站在2026年初,回头看DeepSeek这两项看似孤立却内在契合的技术, 笔者隐约察觉到DeepSeek可能的大棋局。OCR 是关于“感知”的革新,mHC 则是关于“认知”的重塑,两者融合,会带来一次多模态大模型向“信息动力学”本质的回归。
一、 从符号逻辑到象形空间
笔者在从DeepSeekOCR到甲骨文:语言的本质回归中提出:
语言本质上不是离散符号的集合,而是事实的感知形态在大脑几何空间中的投影。
传统的 LLM 路径试图将复杂的现实世界强行拆解为一维的 Token 序列,这在本质上是一种“语义降维”。
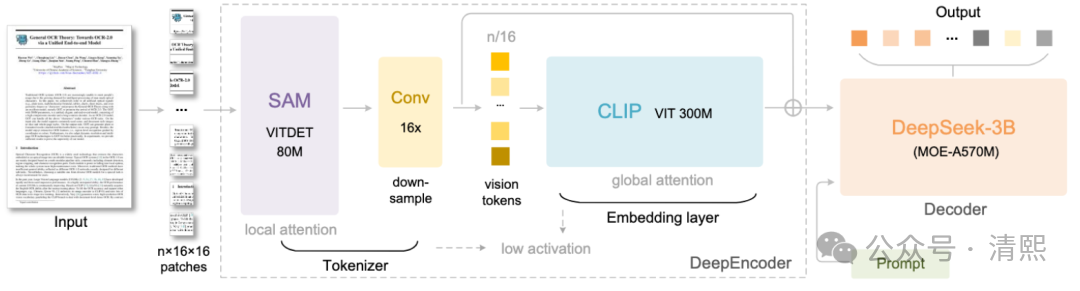
而DeepSeek-OCR采取了截然相反的路径,不再识别符号,而是压缩图像,从而实现了:
象形与语义的统一,通过将文本、表格、公式渲染为图像并进行高倍压缩,DeepSeek 实际上让模型重新学习了“形义融合”;
视觉 Token 的高密度,文字不再是孤立的概率向量,而是携带了排版、层级、空间关联的“语义投影”;
认知哲学的一致性,契合哈佛研究,大脑语义理解是按高维几何结构定位的。DeepSeek 让机器像人眼一样“全景感知”,而非线性“读取”。
二、 从工程技巧到动力学约束
高密度的视觉 Token 会给传统的 Transformer 架构带来巨大的不稳定性。如何承载“极高密度”的信息处理?mHC给出了物理层面的答案。
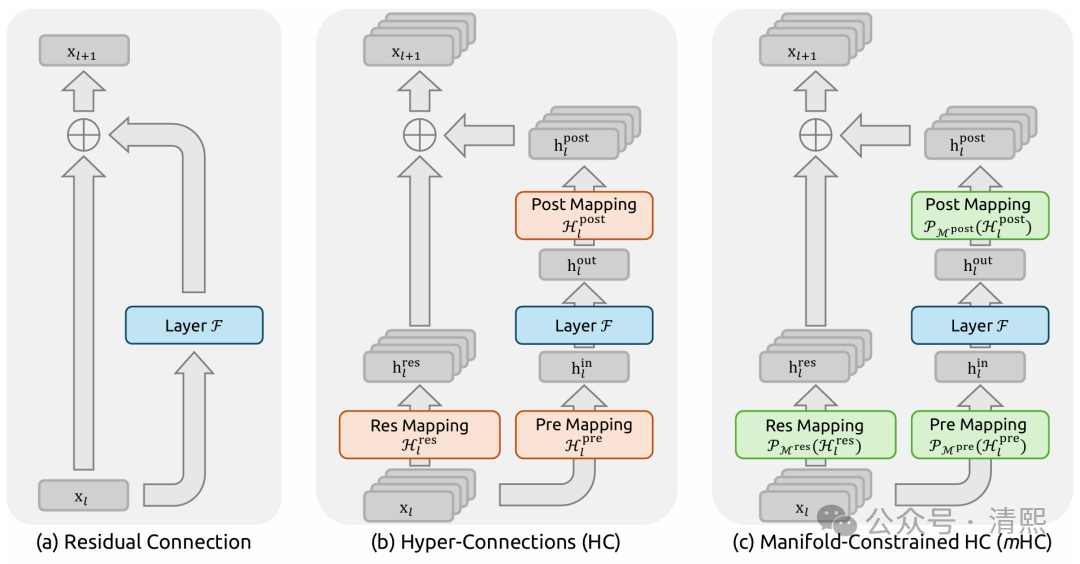
DeepSeek mHC:一次将 Transformer 残差流拉回重整化轨道的重大升级中强调,残差连接不应是工程补丁,而是模型内部演化的动力学核心:
引入守恒律,mHC 通过引入双随机矩阵约束,强制要求残差流在跨层传输时保持测度守恒;
符合物理直觉,类似于重整化群中的尺度稳定性,信息可以在通道间重新分配,但不会凭空增殖或消失;
抑制尺度失控,在深层网络中,这种约束可确保信号增益始终稳定,显著缓解此前HC的数值爆炸问题。
三、预判 DeepSeek 模型终极蓝图
当OCR 的形义融合、mHC 的流形守恒与MoE的调度优化结合时,一个新的多模态物理一致性架构就成型了。
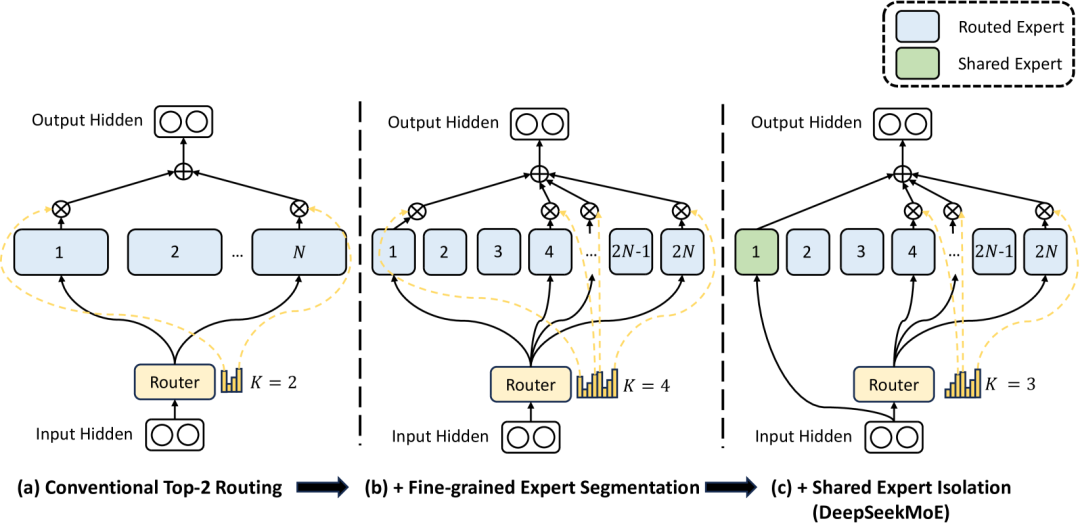
