链载Ai
标题: 轻松打造出各种AI专家 OpenAI 昨晚王炸更新 灵感竟来自字节论文 [打印本页]
作者: 链载Ai 时间: 昨天 11:56
标题: 轻松打造出各种AI专家 OpenAI 昨晚王炸更新 灵感竟来自字节论文
OpenAI 连续12天发布会,第二天依旧是短平快
也是短短20分钟结束,但比第一天略长
相比第一天的o1模型和Pro会员引发朋友圈、社交媒体、群聊的吐槽和大讨论
今天发布的东西可以说是无人问津,几乎群聊没人在聊
但其实今天发的东西对普通人来说可能几乎没用处,对开发者、企业、科研领域来说可谓是王炸更新!
OpenAI 首席执行官山姆·奥特曼对此表示:
“效果一级棒,是我2024年最大的惊喜,期待看到人们构建什么!”
那么,这项技术究竟是什么,它带来了哪些变革,又如何改变我们的认知?
接下来,深入说说,昨晚到底更新了什么...
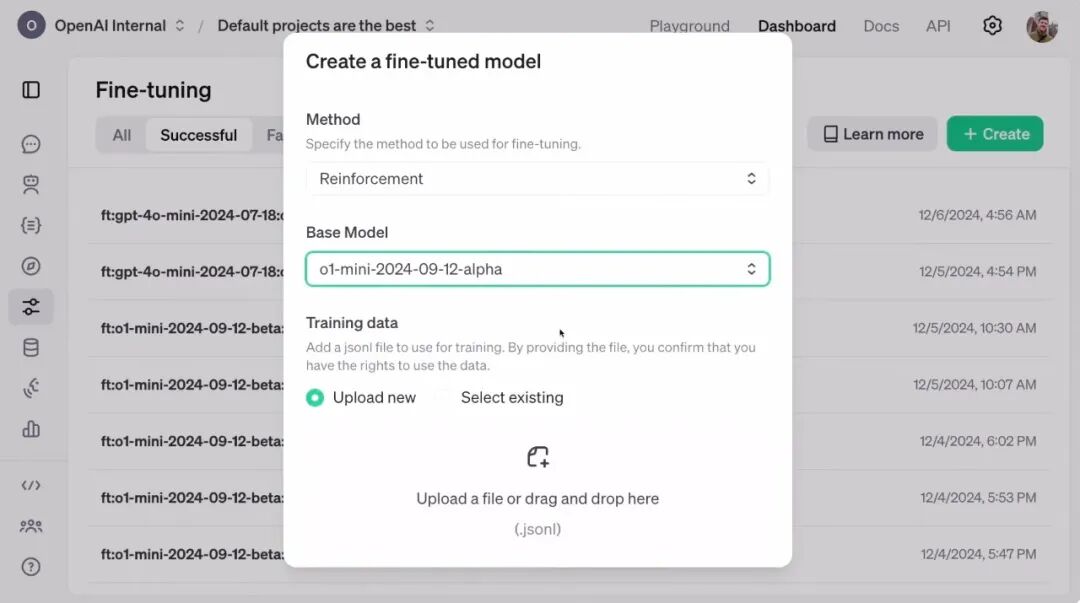
OpenAI昨晚发布了一种叫强化微调(Reinforcement Fine-Tuning, RFT)的技术。
先听听发布会中原话解释它是什么?
“再次强调,这不是传统的微调。
这是强化微调,它真正利用了强化学习算法,将我们的模型从高中学生水平提升到了专家博士水平。”
也就是说通过强化微调你可以轻松的将现有的模型直接训练成特定领域的专家。
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);letter-spacing: 0.034em;">什么意思呢?
