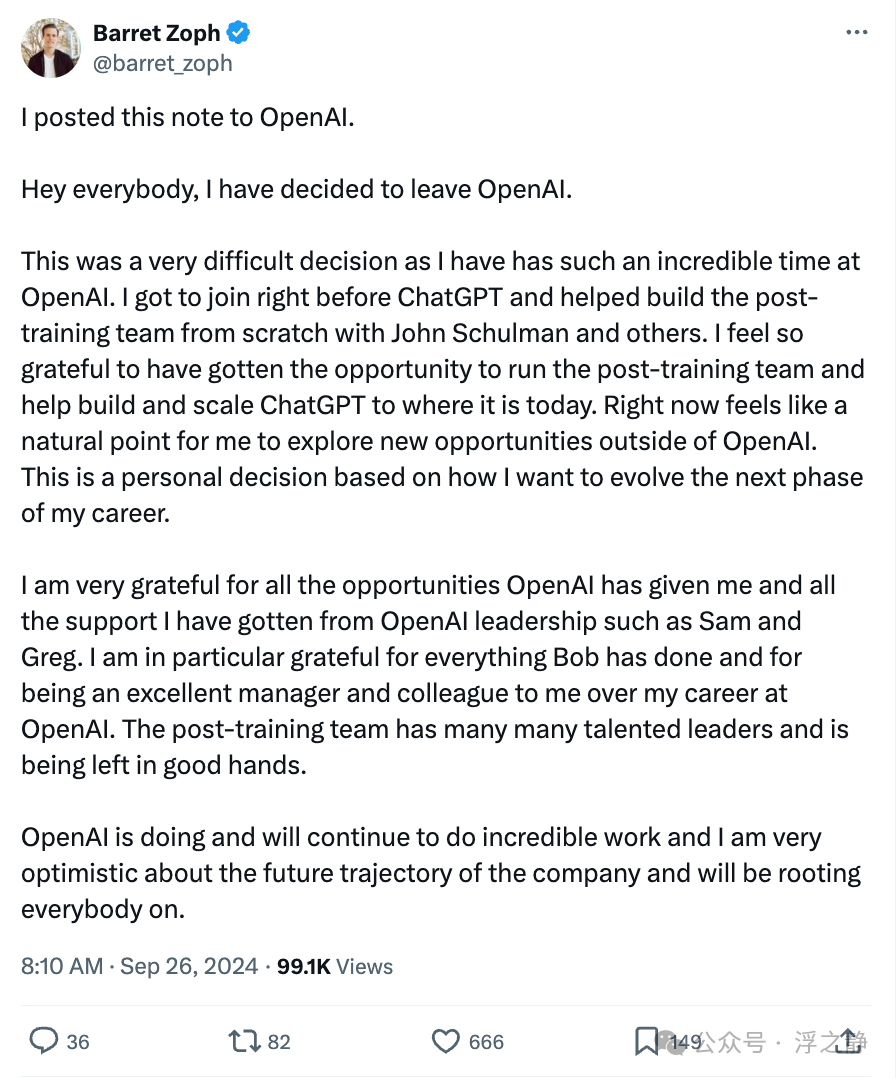
OpenAI 宫斗剧
OpenAI 的发展史堪比一部史诗般的宫斗剧,为了让大家有更加直观的感受,我整理了 OpenAI 自创立之初的关键事件线(关键人员变动均采用红色字体):
OpenAI 主要成就
强化学习
在其创立初期,OpenAI 的研究包含了许多专注于强化学习(RL)的项目。OpenAI 被视为 DeepMind 的重要竞争对手。
Gym
2016 年发布的 Gym[8] 是一个开源的 Python 库,旨在促进强化学习算法的开发。它的目标是标准化 AI 研究中环境的定义,使发布的研究更容易复现,同时为用户提供一个简单的接口来与这些环境进行交互。到 2022 年,Gym 的后续开发已转移到名为 Gymnasium[9] 的库中。
Gym Retro
2018 年发布的 Gym Retro[10] 是一个用于视频游戏强化学习(RL)研究的平台,使用 RL 算法研究泛化能力。此前的 RL 研究主要集中在优化智能体解决单一任务的能力上。Gym Retro 允许智能体在概念相似但外观不同的游戏之间进行泛化。
RoboSumo
2017 年发布的 RoboSumo[11] 是一个虚拟世界,元学习的类人机器人智能体最初连走路的知识都没有,但被赋予学习移动和将对方推出赛场的目标。通过这种对抗性学习过程,智能体学会了适应变化的条件。当智能体被从这个虚拟环境移出并放置到一个有强风的新虚拟环境中时,智能体会调整姿势保持站立,这表明它已经学会了如何在一般情况下保持平衡。OpenAI 的 Igor Mordatch 认为,智能体之间的竞争可以创造一种智能的“军备竞赛”,这可以增强智能体在竞争环境之外的功能。
OpenAI Five
OpenAI Five[12] 是由五个 OpenAI 策划的机器人组成的团队,用于五对五的竞技类游戏《Dota 2》,这些机器人通过试错算法学习与人类玩家进行高水平比赛。首次公开演示是在 2017 年的《Dota 2》国际邀请赛上,乌克兰职业选手 Dendi 在现场一对一比赛中输给了机器人。赛后,CTO Greg Brockman 解释说,这个机器人通过与自己对战两周时间学会了技能,并表示该学习软件朝着处理复杂任务(如外科手术)的方向迈进了一步。该系统使用了一种强化学习形式,机器人通过每天数百次自我对战的方式进行数月学习,并为击杀敌人和占领地图目标等行为奖励积分。
