|
ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;letter-spacing: normal;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);"> 上个月llama3.1的405B已经发布,除了感叹开源模型效果的厉害之外,另一个普遍的感受就是,跑不动,根本跑不动,没资源,就算能训练,也部署不起。所以很多人就自然而然关注到了知识蒸馏,通过将大模型能力迁移到小模型能力上。于是大概调研了下,本文主要是对清华的《MiniLLM:Knowledge Distillation of Large Language Models》和Meta的《Distilling System2 into System1》一些解读,刚好他们分别作为白盒蒸馏和黑盒蒸馏的一个典型代表。ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;letter-spacing: normal;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);"> 在知乎搜了一下minillm相关的文章,如《吃果冻不吐果冻皮:大模型知识蒸馏概述 》总结性的介绍了下minillm的逆向kl散度的思路。即最小化前向 Kullback-Leibler 散度 (KLD) 的挑战为教师分布中不太可能的区域出现概率过高,从而在自由运行生成过程中导致不可能的样本 。为了解决这个问题,MINILLM 选择最小化逆向 KLD。这种方法可以防止学生高估教师分布中的低概率区域,从而提高生成样本的质量。但具体原因只在论文中才更清楚,于是部分细节整理如下,本文主要对FKL和RKL差异以及从强化学习视角看MiniLLM做一些介绍,其他论文细节没有涉及太多。ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-optical-sizing: inherit;font-size-adjust: inherit;font-kerning: inherit;font-feature-settings: inherit;font-variation-settings: inherit;margin-top: calc(2.33333em);margin-bottom: