在信息呈指数级增长的当下,传统搜索引擎在应对复杂信息需求时渐显乏力。MindSearch 这款由上海人工智能实验室开发的开源 AI 搜索引擎框架应运而生,犹如一盏明灯,为我们在信息的浩瀚海洋中精准导航,开启智能搜索新时代。
一、MindSearch概述
MindSearch 以开源之姿,向全球开发者与研究者敞开大门。其性能卓越,可与 Perplexity.ai Pro 分庭抗礼,尤其擅长处理长上下文信息,能对超 300 个网页深入剖析整合。它突破传统搜索引擎局限,模拟人类思维搜索信息,深度理解用户意图,经复杂推理与信息融合,给予用户更有深度、广度与相关性的答案,为构建智能高效信息检索生态注入强大动力。
二、技术原理
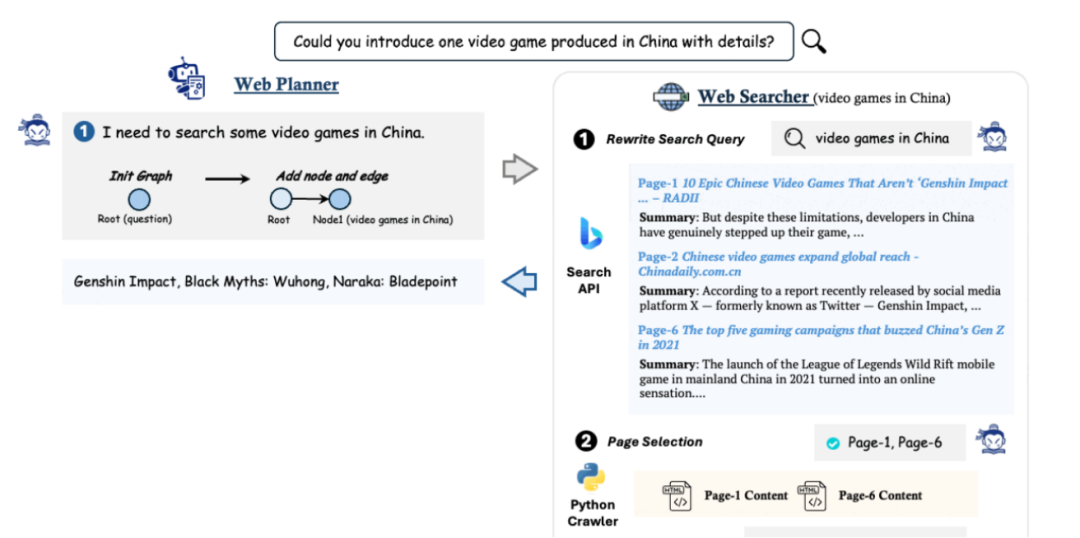
1、WebPlanner:智能规划中枢
WebPlanner 是 MindSearch 的智慧大脑,它把搜索任务构建成有向无环图(DAG)。接收用户问题后,凭借语言模型代码生成能力,用预定义原子代码函数拆解问题为子问题节点,勾勒出问题解决框架。在搜索进程中,依据 WebSearcher 反馈,灵活延展与细化此图,动态调整策略,引领系统精准挖掘信息。比如面对“人工智能在医疗影像诊断中的应用现状与挑战”的问题,它会拆解出医疗影像类型、人工智能算法应用实例、面临的数据隐私与解读准确性等子问题,为全面解答铺设道路。
2、WebSearcher:信息挖掘尖兵
WebSearcher 则勇当信息挖掘先锋。采用粗到细策略,先优化查询关键词提升精度,聚合海量搜索内容剔除冗余,精准筛选关键页面,再深度总结提炼。借助语言模型理解与整合碎片化信息,将其转化为逻辑连贯的知识模块。以搜索“新能源汽车电池技术突破”为例,它能迅速从科研机构报告、行业新闻、企业官网等资源里,筛选出电池能量密度提升、充电速度加快等关键信息并整理呈现。
三、功能特点
1、深度知识萃取
MindSearch 可深入挖掘众多网页,为用户呈现深度知识。无论是探索古老文明奥秘,还是追踪前沿科技动态,它都能从海量网络资源中梳理脉络。如查询“宇宙暗物质研究进展”,它不仅提供基础概念,还能汇总最新观测数据、理论模型以及全球科研团队的阶段性成果,助用户构建系统知识体系。
2、搜索路径透明化
区别于传统搜索引擎,MindSearch 向用户展示思考路径、搜索关键词与信息整合流程。用户查询“法律条文释义”时,除答案外,还能知晓其从法律数据库、专业论坛及案例分析中筛选整合信息的过程,增强信任度的同时,便于用户深入学习研究,提升相关知识水平。
3、多界面适配
考虑到不同用户需求,MindSearch 提供 React、Gradio、Streamlit 和本地调试等多种界面。开发者可借 React 界面将其融入 Web 应用;普通用户则可通过 Gradio 或 Streamlit 界面便捷查询,无需复杂编程与环境配置,降低使用门槛,提升用户体验。
4、动态图构建机制
其动态图构建功能可依用户查询生成子问题节点,依据搜索结果实时拓展。面对热点话题如“社交媒体对青少年心理健康的影响”,能及时结合新研究、新事件更新搜索图,灵活调整方向,确保提供最新最相关信息。
四、应用场景
1、学术研究好帮手
在学术领域,MindSearch 为研究者大幅缩短信息收集时间。如历史学者研究特定历史时期文化交流,它可整合古籍文献、考古报告、学术论文等资源,梳理交流脉络与重要事件,助力学者快速定位关键信息,明确研究方向,提高研究效率。
2、创作灵感启发器
对于创作者,MindSearch 是灵感源泉。文案撰写者创作旅游文案时,可搜索目的地特色美食、小众景点、民俗风情等素材,经整合加工成引人入胜的文案。影视编剧创作科幻剧本时,能从中获取新颖科幻概念、未来场景设定等灵感素材,丰富创作内容。
3、商业决策指南针
商业领域中,企业可利用 MindSearch 监测市场趋势、分析竞品动态、洞察消费者需求。例如餐饮企业制定新品策略时,可搜索市场流行食材、竞品热门菜品、消费者口味偏好等信息,综合研判后推出契合市场需求的新品,增强市场竞争力。
五、快速使用
1、依赖安装
首先,确保你的系统已经安装了Python环境(推荐Python 3.8及以上版本)。然后,在命令行中进入MindSearch项目的根目录,执行以下命令安装所需的依赖项: pipinstall-rrequirements.txt 这一步骤将自动下载并安装MindSearch运行所需的各种Python库和模块,为后续的启动和使用做好准备。
