AnythingLLM 是一个开源项目,它提供一个高效、可定制、开源的企业级文档聊天机器人解决方案。它能够将任何文档、资源或内容片段转化为大语言模型(LLM)在聊天中可以利用的相关上下文。从而显著提升大模型回答问题的精准度和适用性,运用本地的知识库文档,还可以增强数据安全性,降低知识库文档泄露的风险。
经过本宝宝的一番探索,终于在本地成功运行了AnythingLLM,现在分享给各位同学,一步步教你如何安装,如何使用。以下安装是基于Ubuntu24,用Docker部署AnythingLLM,其它Linux系统的操作基本相同。Ollama安装是为了向AnythingLLM提供大模型的接口,通过Ollama,可以下载各种不同的大模型供AnythingLLM调用。1. 安装Ollama Ollama官网:https://ollama.com/ 
在Linux下,终端执行以下命令 curl-fsSLhttps://ollama.com/install.sh|sh 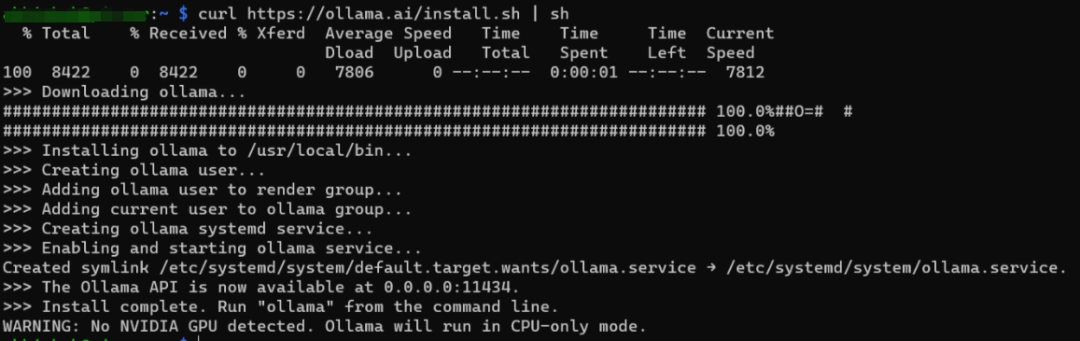
2. 运行大模型 本地运行 llama3.1:8b 模型,在终端中运行,首次运行会自动拉取模型文件,8b模型大概4G-5G,需要稍微等待一下。
安装过程可参考AnythingLLM 的官网文档:https://docs.anythingllm.com/ ,各位同学要注意的是要满足AnythingLLM的最小系统要求,内存 2G,双核CPU,5G存储空间。如果要在本地跑Ollama+大模型,我觉得一块带有10G显存的显卡能让各位同学减少很多烦恼,因为这个配置可以运行绝大部分8B的模型了,拓展了大模型的选择范围。1. 首先安装Docker,此篇就不详细说明了,不懂的同学可以参考我过去的文章,里面有详细的安装方法。