calc(1.16667em);clear: left;color: rgb(25, 27, 31);letter-spacing: normal;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);">MiniLLM蒸馏ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-optical-sizing: inherit;font-size-adjust: inherit;font-kerning: inherit;font-feature-settings: inherit;font-variation-settings: inherit;margin-top: calc(1.90909em);margin-bottom: calc(1.27273em);clear: left;color: rgb(25, 27, 31);letter-spacing: normal;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);">MotivationingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;letter-spacing: normal;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);">前向KL散度倾向于学习mean-seeking,反向kl散度学习mode-seekingingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;letter-spacing: normal;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);"> 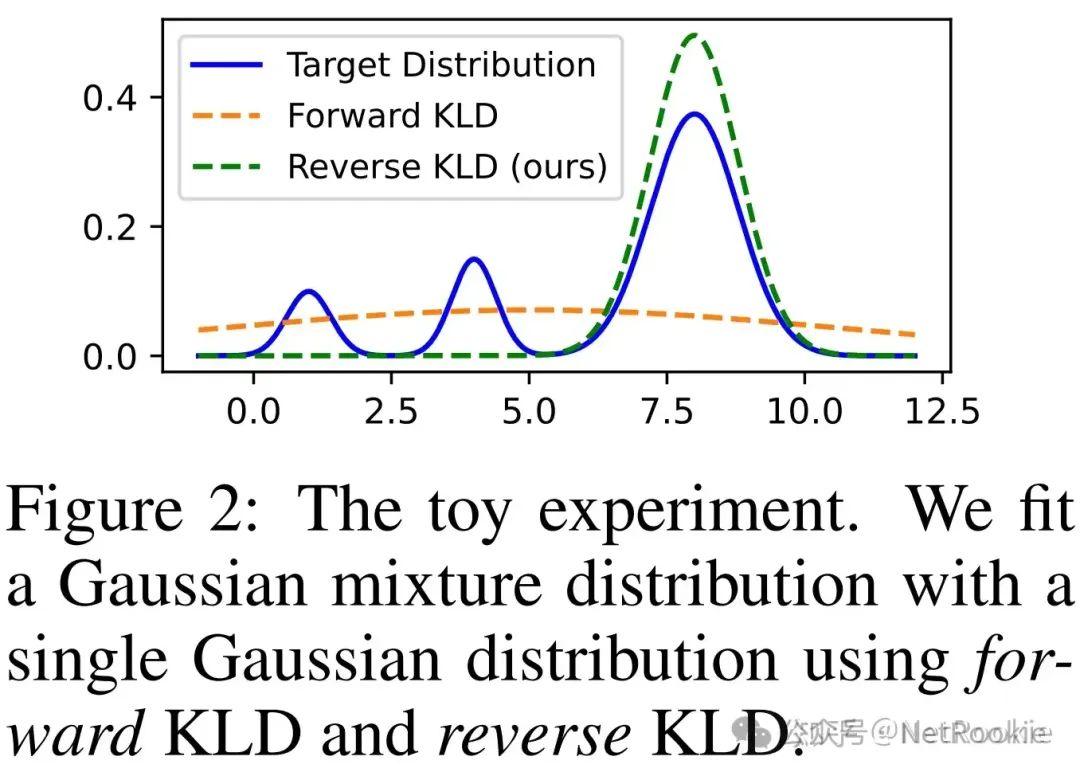
ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;letter-spacing: normal;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);">首先需要明确KL散度的非对称性质,即前向和后向是当前仅当两个分布完全相等时才等价的,然后我们分开看一下两个kl散度的具体公式。