1. 融合的可行性与技术助益:这个融合架构并非简单的模块叠加,而是深层的相互赋能。
mHC 增强 OCR 解码鲁棒性,在高倍压缩下,视觉 Token 的语义极度密集且模糊,mHC 多流架构允许不同流分别关注布局结构与字符细节,利用强大的特征融合能力从模糊表征中精准恢复信息;
确保非线性重整化的精度,混合矩阵是受限的,不同流在融合时表现为凸组合。在数学上保证了模型能精准剔除白边等视觉噪声,只保留高价值拓扑语义。3. 优化提升OCR泛化能力:视觉Token具有强局部聚集性,会导致MoE中大量Token争抢少数专家。
强制负载均衡,可将双随机约束引入 MoE 路由优化,强制负载测度守恒,既不让一种Token淹没所有专家,也不让一个专家吞掉所有Token;
路由偏好平移不变性,确保Token的路由偏好不会随深度剧烈抖动,对于长文档,首末页的理解逻辑保持几何上的一致性,可提升对非标排版的泛化能力。
四、数字物理融合芯片
这种向动力学回归的算法范式,必然会倒逼底层硬件的洗牌:
存算一体,mHC 的双随机约束在数学形式上可以看作一个离散版的、节点上的“基尔霍夫电流守恒”定律;
光子芯片,光子处理前端可以在光速下完成 OCR 式的视觉感知,将感知运算一体推向极致;
算力重构,衡量标准从追求 TFLOPS转向追求每秒流形演化步数。低熵、高能效的“物理计算”硬件将成为下一轮算力竞赛的热点。
五、 回归物理通往AGI
维特根斯坦 -> 格罗滕迪克 -> 大语言模型中笔者讲意义即结构,认知的本质是对结构的元学习能力。
大模型海量语料的范畴提取,同伦的态射,格罗滕迪克的Motive,无穷范畴,都是在做同一件事,对元结构的元学习形成元认知。
DeepSeek 的一系列突破给我们很大启示,大模型竞争的中场,是谁能率先在数字空间里构建出一套最接近现实物理规律的信息动力学。
通过OCR 寻找感知形式的本原,通过mHC 建立信息处理动力学守恒,DeepSeek 正把 Transformer 从“经验炼丹”改造成“物理定律”。
当大模型开始以符合物理守恒的方式去“感知认知世界”时,机器与人类认知之间的那道鸿沟,正以前所未有的速度消融。
DeepSeek更新R1全部论文,看来是已经掌握更牛的下一代技术了。万物归于象形,架构归于流形的深度重整化,具有巨大潜力。所以,今年春节,我们不仅可以期待DeepSeek V4/R2,还可能是个统一多模态版本?!