链载Ai
标题: 构建生产级 RAG 系统前,必须搞懂的 7 个核心问题 [打印本页]
作者: 链载Ai 时间: 前天 12:03
标题: 构建生产级 RAG 系统前,必须搞懂的 7 个核心问题
在人工智能领域,如何使大模型既能理解外部数据,又能高效回答复杂问题,一直是生产级应用开发中的核心挑战。检索增强生成(RAG, Retrieval-Augmented Generation)技术正为这一难题提供解决方案。本文将带您深入探索如何构建生产级 RAG 应用,解决常见技术难题,并优化性能表现。
一、使用大模型理解外部数据的两种范式
在实际开发中,大模型理解外部数据的关键有两种主要范式:
1. 检索增强生成(RAG, Retrieval-Augmented Generation)
RAG 的核心思路是保持语言模型(LLM, Large Language Model)固定,通过外部数据检索来动态提供上下文:
示例:一个电商平台可以使用 RAG 技术从商品描述数据库中动态检索特定商品的详细信息,直接回答用户提问。
优点:
灵活性高,数据更新直接反映在检索结果中。
部署无需重新训练大模型,节省成本。
2. 微调(Fine-tuning)
通过训练过程将外部知识直接融入模型内部:
全参数微调(Full Parameter Fine-tuning):更新所有模型参数。
参数高效微调(Parameter-Efficient Fine-tuning, 如 LoRA):仅更新部分参数或添加小型适配器模块。
示例:金融机构可以通过微调训练模型回答特定行业法规相关的问题。
优点:
3. RAG 和微调的对比
以下通过表格对比两者特点:
| 特性 | RAG | 微调 (Fine-tuning) |
|---|
| 实现难度 | 较低:无需修改模型,只需构建检索和数据管道 | 较高:需要训练大模型并可能增加计算成本 |
| 数据更新 | 实时更新:数据变化无需重新训练 | 需要重新训练或微调模型 |
| 灵活性 | 高:可动态适配不同任务和领域 | 较低:适合特定任务或领域的模型 |
| 成本 | 较低:无需高性能硬件即可运行 | 较高:训练过程耗费大量计算资源 |
| 生成质量 | 中等:依赖于检索系统的性能 | 较高:通过定制化训练生成更精准的答案 |
| 适用场景 | 数据快速变动、跨领域任务 | 固定领域、需要高精度回答的场景 |
| 挑战 | 检索相关性、幻觉现象(Hallucination) | 训练数据需求大、可能存在灾难性遗忘(Catastrophic Forgetting) |
4. 小结
本文主要讨论 RAG,因为:
灵活性更高:RAG 不依赖于模型参数的修改,可以动态适配不同任务,尤其适合开发迭代频繁的生产级应用。
数据更新方便:RAG 能够实时反映数据更新,而微调通常需要重新训练,耗时耗力。
成本较低:构建 RAG 系统的硬件和算力需求更少,能更快部署到生产环境中。
基于以上优势,RAG 是目前开发生产级大模型应用的首选技术。因此,本文将重点讨论如何开发和优化 RAG 系统,帮助您快速构建高效解决方案。
二、开发生产级 RAG 应用必须回答的7个问题
要构建高效的 RAG 系统,开发者需要逐步回答以下关键问题:
1. RAG 系统的典型组成有哪些?
一个完整的 RAG 系统通常包含:
流程图示:
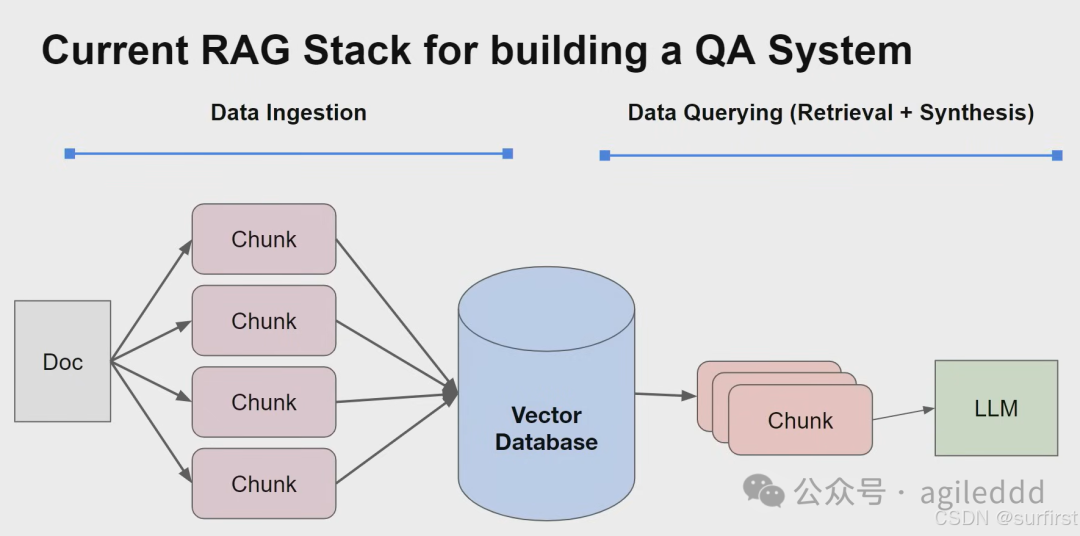
2. 基础 RAG 实现面临哪些挑战?
开发者通常会遇到:
3. 如何提升 RAG 应用的性能?
性能优化可以从以下几方面入手:
数据优化(Data Optimization):调整数据块(Chunk)大小,添加元数据(Metadata),使用高质量的向量嵌入(Embedding)。
检索优化(Retrieval Optimization):采用混合检索(Hybrid Search, 语义+关键词)、重排序(Reranking)、递归检索(Recursive Retrieval)。
综合优化(Synthesis Optimization):引入代理系统(Agent)分解复杂问题,充分利用模型的推理能力。
微调(Fine-tuning):优化嵌入模型或直接微调语言模型。
4. 为什么评估(Evaluation)很重要?
评估是理解系统性能并发现改进空间的关键:
5. 哪些技术是“必备”优化?
6. 如何利用代理(Agent)提升 RAG 性能?
通过引入代理,RAG 系统可以:
7. 微调如何优化 RAG 管道?
三、总结
生产级 RAG 应用的开发是一项系统化工程,需要结合检索优化、模型调整、性能评估等多个环节。开发者可以从简单的开源工具(如 LangChain 或 Haystack)入手,快速搭建原型系统,并通过微调和性能优化迭代出高质量的解决方案。
下一步行动:如果您也想构建属于自己的 RAG 系统,不妨从设计数据摄取管道开始,通过逐步优化,探索这项技术的潜力。
| 欢迎光临 链载Ai (https://www.lianzai.com/) |
Powered by Discuz! X3.5 |