了解前向KL散度和KL散度分别会导致mode seeking 和 mean seeking 产生的原因在于:ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;letter-spacing: normal;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);">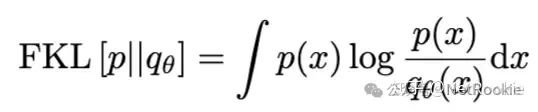
ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;letter-spacing: normal;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);" class="list-paddingleft-1">当p(x)较大时,qθ(x) 也需要比较大且比p(x)相对更大,否则公式右边很大的情况下,FKL整体就无法达到最小; 当p(x)较小时,p(x) 在 log 外趋于0占主导,FKL整体总是能比较小,跟qθ(x)关系较小。所以在优化的时候,qθ(x) 会覆盖p(x)的所有mode,即便此时有可能导致高估 p(x) 很小的部分,对应上述图中的橙色部分。 ingFang SC", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif;font-size: medium;letter-spacing: normal;text-align: start;text-wrap: wrap;background-color: rgb(255, 255, 255);">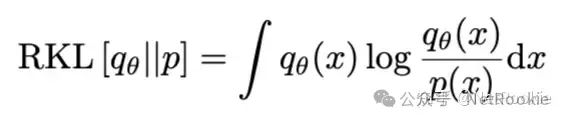
由此可以看下MiniLLM具体的方法图:
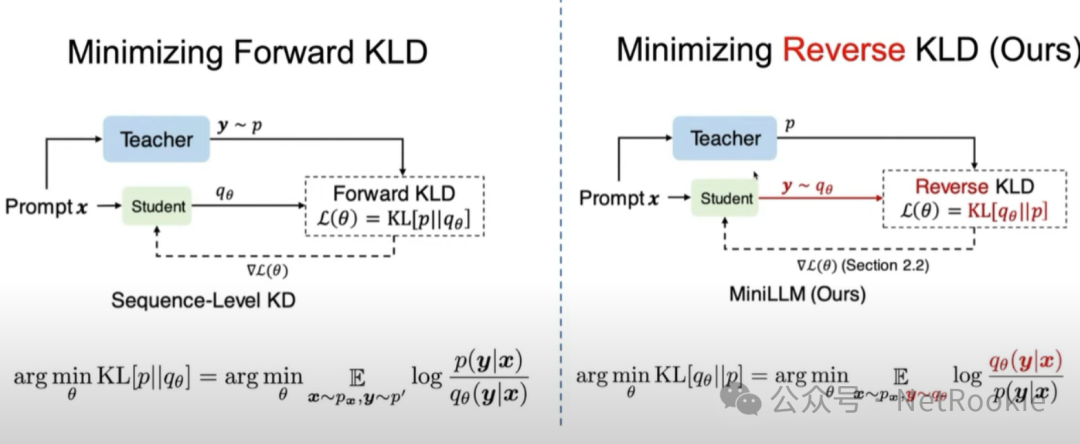
RKL和Inverse RL的等价的数学推导论文中的另一个视角个人觉得特别好,就是将RKL和逆强化学习进行对比,并给出了数学说明,可以看一下 公式说明:这里的公式序号均来自论文本身,目的是结合论文一起看可能更好,不破坏原有公式顺序。 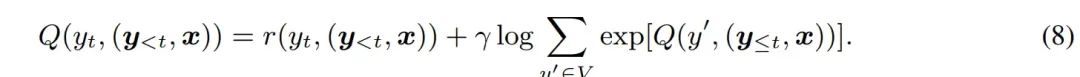
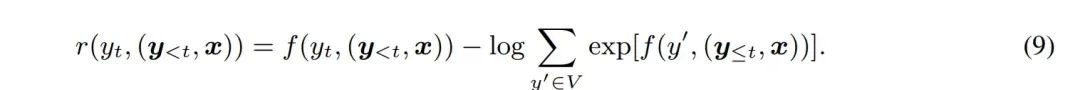