到 2018 年 6 月,机器人能够组成一个五人完整团队,并击败了业余和半职业玩家团队。在 2018 年的国际邀请赛上,OpenAI Five 与职业选手进行了两场表演赛,但都输了。2019 年 4 月,OpenAI Five 在旧金山的一场现场表演赛中以 2:0 击败了当时的世界冠军队伍 OG。该机器人团队最后一次公开亮相是在同年稍晚的在线公开赛中,他们在四天内共进行了 42,729 场比赛,赢得了 99.4% 的胜利。
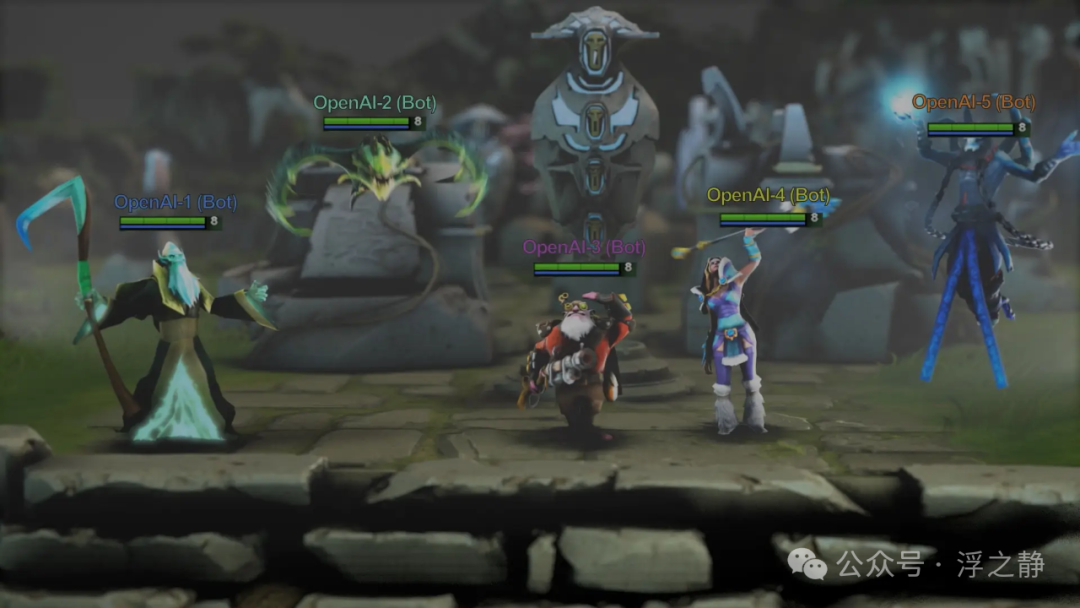
OpenAI Five 在《Dota 2》中的表现展示了 AI 系统在多人在线战术竞技游戏中的挑战,以及 OpenAI Five 如何通过深度强化学习(DRL)智能体在《Dota 2》比赛中实现超人水平的能力。
Dactyl
Dactyl[13] 于 2018 年开发,使用机器学习训练一只 Shadow Hand(类人机器人手)操纵物体。它完全通过仿真使用与 OpenAI Five 相同的 RL 算法和训练代码进行学习。OpenAI 通过使用领域随机化解决了物体定向问题,这是一种让学习者接触各种经验的仿真方法,而不是试图与现实情况相匹配。Dactyl 的设置除了有运动跟踪摄像头,还配备了 RGB 摄像头,允许机器人通过视觉操纵任意物体。2018 年,OpenAI 展示了该系统能够操纵一个立方体和一个八角棱柱体。
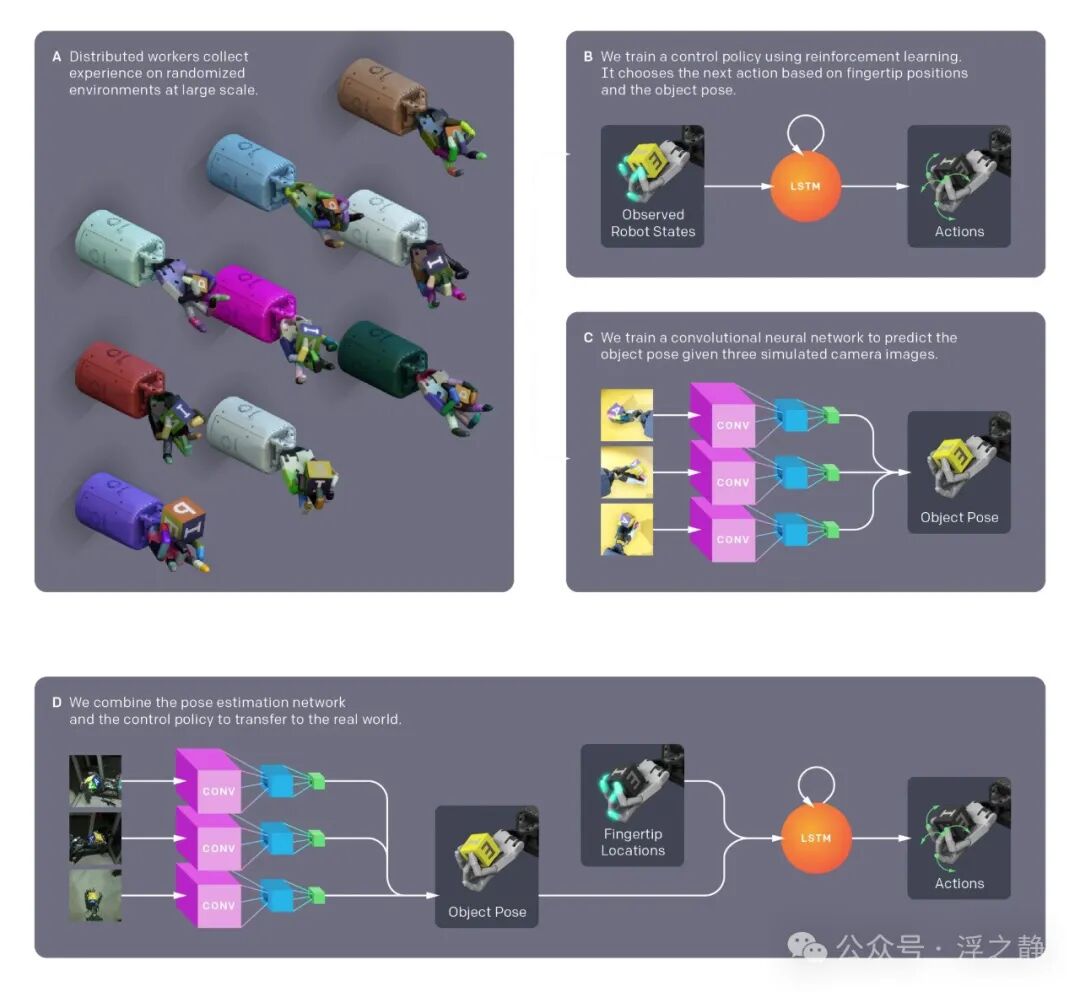
2019 年,OpenAI 展示了 Dactyl 能够解开魔方的能力。机器人能在 60% 的情况下成功解开魔方。像魔方这样的物体引入了复杂的物理问题,这些问题难以建模。OpenAI 通过使用自动领域随机化(ADR)增强了 Dactyl 应对干扰的鲁棒性,ADR 是一种生成逐渐更难环境的仿真方法。ADR 不同于手动领域随机化,因为它不需要人为指定随机化范围。

API
2020 年 6 月,OpenAI 宣布推出一个多功能 API(OpenAI API[14]),用于“访问 OpenAI 开发的新 AI 模型”,允许开发者调用该 API 来处理“任何英文 AI 任务”。
文本生成(text generation)
OpenAI 普及了生成式预训练变压器(GPT)。
GPT-1