2、启动MindSearch API
在依赖安装完成后,就可以启动MindSearch API了。使用以下命令启动FastAPI服务器: python-mmindsearch.app--langen--model_formatinternlm_server--search_engineDuckDuckGoSearch 在这里,你可以根据实际需求对参数进行调整:
`--lang`:用于指定模型的语言,例如`en`表示英语,`cn`表示中文。请根据你期望的输入语言和搜索结果语言进行选择。
`--model_format`:指定模型的格式,如`internlm_server`表示使用InternLM2.5 - 7b - chat本地服务器模型;若你想使用其他模型,例如GPT4,则需要将其修改为`gpt4`,同时确保你已经正确配置了相应模型的访问和使用权限。
`--search_engine`:用于选择搜索引擎,MindSearch支持多种搜索引擎,如 `DuckDuckGoSearch`(DuckDuckGo搜索引擎)、`BingSearch`(Bing搜索引擎)、`BraveSearch`(Brave搜索引擎)、`GoogleSearch`(Google Serper搜索引擎)、`TencentSearch`(Tencent搜索引擎)等。如果选择除DuckDuckGo和Tencent以外的网页搜索引擎,你需要将对应的API密钥设置为`WEB_SEARCH_API_KEY`环境变量;若使用Tencent搜索引擎,还需要额外设置`TENCENT_SEARCH_SECRET_ID`和`TENCENT_SEARCH_SECRET_KEY`。
3、启动MindSearch前端
MindSearch提供了多种前端界面供用户选择,以下是不同前端界面的启动方式:
3.1 React
1. 首先,需要配置Vite的API代理,指定实际后端URL。假设后端服务器运行在本地`127.0.0.1`的`8002`端口(请根据实际情况修改),执行以下命令: HOST="127.0.0.1" ORT=8002sed-i-r"s/target:\s*\"\"/target:\"${HOST} ORT=8002sed-i-r"s/target:\s*\"\"/target:\"${HOST} {PORT}\"/"frontend/React/vite.config.ts {PORT}\"/"frontend/React/vite.config.ts 2. 确保你的系统已经安装了Node.js和npm。对于Ubuntu系统,可以使用以下命令安装: 对于Windows系统,你需要从[Node.js官方网站](https://nodejs.org/zh-cn/download/prebuilt-installer)下载并安装适合你系统的Node.js版本。
3. 进入`frontend/React`目录,执行以下命令安装项目依赖并启动React前端: cdfrontend/Reactnpminstallnpmstart 3.2 Gradio
在命令行中执行以下命令启动Gradio前端: pythonfrontend/mindsearch_gradio.py 3.3 Streamlit
使用以下命令启动Streamlit前端: streamlitrunfrontend/mindsearch_streamlit.py 3、本地调试
如果你希望在本地进行调试,可以使用以下命令: pythonmindsearch/terminal.py 通过本地调试,你可以更方便地检查和优化MindSearch在你本地环境中的运行情况,查看详细的日志信息,以便及时发现和解决可能出现的问题。
结语
MindSearch 以其独特技术、丰富功能与多元应用场景,在信息检索领域掀起创新浪潮。它提升用户信息获取效率与质量,为开发者搭建创新平台,推动 AI 搜索引擎技术发展。于学术、创作、商业等多领域皆具巨大潜力与价值。相信在未来,MindSearch 将持续进化,助力我们更高效探索知识宇宙,畅享智能信息检索新体验。
项目地址
官方网站:https://mindsearch.netlify.app/ 代码仓库:https://github.com/InternLM/MindSearch | 