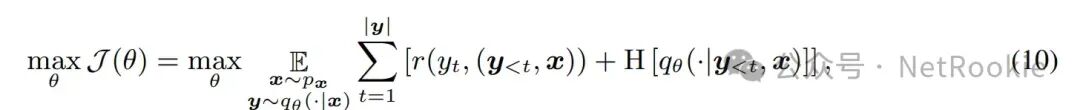

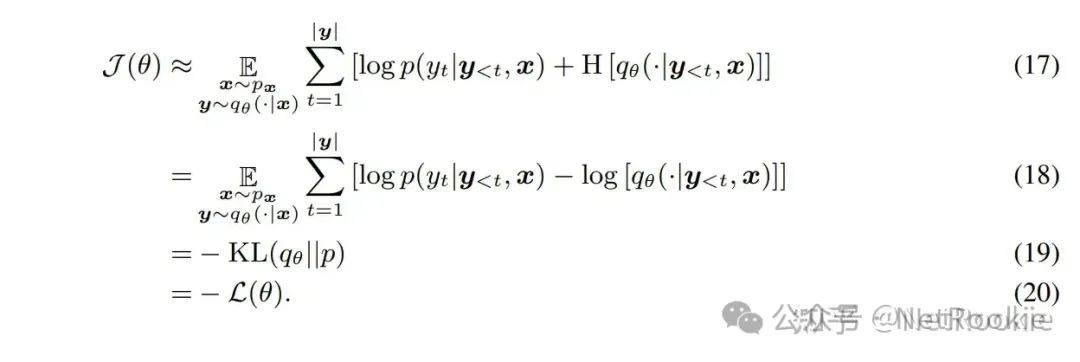
既然可以这么类比,RKL约等于逆强化学习,FKL等价于模仿学习,而在实际应用和理论说明中,逆强化学习的效果都会比模仿学习更优,虽然更加难以训练,但其泛化性能,理论上限肯定会更高,所以结论是MiniLLM的RKL理论上是更优的。模仿学习和逆强化学习这个说明可以查看:https://www.zhihu.com/question/470949607/answer/2450111740?utm_id=0 实际怎么训练上面两个部分,其实都在说明,MiniLLM理论证明上是更优的蒸馏方法。所以我们可以去进行大胆尝试。实际的训练过程,类似于RLHF的训练方式,教师模型在训练中只推理,作为奖励信号去训练模型。作者也提供了类似ranking loss的更简单的平替方式去优化,对比传统Bert时代的蒸馏方法都会有提升。感谢作者! # https://github.com/microsoft/LMOps/blob/main/minillm/finetune.py#L166
# 这里是实际蒸馏loss的计算
def get_distil_loss(args, tokenizer, model, teacher_model, model_batch, no_model_batch, logits):
with torch.no_grad():
teacher_model.eval()
teacher_outputs = teacher_model(**model_batch, use_cache=False) # 教师模型推理
teacher_logits = teacher_outputs.logits # 获取教师分布logits
if args.model_parallel:
distil_losses = mpu.parallel_soft_cross_entropy_loss(logits.float(), teacher_logits.float())
distil_losses = distil_losses.view(-1)
loss_mask = no_model_batch["loss_mask"].view(-1)
distil_loss = (distil_losses * loss_mask).sum(-1) / loss_mask.sum(-1)
