|
前几天知识星球中有个提问,关于 RAGFlow 的聊天助手回答引用文件是 markdown 格式时,如何跳转进行预览的实现问题。 目前在 RAGFlow 的聊天助手中,如果引用文件格式是 pdf 和 docx,是可以直接点击跳转打开新的标签页进行预览的,不过暂时确实不支持 markdown 格式。早在今年 2 月份,在 RAGFlow 的 Github issue 上,就有一个关于“回答中引用的 MD 文档无法原生预览”的讨论(#4979)。但是目前并没有官方或者其他开发者给出解决方案。不过既然是前端显示问题,那就没什么是一个油猴脚本解决不了的。 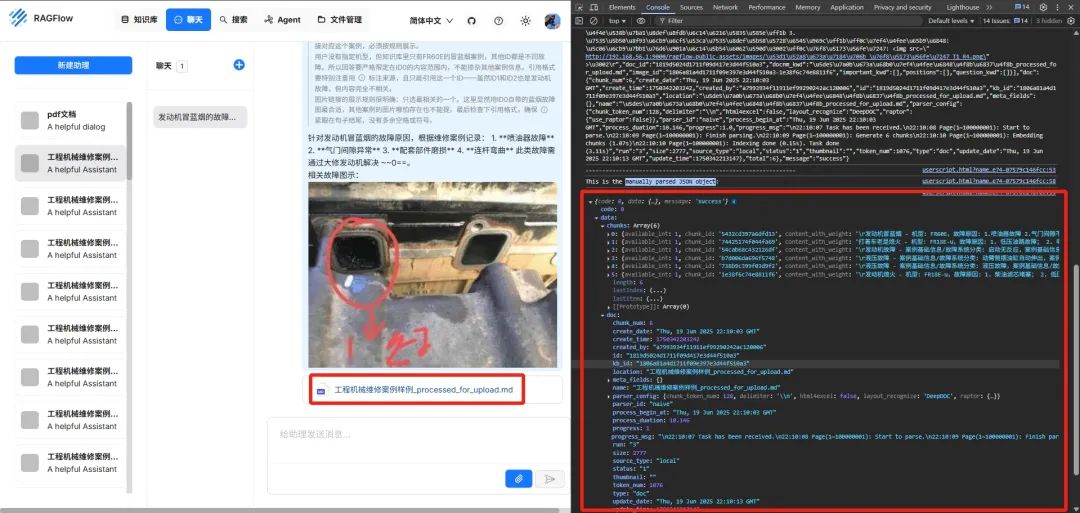
这篇试图说清楚: 如何通过利用油猴脚本的脚本注入和跨域请求能力,拦截用户对 .md 链接的点击,通过调用 RAGFlow 的内部 API 获取原始数据,并动态生成一个预览页面;以及在实现上述过程中踩到的坑与迭代方向参考。 以下,enjoy: 1 需求场景分析 在追求高精度问答的实际落地场景中,对于企业知识库中充斥的格式各异、布局复杂的文档,比如跨越多栏的 PDF 报告、包含复杂嵌套表格的 Word 文档、或是图文混排的产品手册。直接把这些原始文档投喂给任何 RAG 系统,都可能面临“Garbage In, Garbage Out”的问题。 而 Ragflow 自带的 DeepDoc 或者使用 MinerU 解析器虽然强大,但面对这些“脏数据”的时候,也难免会产生语义不连贯、上下文割裂的文本块,这会直接影响检索的准确性和最终生成答案的质量。 1.1 预处理的主要做法 为了确保送入 RAG 管道的数据是高质量的,文档预处理几乎是所有严肃 RAG 应用中不可或缺的一步。这一步不只是简单的格式转换,更是一个结合文档特点进行结构化重塑过程。核心目标包括: 通过定制化的脚本(如 Python 脚本结合 PyMuPDF, python-docx 等库)进行预处理,可以把一份原始复杂的文档,清洗并转化为一份干净结构化的中间格式。 1.2 为什么选择 Markdown 作为中间格式? 为了更加直观的对比常见的四种中间格式的适用情形,下面结合这个表格来一起看一下: | | | | |
|---|
| 极低。丢失所有标题、列表、表格等结构,退化为纯文本流。 | 良好。能通过简单标记保留标题层级、列表、代码块等核心语义。 | | 灵活可定义。可以将内容和元数据以任意复杂的结构进行组织。 | | 中等。文本干净,但缺乏结构会影响 LLM 对上下文层次的理解。 | 高。LLM 对 Markdown 有天生的理解力,结构标记有助于理解上下文。 | 中等。标签本身是噪音,若不经清洗会严重干扰嵌入质量。需要额外处理。 | 高(指 JSON 中的文本值)。需要程序解析后将干净文本喂给模型。 | | | | | 低。是为机器设计的格式,人类难以直接阅读长篇内容。 | | | 中等。需要编写逻辑将文档结构(如 Word 的 Heading 1)映射到 MD 标记(#)。 | 高。要生成干净、有效的 HTML,需要复杂的转换逻辑和严格的 XSS 过滤。 | 高。需要为数据定义清晰的 schema(模式),并进行序列化。 | | | 有限。可以通过 YAML Front Matter 注入,但不是原生标准。 | 优秀。可以通过 data-* 属性将元数据与具体元素绑定。 | | | 适用简单场景:用于处理纯散文、无结构的文章,追求极简。 | 平衡之选:最适合需要保留核心结构且兼顾人机可读性的场景。 | 追求高保真:当需要复现复杂表格或布局,且不惜处理成本时使用。 | 系统化管道:用于需要精细控制、携带大量元数据的自动化、工程化 RAG 流程。 |