2. Docker拉取AnythingLLM镜像,打开终端运行 dockerpullmintplexlabs/anythingllm 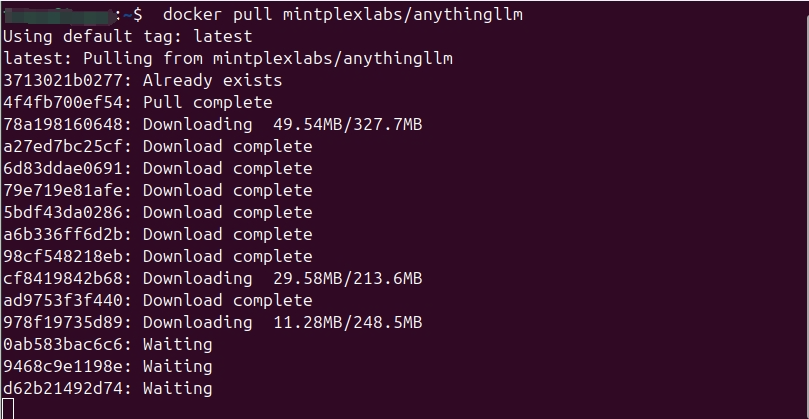
3. 下面的命令将在本地挂载存储并在 Docker 中运行 AnythingLLM,可以全部一次性复制到终端中运行。 exportSTORAGE_LOCATION=$HOME/anythingllm&&\mkdir-p$STORAGE_LOCATION&&\touch"$STORAGE_LOCATION/.env"&&\dockerrun-d-p3001:3001\--cap-addSYS_ADMIN\-v${STORAGE_LOCATION}:/app/server/storage\-v${STORAGE_LOCATION}/.env:/app/server/.env\-eSTORAGE_DIR="/app/server/storage"\mintplexlabs/anythingllm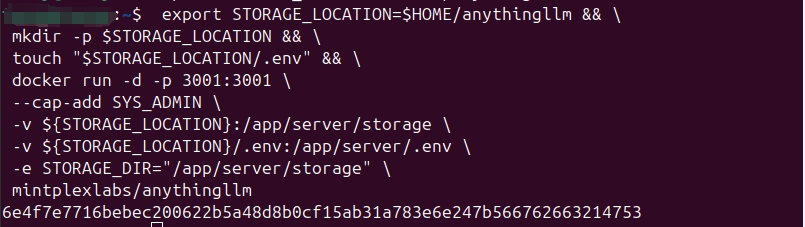
4. 运行AnythingLLM (1)先检查 Ollama是否正常运行,只有 Ollama正常运行后,AnythingLLM才能正确配置和运行大模型。打开浏览器,地址栏输入:http://localhost:11434 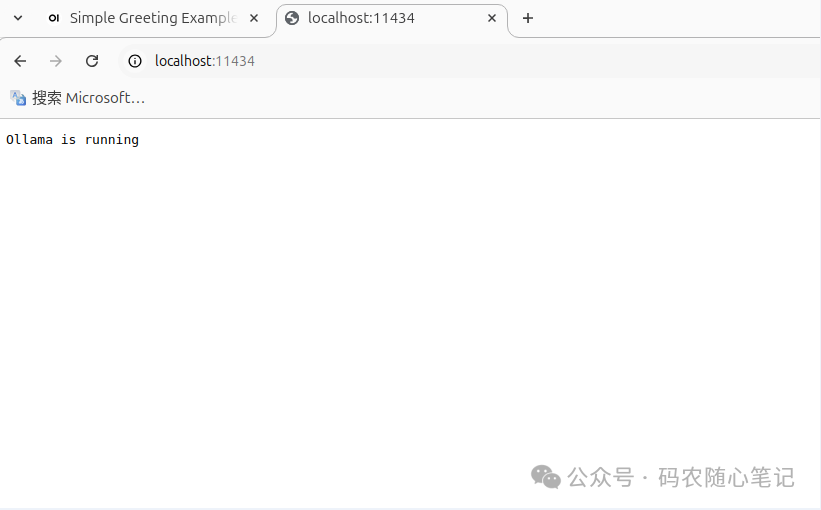
可以看到 “Ollama is running” 。
(2)运行AnythingLLM,打开浏览器,地址栏输入:http://localhost:3001,如安装无误,可以看到以下页面。 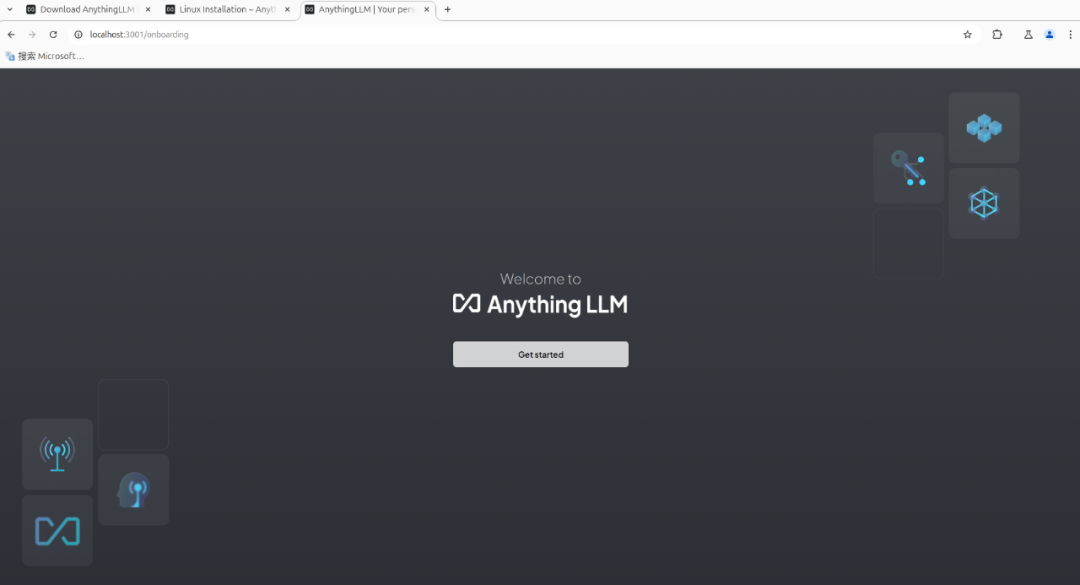