就是不论是GPT4o模型还是o1模型,它在综合能力上都是很强没问题的,但是一旦你想要处理一些专业领域的问题,比如法律、医疗、金融、科研等专业领域的问题,它的水平可能无法满足这些领域的专业需求。
那么就需要通过专业的训练来让它能适应特定领域的需要。
但是其实呢GPT已经从大量通用数据中学习了广泛的知识,涵盖多个领域如果你再去重新训练其实是浪费。
- 专业领域问题通常需要深度领域知识、推理能力和对领域规则的精准理解。
- 通用模型虽然有基础知识,但由于没有明确的任务或领域指导,其回答可能不够准确或深入。
所以其实只我们需要一些简单的训练来让模型知道它具体要干什么?这个领域的要求什么?我应该怎么做?直接调用已经训练好的知识和能力来解决专业问题!通过强化微调优化模型:
- 使用少量高质量的专业领域数据,让模型明确“这个领域的任务是什么”。
- 模型学会在特定领域中如何运用已有的知识,结合强化学习算法优化推理路径。
- 例如,通过简单的专业任务训练,模型可以从“法律知识库”转化为“法律助手”,从“医学基础知识”转化为“医学诊断专家”。
强化微调的核心概念和优势
- 重点不是让模型“学习更多新知识”,而是让模型理解:
- 这种训练类似于“指路”:通过少量示例,指导模型如何在特定情境中使用已有能力。
强化微调技术原理
传统监督微调与强化微调的区别
- 强化微调允许模型学习“推理新领域中的逻辑”,而不仅是模仿输入特征。
- 通过“奖励”正确答案的逻辑路径、“惩罚”错误答案的逻辑路径,逐步优化模型的表现。
强化学习具体流程
- 输出答案并附带推理逻辑,例如从症状列表中推断可能的基因病因。
- 比较模型输出与标准答案,对生成的答案评分(范围0-1)。
- 对正确的答案给予奖励,鼓励它不断学习,强化模型学习正确逻辑
- 反反复复通过多次训练,不断强化正确的逻辑,减弱错误逻辑。
- 只需几十个高质量的示例即可显著提升模型性能,这在大语言模型训练中是革命性的,传统方法通常需要大规模数据。
- 强化微调不仅模仿输入特征,还能学习新领域中的推理逻辑。
- 模型能够分析问题,提出可能的解决方案,并优化回答的准确性和逻辑性。
- 用户只需提供数据集和评分器,其余的训练和优化工作由OpenAI基础设施完成。
能够在不同领域实现模型的个性化和专业化。
具体案例
案例 1:法律领域 - 与Thomson Reuters的合作
Thomson Reuters作为法律科技领域的领导者,与OpenAI合作,将强化微调应用于法律助手开发。- 利用强化微调技术,优化O1 Mini模型,使其适应复杂的法律工作流程。
- 模型在提供法律咨询、分析法律文件和辅助决策等方面表现出色。
通过强化微调,模型能够更精准地识别复杂法律问题的核心要素。法律助手显著提高了律师处理复杂案件的效率,减少了人工分析的时间成本。数据集基于大量法律文档,通过强化学习训练模型,使其能在推理复杂法律问题时表现出更高的逻辑性和准确性。
案例 2:医学领域 - 罕见遗传病的基因致病分析
OpenAI与伯克利实验室(Berkeley Lab)、德国Charité医院以及Monarch Initiative合作,研究罕见遗传病的基因致病机理。全球约有3亿人受到罕见遗传病的影响,单一疾病可能稀有,但总量却相当庞大。- 研究目标:开发基于O1 Mini模型的AI工具,用于推断患者症状背后的致病基因。缩短患者从症状到确诊的漫长过程,提高诊断效率。在给定症状列表的情况下,模型预测可能导致罕见遗传疾病的基因,并解释为什么选这些基因。
- 数据集构建:从数百篇科学文献的病例报告中提取信息,内容包括:
数据集包含1,100个训练示例和独立验证集,确保模型通过推理而非记忆完成任务。
在强化微调的实验中,实验人员通过对比 三种模型 的表现来评估强化微调的效果。这三种模型分别是:
o1(基础模型):最新发布的未经过微调的 o1 模型。
o1 Mini(精简版本):未经过微调的 o1 Mini 模型,是一个更小、更快、更廉价的版本。
强化微调后的 o1 Mini:使用强化微调方法在特定任务数据集上优化的 o1 Mini 模型。
实验人员使用以下三项指标评估模型的性能:
Top 1(首位准确率):模型一次性答对的概率;
Top 5(前五准确率):模型前五次预测中有正确答案的概率
Top Max(最大准确率):模型预测中有正确答案的概率(位置不限)。
实验结果:o1 mini的强化微调版,战胜了昨天刚发布的o1(基础版)。
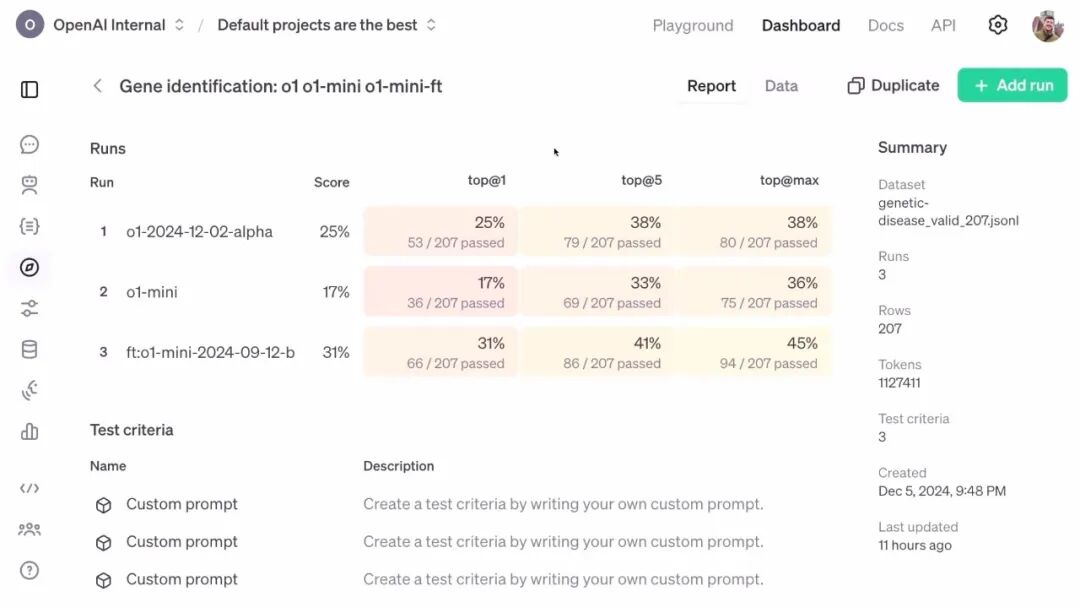