从上表可以看出来,其实并不存在“最好”的格式,只有“最适合”的场景。而之所以在许多实践中倾向于选择 Markdown,是因为它在 “保留关键结构”、“模型友好度”和“人类可读性(易于调试)” 这三个对维度上取得了很好的平衡。 注:针对更为复杂的的表格或页面布局建议还是使用 html 格式,这部分内容预计 7 月初我会在结合历史文章中提到的 IBM 的 RAG 冠军赛项目复现文章中进行具体介绍。 IBM RAG挑战赛冠军方案全流程复盘 (附源码地址) 2 实现原理解析 这个流程图展示了 RAGFlow 的聊天助手中,引用文件是 Markdown 时的预览功能完整实现机制。通过 MutationObserver 实时监听聊天界面的 DOM 变化,自动为 .md 文件链接绑定自定义点击事件,当用户点击时拦截默认跳转行为并创建新标签页,同时从链接中提取文档 ID 并读取认证凭据,通过 GM_xmlhttpRequest 向后端/v1/chunk/list接口请求文档数据,最后利用 marked.js 库解析 JSON 响应中的内容块,动态构建并渲染格式化的 HTML 页面,实现了无侵入式的文档预览功能增强。整个流程采用异步处理和错误处理机制,确保使用的流畅性和系统稳定性。 3 核心模块拆解 3.1 动态事件监听与触发 由于 Ragflow 是一个现代化的单页应用 (SPA),其聊天内容是动态加载到页面中的。传统的页面加载事件无法监听到这些后续出现的内容。因此,脚本的核心入口采用了 MutationObserver API。 实现逻辑 初始化一个 MutationObserver 实例,配置它来监视 document.body 及其所有后代节点 (subtree: true) 的添加或删除 (childList: true)。 当监听到有新节点被添加到页面时,脚本会遍历这些节点,并使用 querySelectorAll 高效地查找其中所有指向 .md 文件的 (这里有个东西)链接。 为了避免重复绑定,脚本为每个处理过的链接添加了一个 data-md-preview-handled 属性作为标记。如果链接未被标记,则为其 click 事件绑定核心处理函数 processMarkdownLink。 关键函数说明 new MutationObserver(callback): 创建一个观察者对象,当指定的 DOM 变化发生时,执行回调函数。这是应对动态网页内容变化的不二之选。 observer.observe(targetNode, options): 启动观察者。{ childList: true, subtree: true } 是性能和功能之间的完美平衡,确保了不会错过任何动态添加的链接。 3.2 核心处理流程 当用户点击目标链接后,这个函数会被触发,并按序执行一系列操作。 实现逻辑 即时响应与阻止默认:立刻调用 event.preventDefault() 和 event.stopPropagation(),阻止浏览器执行默认的、无法预览的跳转行为。同时,window.open() 打开一个新标签页并显示“加载中”,给予用户即时反馈。 信息采集:通过正则表达式从链接的 href 属性中精确提取出 doc_id。随后,从浏览器的 localStorage 中获取 Authorization Token,这是后续与后端 API 进行认证通信的关键凭证。 关键函数说明 event.preventDefault(): 阻止事件的默认动作,此处即阻止链接跳转。 