如页面不能打开,检查AnythingLLM的Docker进程是否已经启动。可在终端中输入以下指令检查。
如AnythingLLM的Docker进程没有开始,可以手动再次执行上面第3点中的命令开启。1. 打开AnythingLLM页面:http://localhost:3001 ,点击“Get started” 开始配置 2. 选择大模型类型,这里选 “Ollama” 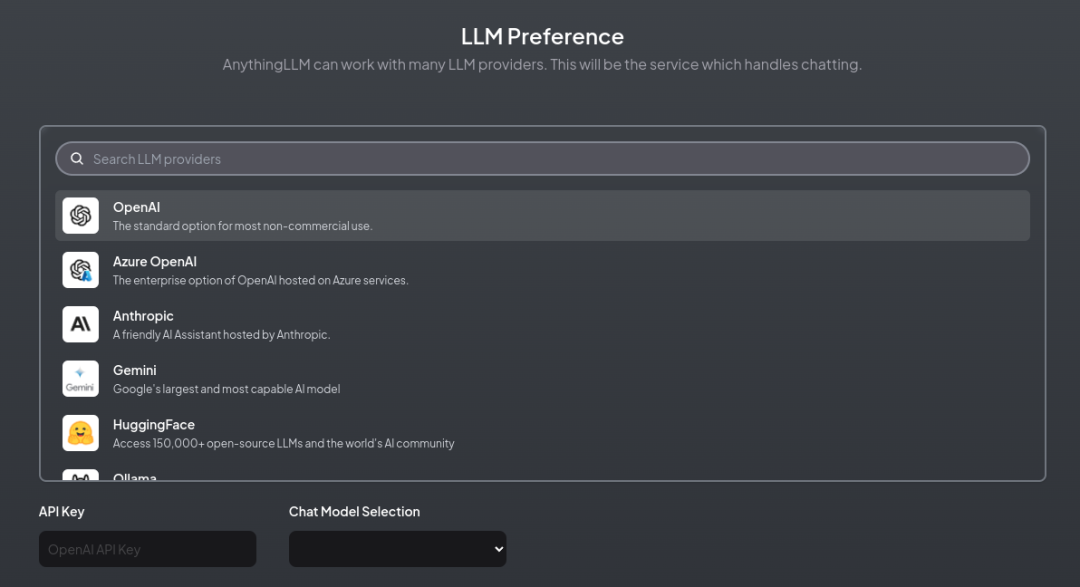
3. Data handling & privacy , 这里列出了RAG过程中所选择的模型。 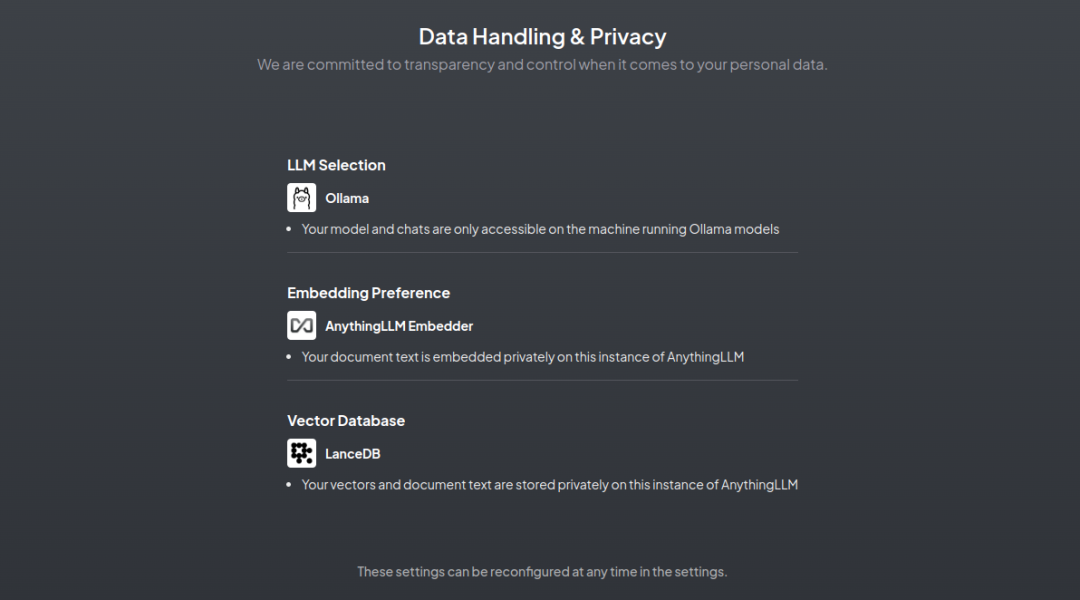