OpenAI 最初的生成式预训练变压器语言模型的论文由 Alec Radford 及其同事撰写(Improving language understanding with unsupervised learning[15]),并于 2018 年 6 月 11 日在 OpenAI 网站上以预印本形式发布。该论文展示了通过对包含长段连续文本的多样化语料库进行预训练,语言生成模型可以获得世界知识并处理长距离依赖性。
 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;font-size: 0.8rem;text-align: left;display: inline !important;">原始 GPT 模型
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.034em;font-size: 0.8rem;text-align: left;display: inline !important;">原始 GPT 模型GPT-2
GPT-2[16] 是一个无监督的生成式预训练变压器语言模型,是 OpenAI 最初 GPT 模型的继任者。于 2019 年 2 月发布,最初只发布了有限的演示版本。由于担心可能被滥用(如用于编写假新闻),其完整版本并未立即公开发布。有些专家对 GPT-2 的潜在威胁持怀疑态度。
针对 GPT-2,艾伦人工智能研究所开发了一种工具,用于检测“神经网络生成的假新闻”。其他研究者如 Jeremy Howard 警告说,GPT-2 的技术可能会“填满 Twitter、电子邮件和网络,生成听起来合情合理且符合语境的文章,这将淹没所有其他信息并难以过滤”。2019 年 11 月,OpenAI 发布了完整版本的 GPT-2 语言模型。
GPT-2 的作者认为,无监督语言模型是通用学习者,并且 GPT-2 在 7 个零样本任务中的 8 个任务中取得了最先进的准确率和复杂度。这表明模型不需要进一步训练特定任务的输入-输出示例。
GPT-3
GPT-3[17] 是 GPT-2 的继任者,于 2020 年 5 月首次描述。OpenAI 表示,GPT-3 的完整版本包含 1750 亿个参数,其规模比 GPT-2 的 15 亿参数大两个数量级。
GPT-3 在某些“元学习”任务中表现出色,能够从单一输入-输出对中推广。GPT-3 显著提升了基准测试结果,超过了 GPT-2。预训练 GPT-3 所需的计算量远超 GPT-2,达到数千 petaflop/s-day。
