基于LLM的文档对话架构分为两部分,先检索,后推理。重心在检索(推荐系统),推理一般结合langchain交给LLM即可。
因此接下来主要是检索架构设计内容。
1. 检索要求
2. 检索逻辑
拿到需要建立检索库的文本,将其组织成二级索引,第一级索引是 [关键信息],第二级是 [原始文本],二者一一映射。[关键信息]用于加快检索,[原始文本]用于返回给prompt得到结果。
向量检索基于关键信息embeddig,参与相似度计算,检索完成后基于关键信息与原始文本的映射,将原始文本内容作为 {context} 返回。
主要架构图如下:
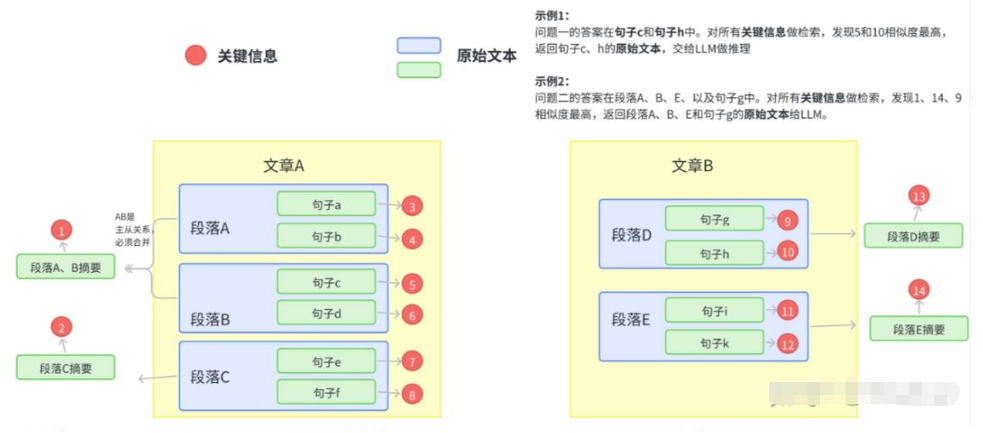
3. 切分与关键信息抽取
关键信息抽取前需要先对拿到的文档进行切分。
其实文档切分粒度比较难把控,粒度过小的话跨段落语义信息可能丢失,粒度过大噪声又太多。因此在切分时主要是按语义切分。
因此拿到文档先切分再抽取关键信息,可根据实际情况考虑是否进行文章、段落、句子更细致粒度的关键信息抽取。
下面具体来讲讲方法和经验:
1)切分
提取出段落之间的主要关系,把所有包含主从关系的段落合并成一段。这样对文章切分完之后保证每一段在说同一件事情。
基于NSP(next sentence prediction)任务。设置相似度阈值t,从前往后依次判断相邻两个段落的相似度分数是否大于t,如果大于则合并,否则断开。
2)关键信息抽取