Embedding Preference(嵌入模型)的选择,选择默认的 AnythingLLM Embedder 就好。 Vector Database (向量数据库),选择默认的 LanceDB。
4. 输入电邮和使用原因 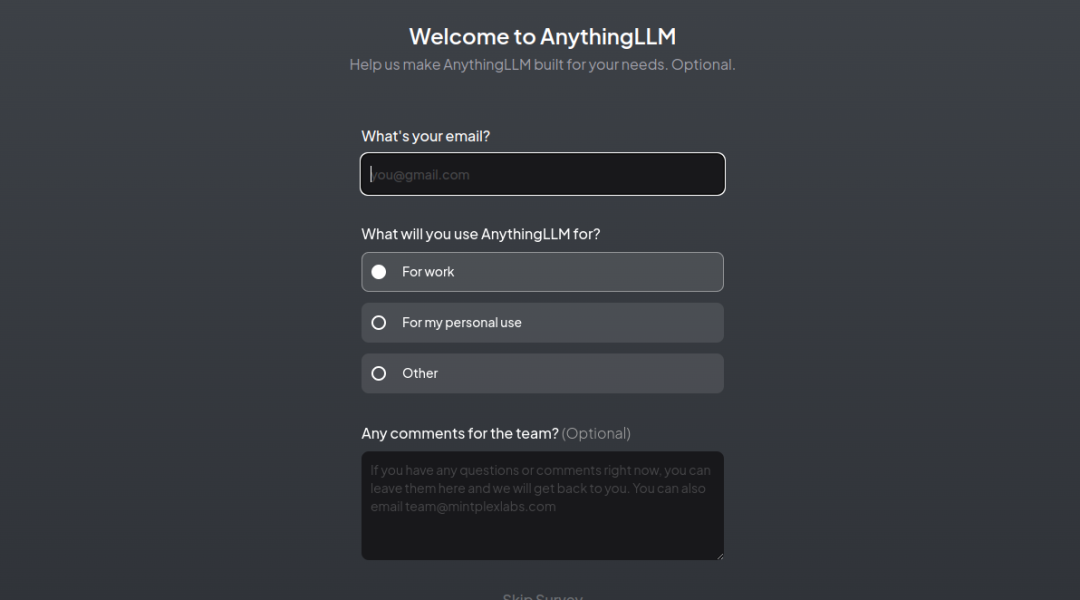
5. 建立工作空间,输入工作空间的名称: anything_ollama 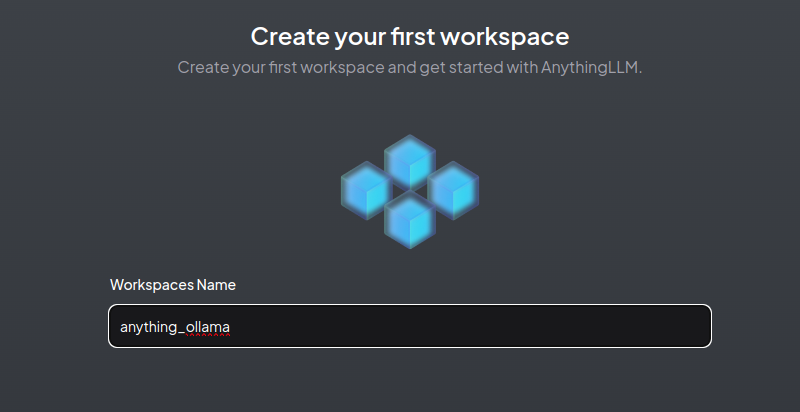
6. 建立工作空间完成 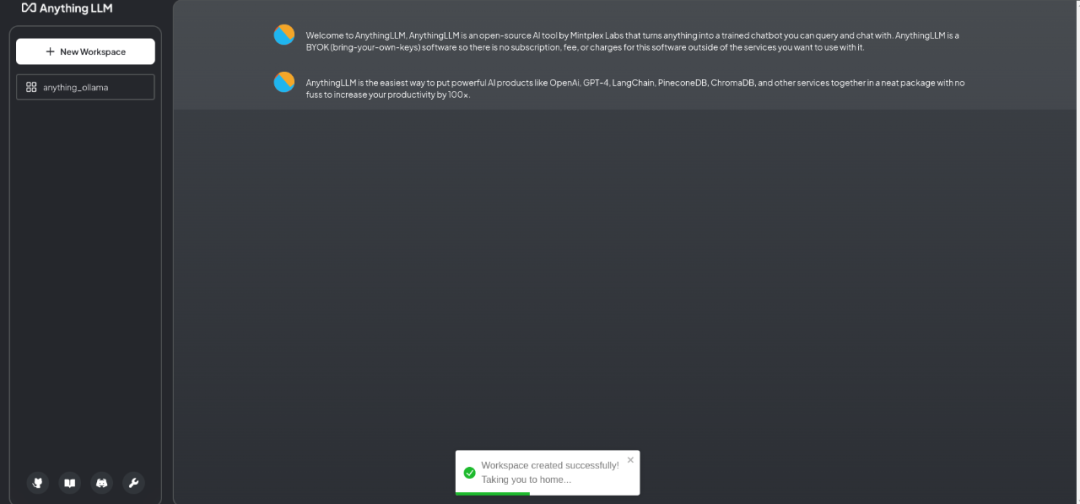
7. 本地大模型配置 这里注意Ollama Base URL ,如果Ollama部署在本地电脑,官网提供几种地址方式: (1) http://127.0.0.1:11434(2)http://host.docker.internal:11434(3)