GPT-3 在 2020 年 9 月 23 日被微软独家许可。
? Petaflop/s-day1 Petaflop/s-day 表示系统在一天内执行了约 1020 次神经网络运算,这包括神经网络模型中的加法和乘法运算。Petaflop/s-day 是用来衡量计算机在一天内执行的总计算量的单位,表示每秒执行 1015 次浮点运算,连续运行一天所完成的运算总数大约为 1020 次。这种度量方式类似于能源中的“千瓦时”,用于描述大型深度学习模型的训练所需的实际计算量,而不仅仅是硬件的理论峰值性能。
了解更多 AI and compute[18]
Codex
2021 年中宣布的 Codex[19] 是 GPT-3 的一个后代,进一步在来自 GitHub 的 5400 万代码库上进行了训练,并成为 GitHub Copilot[20] 代码自动补全工具的核心技术。2021 年 8 月,Codex 的 API 进入私人测试阶段。
Codex 在应用过程中暴露出一些故障、设计缺陷和安全漏洞。GitHub Copilot 被指控生成了受版权保护的代码,但未标明作者或许可证。OpenAI 于 2023 年 3 月 23 日宣布将停止支持 Codex API。
GPT-3.5
GPT-3.5[21] 虽是 GPT-3 模型的一个子类,但 OpenAI 并未将它纳入 GPT-3 系列。2022 年 3 月 15 日,OpenAI 在其 API 中推出了具有编辑和插入功能的新版本 GPT-3 和 Codex,分别命名为 “text-davinci-002” 和 “code-davinci-002”。这些模型被描述为比之前的版本更强大,并训练于截至 2021 年 6 月的数据。2022 年 11 月 28 日,OpenAI 推出了 “text-davinci-003”。2022 年 11 月 30 日,OpenAI 开始将这些模型归类为 “GPT-3.5” 系列,并发布了 ChatGPT,该模型是从 GPT-3.5 系列中的某个模型微调而来。
GPT-4
2023 年 3 月 14 日,OpenAI 发布了 GPT-4[22],该模型能够处理文本或图像输入。GPT-4 的表现远超 GPT-3.5,并且能够生成或分析多达 25,000 字的文本,支持所有主要编程语言的代码编写。GPT-4 被应用于 ChatGPT 中,较之前的 GPT-3.5 版本有所改进,但仍保留了某些问题。