- 强化微调后的 o1 Mini 模型保留了“小型化”的优势(更快、更便宜),同时在性能上实现了显著提升。
- 它甚至接近或超过未微调的 o1(基础模型),展示了强化微调的潜力。
这表明,通过少量领域数据和强化学习技术,较小规模的模型也能达到高水平的领域适配性能,适合成本敏感型的实际应用场景。研究人员评价:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);letter-spacing: 0.034em;">模型在验证数据上的表现表明,它学会了推理而非记忆。模型推理能力强大,能够有效补充现有的生物信息学工具。
强化微调的核心价值就在于高效地将模型的广泛能力与具体任务需求对接,通过少量训练“告诉模型该怎么做”,从而提升其在专业场景中的表现。
强化微调RFT不仅适用于科学研究,还可扩展至AI安全、化学、生物信息学等领域。
等等,其实强化微调这个概念最早其实是字节跳动提出来的
在今年的ACL 2024(这是自然语言处理(NLP)和计算语言学领域最重要的国际学术会议)顶会上字节跳动发表了一篇“REFT: Reasoning with REinforced Fine-Tuning”的ReFT论文。
提出了Reinforced Fine-Tuning (ReFT)的 方法,通过引入强化学习来增强模型的推理能力。

字节跳动的研究人员发现只让模型学一种固定的解题路径(如思维链),限制了它的潜力。
比如,一个数学题可能有三种解法,但训练时模型只学了一种。这就好比让你学数学时只看一种答案解析,遇到变化稍大的题目时,你可能就不会解了。
所以,他们提出了一种新方法,叫强化微调(ReFT),它可以让模型在训练时自己去探索多种解题路径,并从中学习哪种更优。这样,模型就像是多看了不同的答案解析,更灵活、更聪明了。
ReFT是怎么做到的?
- 先用传统方法(SFT)训练模型,让它初步学会解题,能给出正确答案。
- 强化学习(Reinforcement Learning):
- 接下来,让模型自己试着去探索多种解题路径,比如给一个题目,它试着推导出不同的思路。
- 如果推导出的答案正确,就给它奖励;如果错了,就不给奖励。
- 奖励机制是自动的,模型只需要看最终答案对不对,不需要人来打分。
这个过程用了一种强化学习算法(PPO),让模型在探索不同路径时不会偏离太远,始终围绕正确解法进行改进。看看是不是和OpenAI的强化学习描述一毛一样???有什么特别之处?
- 和传统方法不同,ReFT会引导模型探索多个正确的解题路径,而不是只学一种。
- 比如,你会“代入法”解方程,ReFT还会让你学“消元法”,甚至自己尝试组合两种方法。
- 它的奖励是基于答案对不对,而不是对每一步推导都评分。这省去了人工标注的麻烦,同时模型可以专注于得到正确答案。
- ReFT在原有训练数据的基础上进行优化,不需要额外生成新的训练题目。
ReFT的表现显著优于传统方法。在GSM8K数据集上,模型的解题正确率从SFT的约63%提高到了81%。如果结合一些推理阶段的技巧,比如“多数投票”(让模型多次解题并选出最常见的答案)或者“重排序”(用奖励模型选出最优答案),ReFT的效果会更好。论文:https://arxiv.org/pdf/2401.08967
强化微调的意义
强化微调开启新一代AI模型的训练方式,不仅是模型性能提升的工具,还可能引领未来 AI 模型的定制化发展方向。- 与大模型结合:大语言模型的能力可以通过强化微调进一步细化和专精。
- 智能化升级:在未来,强化微调可能成为构建智能系统的重要组成部分,比如动态适应用户需求、自动优化任务等。
- 适配性强:无论是法律、金融、医疗还是工程领域,强化微调都可以优化模型,使其成为某一领域的“专家”。
- 快速学习能力:只需少量高质量的样本(几十到几百个),模型就能快速适应新的领域,这极大降低了定制成本。
- 泛化能力:模型学到的知识和推理方法可以应用于未见过的验证数据,证明其并非仅仅“记住”训练样本,而是真正学会了推理。
OpenAI推出的强化微调技术标志着人工智能定制新时代已然来到。它通过简化开发流程以及精准调整,为企业及研究人员营造出一个全新的智能环境。从法律到生物医学,应对复杂问题时,这种定制能力可以使得专家模型能够低成本的轻松应用到各行各业。
| 欢迎光临 链载Ai (https://www.lianzai.com/) |
Powered by Discuz! X3.5 |