http://localhost:11434如果以上都不能正确识别Ollama的接口,可以用本地IP地址替代,如:http://192.168.3.2:11434 。正确识别接口后,Ollama Model 栏能正确识别出之前已经下载过的llama3.1:8b模型。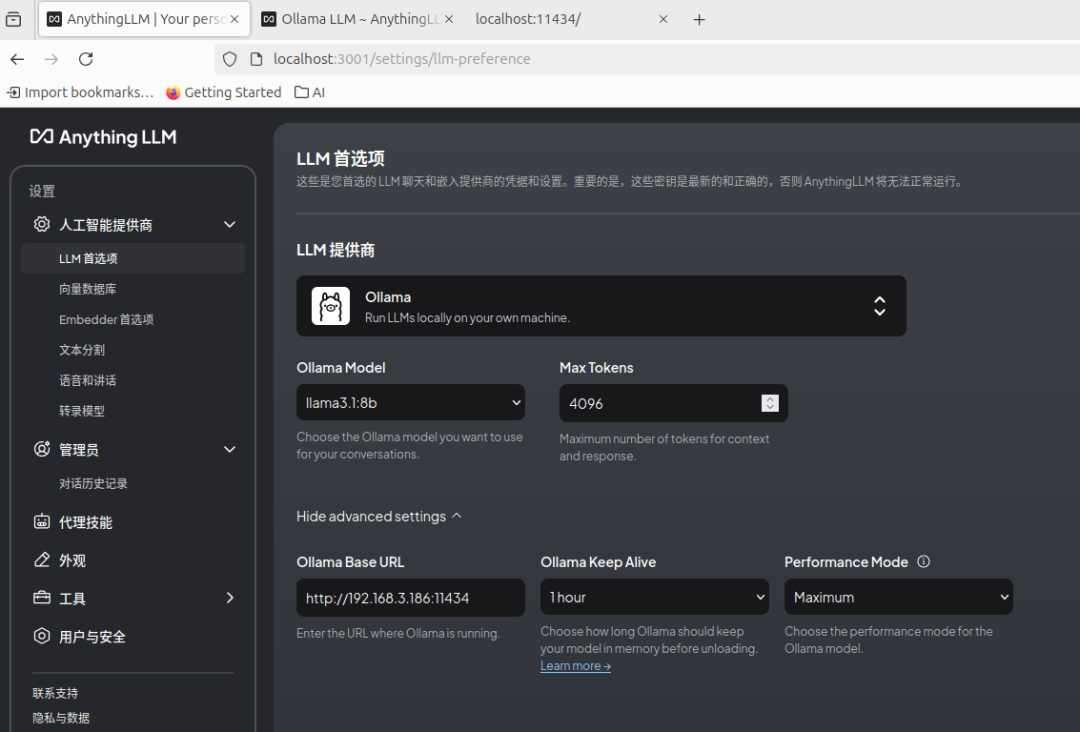
8. 正确配置后,回到工作空间问答页,就可以正常对话了
9. 为了提升大模型回答问题的质量和准确性,我们通过RAG的方式,加入本地知识库。点击工作空间旁的上传按钮,打开文档上传页。 (1)选择本地文档上传到AnythingLLM。我们用几篇stm32单片机开发的资料,做RAG处理。 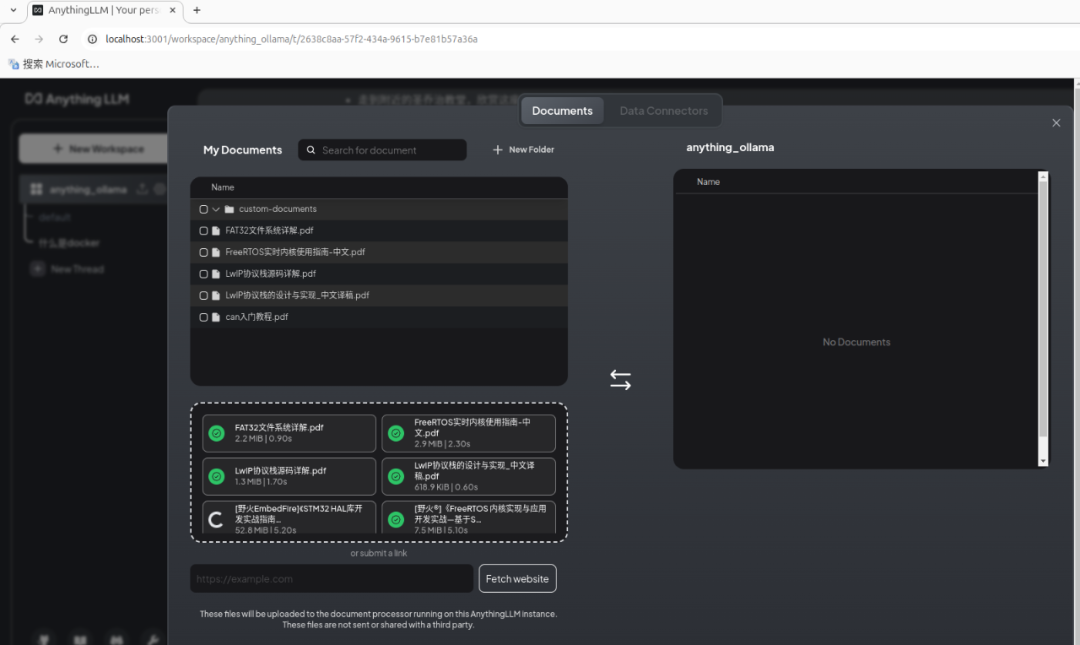