GPT-4o
2024 年 5 月 13 日,OpenAI 发布了 GPT-4o[23],该模型能够处理和生成文本、图像和音频。GPT-4o 在语音、多语言和视觉基准测试中取得了最先进的成果,创造了语音识别和翻译的新纪录。GPT-4o 在大型多任务语言理解(MMLU)基准测试中得分为 88.7%,高于 GPT-4 的 86.5%。
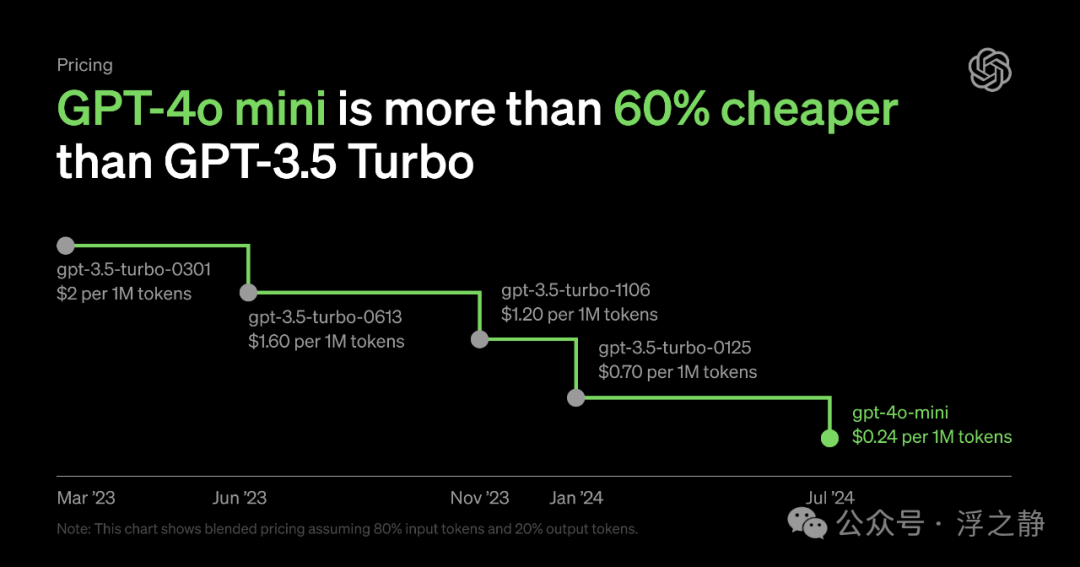
2024 年 7 月 18 日,OpenAI 发布了 GPT-4o mini[24],取代 ChatGPT 界面上的 GPT-3.5 Turbo,API 成本显著降低,适用于企业、初创公司和开发者。
o1
2024 年 9 月 12 日,OpenAI 发布了 o1-preview(更适合推理任务)和 o1-mini(更适合编程任务)模型,这些模型设计为在生成回答时花费更多时间思考,从而提高准确性。这些模型在科学、编码和推理任务中表现尤为出色,并提供给 ChatGPT Plus 和团队成员使用。
图像分类(Image classification)
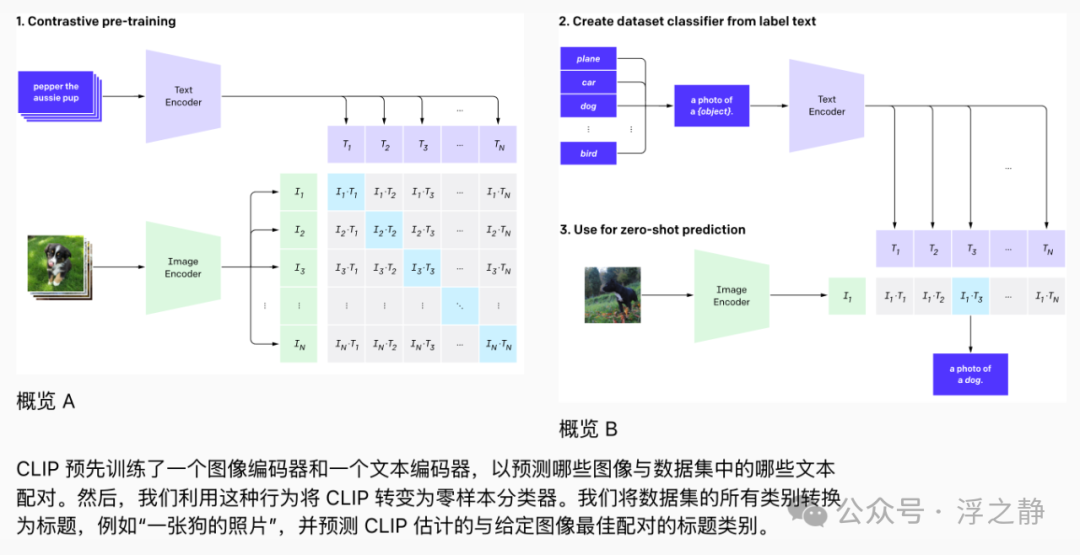
2021 年发布的 CLIP[25](对比语言-图像预训练)是一种模型,旨在分析文本和图像之间的语义相似性。它特别适用于图像分类任务。
文本到图像(Text-to-image)
DALL-E
DALL-E[26] 是一种变压器模型,能够根据文本描述生成图像,于 2021 年发布。DALL-E 使用一个拥有 120 亿参数的 GPT-3 版本来解释自然语言输入并生成相应的图像。它既可以生成现实中的物体图像,也可以生成不存在于现实中的物体。截至 2021 年 3 月,尚未提供 API 或代码。

DALL-E 2
2022 年 4 月,OpenAI 发布了 DALL-E 2[27],更新版本的模型具有更加逼真的生成结果。2022 年 12 月,OpenAI 在 GitHub 上发布了 Point-E[28] 软件,这是一种将文本描述转换为三维模型的初步系统。

DALL-E 3
2023 年 9 月,OpenAI 发布了 DALL-E 3[29],这个模型能够更好地根据复杂的描述生成图像,无需手动调整提示词,并能够渲染复杂细节,如手和文本。它于 10 月作为 ChatGPT Plus 的功能向公众发布。

