|
功能概述- 从知识库中检索与用户问题相关的文本内容,作为下游 LLM 节点的上下文
- 应用场景:构建基于外部数据/知识的 AI 问答系统(RAG)
基础应用流程用户问题 → 知识库检索 → 召回相关文本 → LLM 生成回答
典型示例:知识库问答应用 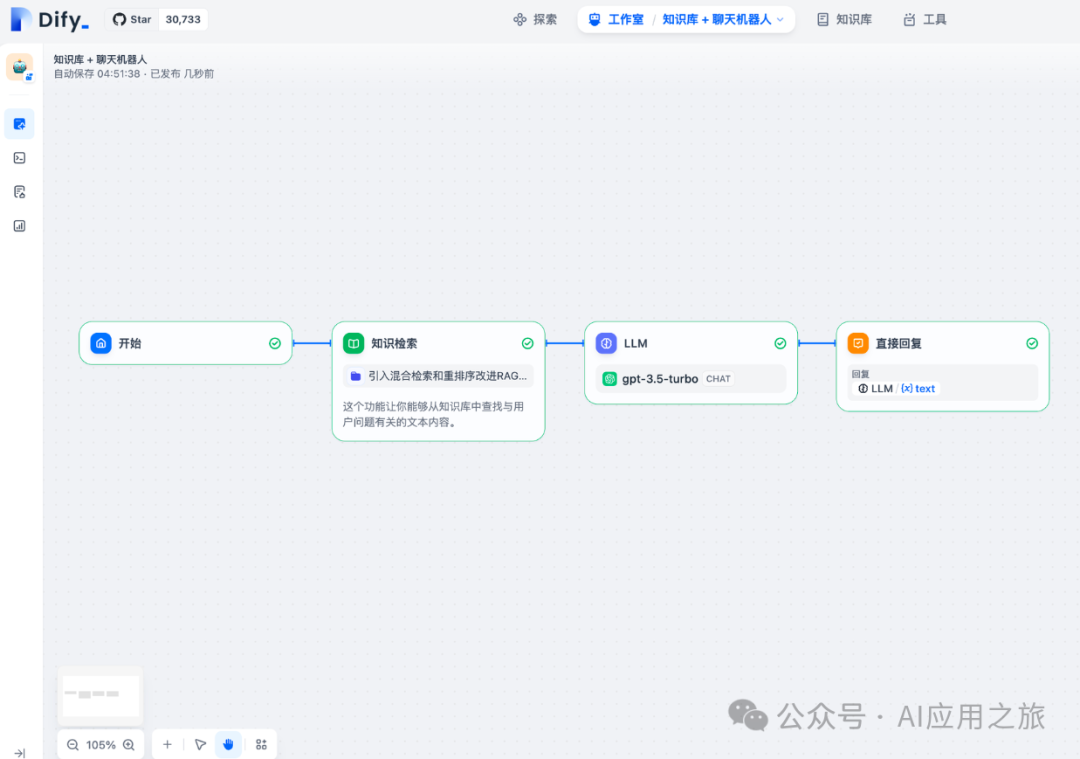 配置指引1. 查询变量配置- 选择代表用户问题的查询变量(通常为
sys.query)
2. 知识库选择3. 召回模式4. 下游节点连接输出变量说明{
"result": {
"content":"检索到的文本分段",
"title":"分段标题",
"link":"原文链接",
"icon":"标识图标",
"metadata":"附加元数据"
}
}
下游节点配置规范
- 将
result变量绑定到 LLM 节点的上下文变量

- 有检索结果时:上下文变量值自动填充,LLM 基于知识库内容回答
- 无检索结果时:上下文变量为空,LLM 直接回答问题

提示:该配置方案同时支持知识增强和原始知识归属展示,建议在提示词中设计合理的知识引用格式。
Dify→问题分类 | 通过定义分类描述,问题分类器能够根据用户输入,使用 LLM 推理与之相匹配的分类并输出分类结果,向下游节点提供更加精确的信息。 场景
常见的使用情景包括: 在一个典型的产品客服问答场景中,问题分类器可作为知识库检索的前置步骤,对用户输入问题意图进行分类处理,分类后导向下游不同的知识库查询相关的内容,以精确回复用户的问题。 示例工作流模板
下图为产品客服场景的示例工作流模板: 应用示例
当用户输入不同问题时,分类器会根据已设置的分类标签/描述自动完成分类: - “iPhone 14 如何设置通讯录联系人?” →“与产品操作使用相关的问题”
如何配置 
- 选择输入变量:指用于分类的输入内容,支持输入文件变量。客服问答场景下一般为用户输入的问题
sys.query。 - 选择推理模型:基于大语言模型的自然语言分类和推理能力,选择合适的模型以提升分类效果。
- 编写分类标签/描述:手动添加多个分类,通过编写关键词或描述语句帮助大语言模型理解分类依据。
- 选择下游节点:根据分类结果与下游节点的关系,选择后续流程路径。
高级设置 - 指令:在高级设置中补充附加指令(如更丰富的分类依据),增强分类能力。
- 记忆:开启后,输入将包含聊天历史以提升对话交互中的问题理解能力。
- 图片分析:仅适用于具备图片识别能力的LLM,允许输入图片变量。
- 记忆窗口:关闭时,系统根据模型上下文窗口动态过滤聊天历史;开启时可精确控制传递数量(对数)。
输出变量 class_name:存储分类模型的预测结果。分类完成后,此变量包含具体类别标签,可在后续处理节点中引用以执行相应逻辑。
| 