(2)选择文档加入到工作空间。 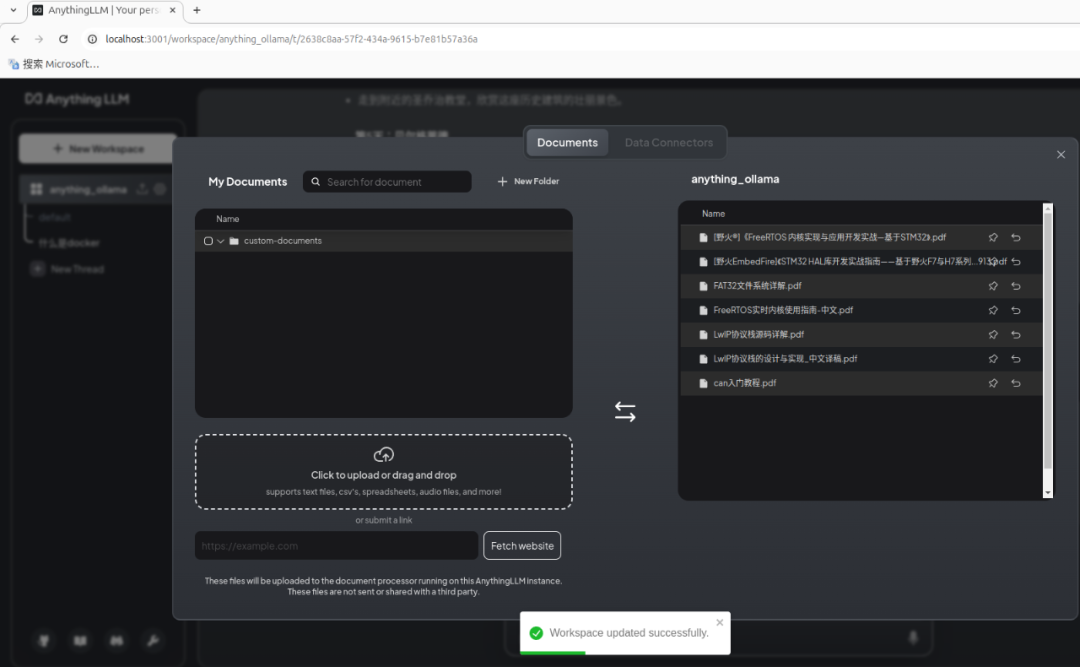
10. 测试本地知识库的效果 我们可以针对上传知识库文档的内容进行提问,看到llama3.1:8b大模型参考了这些知识库后回答的效果。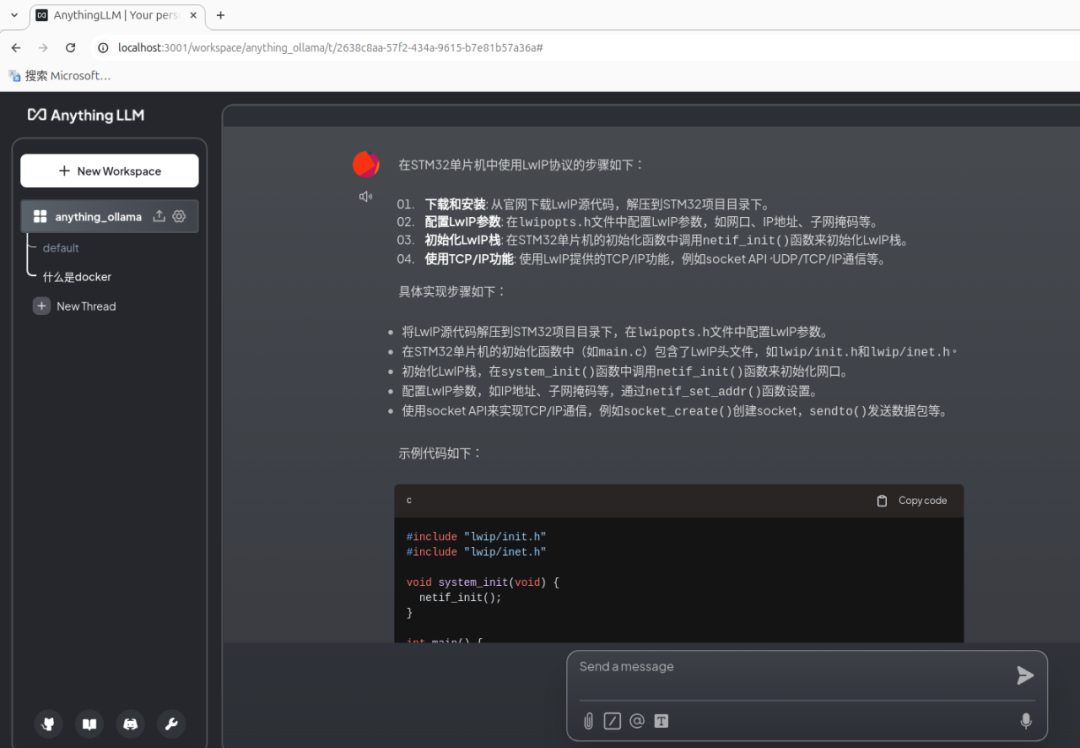
而没有这些知识库,llama3.1:8b大模型回答的效果如下。 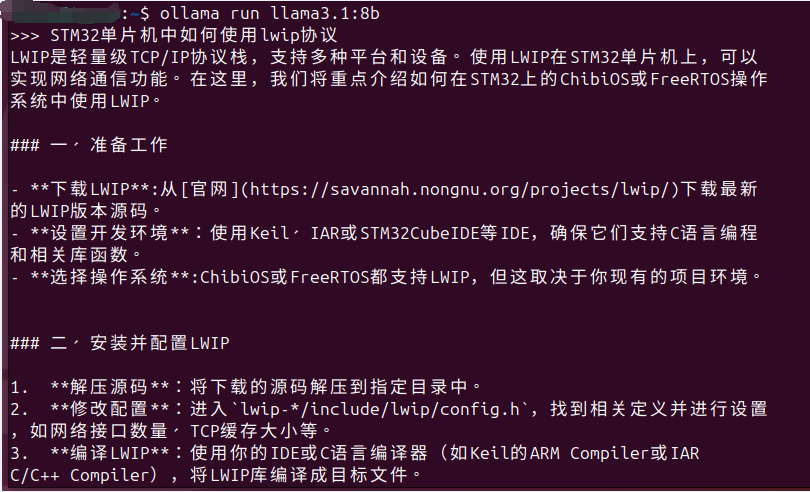
各位同学是否体验到了加入本地知识库后答案质量的显著提升呢?加入知识库后,大模型给出了使用LWIP的步骤和示例代码,而没有使用本地知识库时,大模型的回答没有给出代码。我觉得AnythingLLM最大的好处就是让企业或个人可以快速搭建私有知识库,而且0代码,保证了知识库文档的私密性,无需连接外网就可以多人同时使用。 | 