文本到视频(Text-to-video)
Sora[30] 是一种文本到视频的模型,能够根据简短的描述性提示生成视频,并可将现有视频向前或向后扩展。它可以生成分辨率高达 1920x1080 或 1080x1920 的视频。生成视频的最大长度尚不明确。
Sora 的开发团队将其命名为日语中的“天空”,象征其“无限的创造潜力”。Sora 的技术是基于 DALL-E 3 文本到图像模型的技术改编而来。OpenAI 使用了公开可用的视频以及获得版权许可的视频进行系统训练,但并未透露视频的数量或具体来源。
2024 年 2 月 15 日,OpenAI 向公众展示了一些由 Sora 生成的高清视频,并声明其能够生成时长达一分钟的视频。OpenAI 还发布了一份技术报告(Video generation models as world simulators[31]),介绍了用于训练该模型的方法及其能力。报告也承认了该模型的一些局限性,包括在模拟复杂物理现象时的困难。《麻省理工科技评论》的 Will Douglas Heaven 称这些展示视频“令人印象深刻”,但也指出这些视频可能经过精挑细选,未必代表 Sora 的典型输出。
尽管 Sora 的公开演示后引发了一些学术领袖的质疑,但娱乐行业的知名人士对该技术的潜力表现出浓厚兴趣。在一次采访中,演员/电影制片人 Tyler Perry 表示,他对该技术能够从文本描述生成逼真视频的能力感到震惊,认为它有潜力彻底改变故事讲述和内容创作。他提到,他对 Sora 的可能性感到如此兴奋,以至于决定暂停扩建位于亚特兰大的电影工作室的计划(现在不知道有没有后悔)。
语音转文字(Speech-to-text)
Whisper[32] 是 2022 年发布的通用语音识别模型。它基于大量多样化的音频数据进行训练,同时也是一个多任务模型,能够进行多语言语音识别、语音翻译和语言识别(早期 ChatGPT 语音对话就是通过此模型处理的,而 gpt-4o 天然支持语音处理)。

音乐生成(Music generation)
MuseNet
2019 年发布的 MuseNet[33] 是一个深度神经网络,训练用于预测 MIDI 音乐文件中的后续音符。它可以用 10 种乐器生成 15 种风格的歌曲。据《The Verge》报道,MuseNet 生成的歌曲在开始时通常合理,但随着时间推移,音乐会变得混乱。在流行文化中,这一工具的早期应用可以追溯到 2020 年,用于网络心理惊悚片《Ben Drowned》为主角创作音乐。
