|
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin-right: auto;margin-bottom: 1em;margin-left: auto;padding-right: 1em;padding-left: 1em;border-bottom: 2px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">项目结构 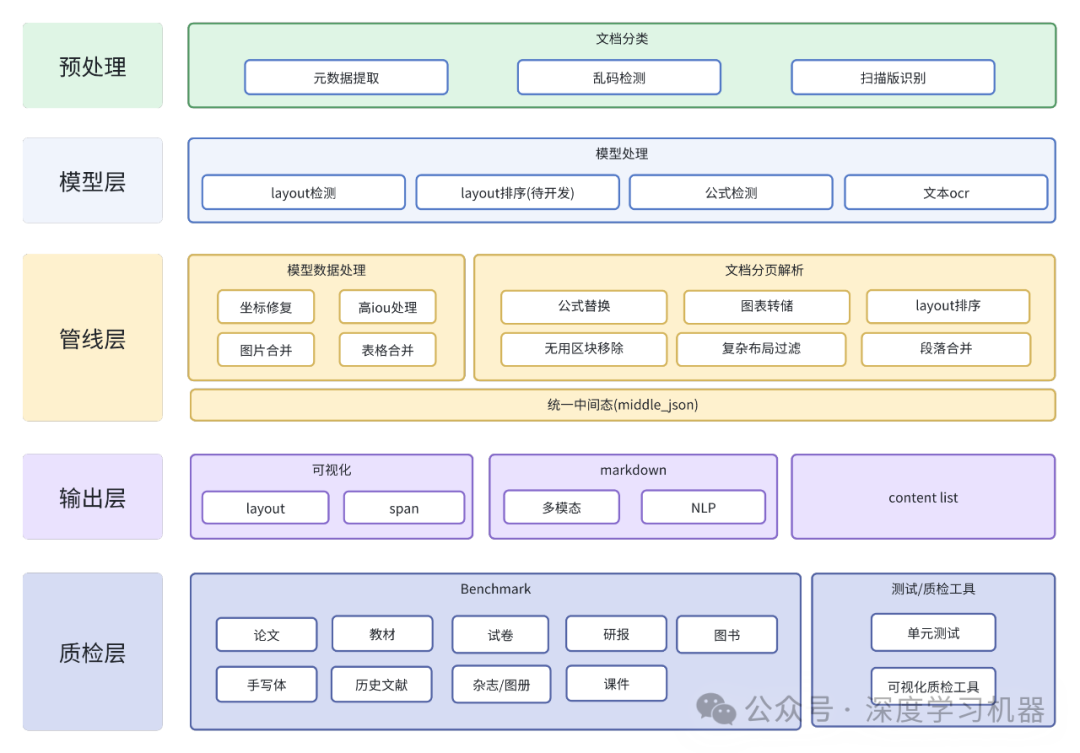
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin: 2em auto 1em;padding-right: 1em;padding-left: 1em;border-bottom: 2px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">流程解析ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">预处理的作用是判断文档内容是否需要进行OCR识别,如果是普通可编辑的PDF文档,则使用PyMuPDF库提取元信息。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">模型层除了常规的OCR、版面结构分析外,还有公式检测模型,可提取公式内容,用于后续把公式转化为Latex格式。但是目前暂无表格内容识别,官方预计1个月之内会放出。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">管线层主要是把上面模型的结果进行加工处理。比如把公式转化为Latex格式、图表保存起来成为图片、把文本框进行排序和合并以及过滤掉无用的信息(页眉、页脚等)。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">输出层其实就是结果文件夹中的内容。结果文件夹中有layout.pdf、span.pdf、xx_middle.json、xx_model.json、xx_content_list.json、xx.md、images文件夹。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;padding-left: 1em;list-style: circle;color: rgb(63, 63, 63);" class="list-paddingleft-2">•layout.pdf 可以看到 版面结构的识别结果 
•span.pdf 可以看到具体每个文本框的内容 
• xx_middle.json 是用OCR或者PDF库解析出的文档元信息,包含文本块类型、内容和坐标。 • xx_model.json 是版面分析结果的内容,包含文本块的类型、坐标和置信度。 • xx_content_list.json 中是文档的类型和具体内容,图表则用img_path指定存放的图片的路径。 
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin: 2em auto 1em;padding-right: 1em;padding-left: 1em;border-bottom: 2px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">实践指南ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">创建一个python环境,建议python3.10以上ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;overflow-x: auto;border-radius: 8px;margin: 10px 8px;">condacreate-nMinerUpython=3.10
condaactivateMinerU接着安装magic-pdf和detectron2这个包 pipinstallmagic-pdf[full-cpu]
pipinstalldetectron2--extra-index-urlhttps://myhloli.github.io/wheels/
magic-pdf--version 注意查看版本是否在0.6.x以上,否则会有问题。英特尔芯片的Mac电脑由于某些库的依赖原因,只能到0.5.x的版本。对于M系列的芯片,经过实测发现不支持mps加速,还是只能使用CPU。
接着下载模型权重:https://huggingface.co/wanderkid/PDF-Extract-Kit 接着把该仓库中的magic-pdf.template.json文件拷贝到本地,修改models-dir为下载到本地的模型路径。 {
"models-dir":"/tmp/models"
}
需要注意的是这个路径是绝对路径
总结优点缺点•硬件支持不够完善,目前存在很多不兼容的情况。M系列芯片暂时无法解决Bug,GPU未测过是否存在其他问题。而用CPU实在是太慢了,10几页的PDF就需要处理约5分钟。 •版面结构进行排序和组合貌似用的全是自定义的规则函数,不太方便开发者进行复用或者微调。 •表格内容暂时无法识别。目前只能把表格部分提取为图片保存起来。
|