else:
teacher_probs = F.softmax(teacher_logits, dim=-1, dtype=torch.float32) #
inf_mask = torch.isinf(logits)
#log_softmax实际上是在教师和学生的交叉熵;交叉熵损失在形式上等价于KL散度减去一个常数项(分布P 的熵)在最小化KL散度时可以忽略
logprobs = F.log_softmax(logits, dim=-1, dtype=torch.float32)
prod_probs = torch.masked_fill(teacher_probs * logprobs, inf_mask, 0)
x = torch.sum(prod_probs, dim=-1).view(-1)
mask = (no_model_batch["label"] != -100).int()
distil_loss = -torch.sum(x * mask.view(-1), dim=0) / torch.sum(mask.view(-1), dim=0)
return distil_loss
一般来说,实际训练中还会加上sft数据的loss,确保不跑偏,类似rlhf中的reference model的作用:
output = self.model(inputs, attention_mask=attention_mask, return_output=True)
sft_loss = self.loss_fn(output.logits, labels)
需要注意教师模型和学生模型需要使用同源的模型。即相同的tokenizer,对于国产模型来说,qwen、deepseek、yi等都有相同tokenizer不同尺寸的模型可供选择。 System2到System1蒸馏整体说明: 人类认知系统中的两种推理系统,系统1和系统2,系统1被认为是无意识的,能够快速识别和迅速判断,也叫做快思考,系统2被认为是处理复杂问题如数学和逻辑问题,需要深思熟虑,也叫做慢思考。 在大模型中,可以将中间的流程如多次调用大模型、中间的思考tokens类比为深思熟虑的过程,这些方法如cot、RaR等等带来更好的推理效果,但与此同时,耗时问题会导致这些方法很难用于生产落地。