Jukebox
2020 年发布的 Jukebox[34] 是一个开源的音乐生成算法,能够生成带有人声的音乐。该系统在 120 万个样本上进行了训练,用户输入一个音乐类型、艺术家和一段歌词后,系统会输出歌曲样本。OpenAI 表示这些歌曲“具有局部的音乐连贯性,并遵循传统的和弦模式”,但也承认这些歌曲缺乏“熟悉的大型音乐结构,如重复的副歌”,并且“与人类生成的音乐相比存在显著差距”。《The Verge》称其“在技术上令人印象深刻,即使生成的结果像是熟悉的歌曲的模糊版本”,而《Business Insider》则表示,“令人惊讶的是,有些生成的歌曲非常抓耳,并且听起来很正统”。
用户界面
Debate Game
2018 年,OpenAI 推出了 Debate Game[35],这是一款教导机器在一个人类裁判面前就玩具问题展开辩论的游戏。其目的是研究这种方法是否有助于审计 AI 决策并开发可解释的 AI。
Microscope
2020 年发布的 Microscope[36] 是一个可视化工具,展示了八个神经网络模型中每一层的重要神经元,这些模型通常用于可解释性研究。Microscope 的创建旨在轻松分析这些神经网络内部形成的特征。所包含的模型有 AlexNet、VGG-19、不同版本的 Inception 和不同版本的 CLIP ResNet。

ChatGPT
ChatGPT 于 2022 年 11 月发布,是基于 GPT-3 的人工智能工具,提供了一个对话界面,允许用户以自然语言提问,系统会在几秒钟内作出回答。ChatGPT 在发布 5 天内达到了 100 万用户。
截至 2023 年,ChatGPT Plus 是一个基于 GPT-4 的版本,订阅费用为每月 20 美元(原始版本基于 GPT-3.5)。OpenAI 还通过 GPT-4 API 候选名单向特定申请者提供 GPT-4,申请通过后,访问 GPT-4 需支付额外费用:初始输入文本每 1000 个 token 收费 0.03 美元,生成文本每 1000 个 token 收费 0.06 美元(上下文窗口为 8192 token);对于 32768 token 的上下文窗口,价格翻倍。
