引言
在上一节课中,我为大家介绍了 LangChain 的基本知识以及文件导入部分的内容。当文档导入后,我们需要对文档的内容进行处理。大家应该都知道,对于检索增强生成(RAG)系统而言,最关键的是在系统中找到最合适的内容并输出。然而,由于大型语言模型的上下文容量有限,通常不可能将一个文档中的所有内容都输入进去。即便现在有些技术声称可以处理无限长度的内容,但从经济角度来看,更长的上下文意味着更高的计算成本和费用,因此并不划算。
解决这个问题的最佳方法之一是将文件进行切分,将其拆分成若干段。这样做有两大好处:
- 通过 RAG 系统找到的内容在语义上的关联度更高,因此效果会更好。
- 由于切分后的每段内容比整篇文章的字数少得多,所需的计算资源和费用也相应减少。这也是为什么自大型语言模型兴起以来,RAG 技术变得如此流行。
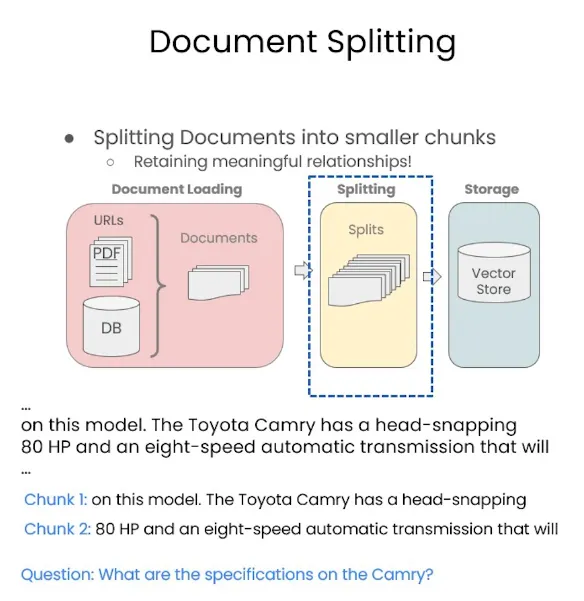
切分方法概述
切分的方法有很多种,这里我们介绍一种最简单的方法——基于字数来切分。例如,chunk_size 表示每块内容的长度为 4000 个 token(字符),而 chunk_overlap 表示上下文重叠部分的长度为 200 个字符。之所以要有重叠部分,是因为每段文本之间都有一定的联系,并不是完全独立的。因此,获取重叠部分的内容相当于保留了一部分上下文信息,从而帮助大型语言模型更好地理解和处理这部分文本。

但是很显然,这样的办法并不是最好的方法。首先就是这种划分就是非常随机的,并不是真的按照语义的方式来进行划分的。其次就是这种上下文的获取也非常的生硬,因此其实很多时候我们会需要用到手工的方式去制作这样的chunk,通过个人的经验和想法找到比较合适的分块方式。那当然人手工的方式成本也非常高,因此langchain里除了最简单的文本分割以外还根据语言、类型的不同给出了更多的划分方式。

实例实践
下面我们就来具体地实践一下LangChain其中的两种切分方法。具体的版本要求如下所示:
langchain0.3.0
langchain-community0.3.0
pypdf5.0.0
openai1.47.0
beautifulsoup44.12.3
我们首先可以通过一个简单的例子来观察文本切分的效果。首先,我们需要从 LangChain 的 text_splitter 模块导入两种常见的切分方式:RecursiveCharacterTextSplitter 和 CharacterTextSplitter。CharacterTextSplitter 是一种直接按照字符串长度进行划分的方法,正如前面图片中所展示的那样。
RecursiveCharacterTextSplitter 更加细致地分割文档,它不仅考虑分割后的文本长度,还会兼顾重叠字符。默认情况下,RecursiveCharacterTextSplitter 使用 ["\n\n", "\n", " ", ""] 四种特殊符号作为分割文本的标记,并按照优先级顺序进行分割:首先尝试在双换行符(\n\n)处分割,然后是单换行符(\n),接着是空格( ``),最后在无法找到合适分割点时强制进行分割。
因此,虽然使用 RecursiveCharacterTextSplitter 分割后的文本长度可能与设定的 chunk_size 不完全一致,但它会更倾向于按照句子或段落的形式来分割文本,从而保持更好的可读性和语义连贯性。
我们可以通过下面的例子来具体展示这两种分割方式的区别。首先,我们有一段文本 some_text。然后,我们配置好对应的 c_splitter 和 r_splitter 的参数,分别设置 chunk_size 为 450 且不设置 chunk_overlap。
fromlangchain.text_splitterimportRecursiveCharacterTextSplitter,CharacterTextSplitter
some_text="""Whenwritingdocuments,writerswillusedocumentstructuretogroupcontent.\
Thiscanconveytothereader,whichidea'sarerelated.Forexample,closelyrelatedideas\
areinsentances.Similarideasareinparagraphs.Paragraphsformadocument.\n\n\
Paragraphsareoftendelimitedwithacarriagereturnortwocarriagereturns.\
Carriagereturnsarethe"backslashn"youseeembeddedinthisstring.\
Sentenceshaveaperiodattheend,butalso,haveaspace.\
andwordsareseparatedbyspace."""
c_splitter=CharacterTextSplitter(
chunk_size=450,
chunk_overlap=0,
separator=''
)
r_splitter=RecursiveCharacterTextSplitter(
chunk_size=450,
chunk_overlap=0,
separators=["\n\n","\n","",""]
然后我们就可以来调用c_splitter来看看运行后的结果:
print(c_splitter.split_text(some_text))
然后我们可以在终端运行文件看到,这段文本被切分为了两块。但是很显然这两块的尺寸差距极大,这主要是因为这段文本本身只有496个字符串,那我们设置的chunk_size是450,对于c_spliter而言,其只考虑字符串的长度,因此将会把这部分文本分为450和46个字符串的两段文本。
['Whenwritingdocuments,writerswillusedocumentstructuretogroupcontent.Thiscanconveytothereader,whichidea\'sarerelated.Forexample,closelyrelatedideasareinsentances.Similarideasareinparagraphs.Paragraphsformadocument.\n\nParagraphsareoftendelimitedwithacarriagereturnortwocarriagereturns.Carriagereturnsarethe"backslashn"youseeembeddedinthisstring.Sentenceshaveaperiodattheend,butalso,'
,'haveaspace.andwordsareseparatedbyspace.']
下面我们也一起来再加上一段代码打印一下r_splitter的结果。
print(r_splitter.split_text(some_text))
我们会发现虽然对比起c_spliter的结果,r_spliter虽然字数上不满足要求,但是确实是按照句子的形式来划分的。划分的地点也是我们看到的第一优先级\n\n的位置。
["Whenwritingdocuments,writerswillusedocumentstructuretogroupcontent.Thiscanconveytothereader,whichidea'sarerelated.Forexample,closelyrelatedideasareinsentances.Similarideasareinparagraphs.Paragraphsformadocument."
,' aragraphsareoftendelimitedwithacarriagereturnortwocarriagereturns.Carriagereturnsarethe"backslashn"youseeembeddedinthisstring.Sentenceshaveaperiodattheend,butalso,haveaspace.andwordsareseparatedbyspace.'
aragraphsareoftendelimitedwithacarriagereturnortwocarriagereturns.Carriagereturnsarethe"backslashn"youseeembeddedinthisstring.Sentenceshaveaperiodattheend,butalso,haveaspace.andwordsareseparatedbyspace.'