于是很多方法都在尝试将系统2的效果蒸馏到系统1当中(毕竟自2023年 gpt4出来后,应该有非常多的黑盒蒸馏gpt4数据训练到各家系统中;还有很久之前llama2的ghost attention:在每一句中都加入system prompt让 Llama 2 有效地遵循多轮指令,都是一些蒸馏的有效形式)。 这篇论文的主要与之前差异点在于,显式的提出System2的推理能力蒸馏到System1中,并做了很多实验进行验证。可以理解为论文提供了非常好的一种数据合成的范式,通过使用这些数据进行指令微调等方法,提升System1的推理能力。 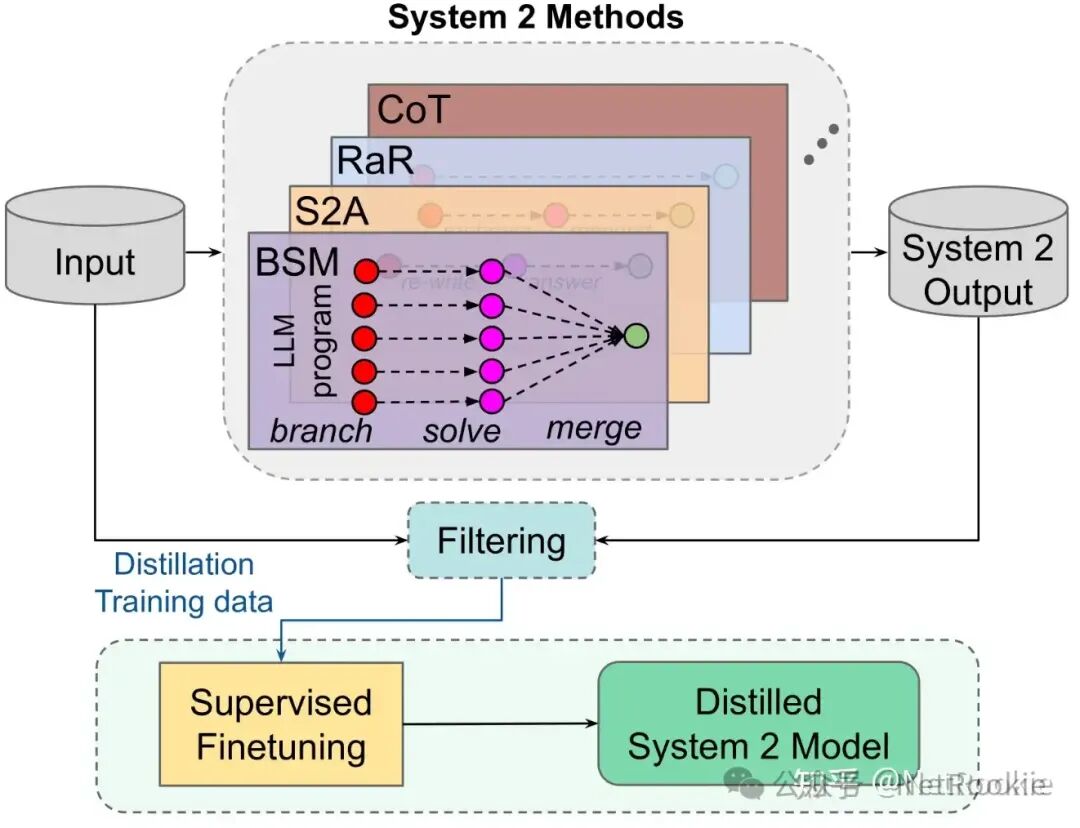
以下几个公式是对System1和System2的形式化说明: 


也就是说,通过上述公式3可以得到的大量训练数据,但是实际会存在质量问题。论文主要通过一致性标准进行过滤。 但猜测实际可能有更多更精细化的方式实现。 然后就是四种方式在不同数据集上的效果,我觉得给出Prompt可能是最好的方法体现形式 RePhrase And Respond DistillationPrompt: "{question}"\nRephrase and expand the question, and respond. 让模型先改写,改写可能提供更丰富的文本信息,然后再回答,能让大模型用自己的知识体现理解问题,回答问题。 System2 Attention Distillation
让大模型过滤无效信息,去除有偏信息和不相干上下文,然后再改写基础上进行回答 Branch-Solve-Merge Distillation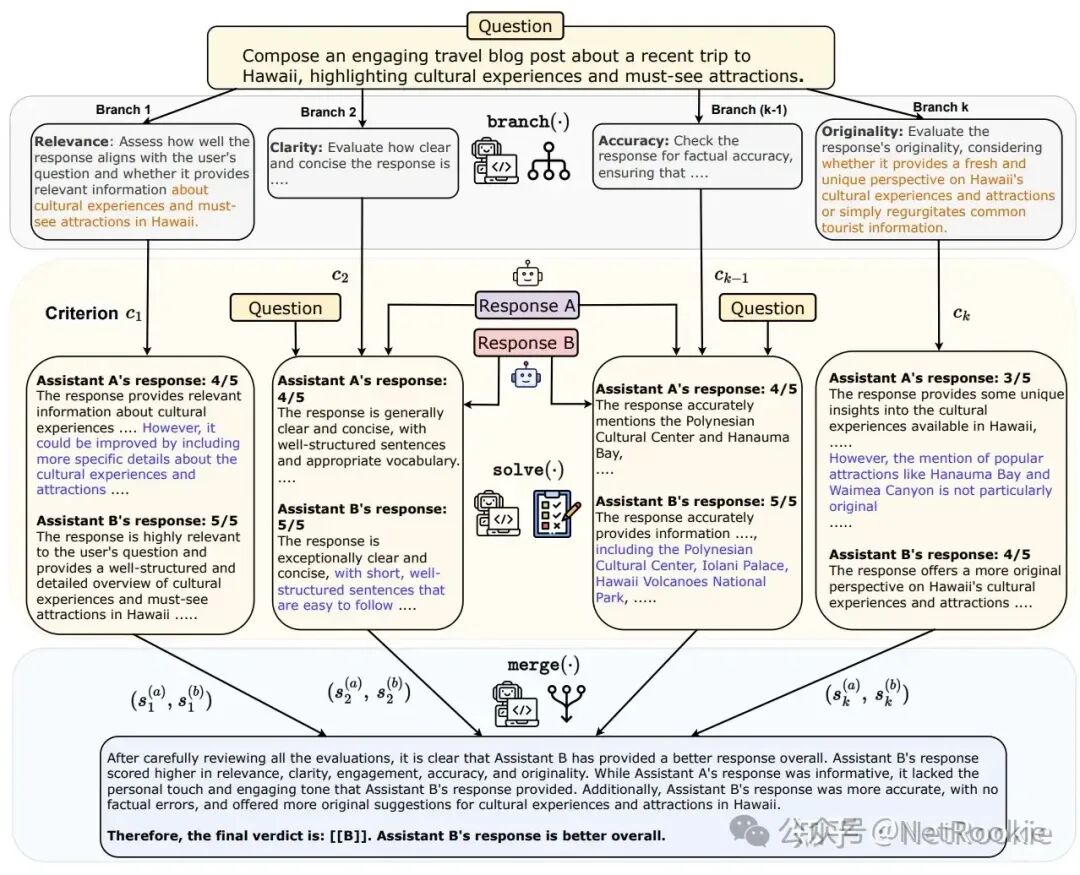
Chain Of Thought Distillation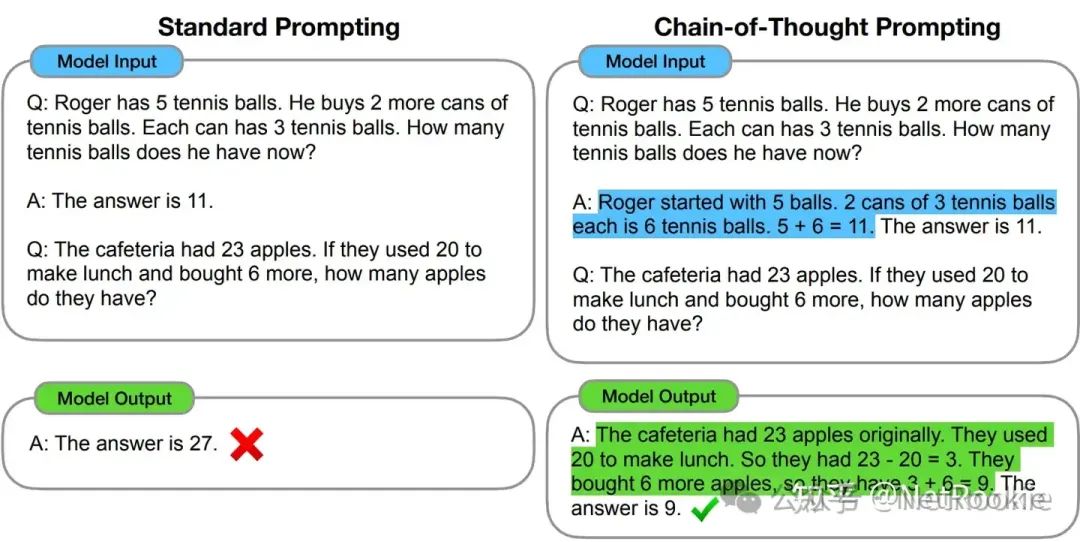
论文通过这四种System2的方式,蒸馏到System1当中,做了很多实验,结果就不一一贴了,都是差的也不会发paper,总结下来,整体是有效的,如RaR蒸馏可用于澄清任务指令相关任务、S2A能有效提升有偏任务,Branch-Solve-Merge蒸馏能作为LLM-Judge评估任务,但是在复杂推理任务上的蒸馏,目前还做得不好。这可能也是一个共识,需要持续研究。 总结,不管是黑盒蒸馏,还是白盒蒸馏,都是现如今非常好的将更大模型的知识注入到较小模型中去的方式,不断提升小模型的知识密度,这样可以再更多的落地场景中应用。期待这个方向后续更多的工作。
|