2023 年 5 月,OpenAI 为 iOS 的 App Store 推出了 ChatGPT 的用户界面,2023 年 7 月又在 Android 的 Play Store 推出。该应用支持聊天记录同步和语音输入(使用 OpenAI 的语音识别模型 Whisper)。2023 年 9 月,OpenAI 宣布 ChatGPT “现在可以看、听和说”。ChatGPT Plus 用户可以上传图片,移动应用用户可以与聊天机器人进行语音对话。
2023 年 10 月,OpenAI 的最新图像生成模型 DALL-E 3 集成到了 ChatGPT Plus 和 ChatGPT Enterprise 中。该集成通过与用户的对话,由 ChatGPT 生成 DALL-E 的提示词。
原计划于 2023 年发布的 OpenAI GPT Store[37],因 2023 年 11 月的领导层变动,延期至 2024 年初发布。
SearchGPT
SearchGPT[38] 是 OpenAI 开发的原型搜索引擎,于 2024 年 7 月 25 日揭晓,最初限量向 1 万名测试用户发布。它结合了传统搜索引擎功能和生成式 AI 能力(至今未发布)。
Stargate 及其他超级计算机
Stargate 是由微软和 OpenAI 开发的人工智能超级计算机项目的一部分。Stargate 是一个更大的数据中心项目的一部分,该项目微软可能投资高达 1000 亿美元(Microsoft, OpenAI plan $100 billion data-center project, media report says[39]、Microsoft and OpenAI Plot $100 Billion Stargate AI Supercomputer[40])。
Stargate 是微软和 OpenAI 未来几年计划的一系列 AI 相关建设项目之一。超级计算机的建设将分五个阶段进行。第四阶段计划建设一个较小的 OpenAI 超级计算机,预计将在 2026 年左右启动。Stargate 是该计划的第五个也是最后一个阶段,预计将在 2028 年完成,整个项目将历时五至六年。
Stargate 的人工智能预计将依托数百万个专用服务器芯片。超级计算机的数据中心将在美国一块占地 700 英亩的土地上建造,计划的耗电量为 5 吉瓦,可能依赖核能。“Stargate” 这一名称是对 1994 年科幻电影《星际之门》的致敬。
| 欢迎光临 链载Ai (https://www.lianzai.com/) |
Powered by Discuz! X3.5 |