window.open('', '_blank'): 打开一个新窗口,并保留其句柄(tempWindow),以便后续向其写入内容。 localStorage.getItem('Authorization'): 从浏览器本地存储中获取身份验证令牌。脚本的运行环境与 Ragflow 页面相同,因此可以直接访问。 3.3 后端数据安全交互 获取到必要信息后,脚本需要与 Ragflow 的后端进行通信,以拉取文档的完整内容。 实现逻辑 利用油猴提供的 GM_xmlhttpRequest 发起一个 POST 请求到 Ragflow 的 /v1/chunk/list API 端点。 请求头中必须包含 Content-Type 和从 localStorage 中获取的 Authorization Token。 请求体是一个 JSON 对象,包含了需要查询的 doc_id 和一个较大的 limit 值,以确保能一次性获取所有内容块 (chunks)。 通过设置 onload、onerror 和 ontimeout 回调函数,对请求的成功、失败和超时情况进行全面处理。 关键函数说明 GM_xmlhttpRequest(details): 油猴的特权 API,可以突破同源策略 (CORS) 的限制,是实现该功能的核心。脚本头部的 @connect localhost 和 @connect 127.0.0.1 就是在为此 API 授权。 JSON.stringify(payload): 将 JavaScript 对象序列化为 JSON 字符串,作为请求体发送。 3.4 前端动态渲染与呈现 这是把枯燥的数据转化为美观页面的最后一步,也是用户最终能感知到的部分。 实现逻辑 数据解析:在 onload 回调中,脚本首先解析 API 返回的 JSON 数据,分离出文档的元数据 (doc) 和内容块数组 (chunks)。 HTML 结构构建:脚本使用模板字符串动态生成一个完整的 HTML 页面结构。这包括: 一个美观的头部,包含文档标题。 一个展示文档 ID、创建时间等信息的“元数据卡片”。 遍历 chunks 数组,为每个内容块创建一个独立的“内容卡片”。一个巧妙的设计是,每个块的原始 Markdown 内容被存储在一个隐藏的 <textarea>中,这可以防止浏览器错误地解析其中的特殊字符。 集成 Markdown 解析器:在生成的 HTML 的<head>部分,通过 CDN 引入了轻量且强大的 marked.js 库。 最终渲染:页面主体包含一段内联的<script>。它在 DOMContentLoaded 事件触发后执行,遍历所有的内容卡片,读取隐藏<textarea>中的 Markdown 原文,使用 marked.parse() 将其转换为 HTML,最后注入到对应的容器中,完成最终的渲染。 写入页面:调用 tempWindow.document.write(),将整个拼接好的 HTML 字符串写入之前打开的新标签页中,浏览器会解析并展示这个页面。 关键函数说明 marked.parse(markdownString): marked.js 库的核心函数,将传入的 Markdown 格式字符串转换为 HTML 字符串。 tempWindow.document.write(html): 向指定窗口的文档流中写入数据。这是动态创建整个页面的关键。 4 填过的这些坑 4.1 链接与弹窗的直接对抗 我最开始的想法是拦截链接的点击事件,直接使用 fetch 请求链接地址,然后将获取到的文本内容放入一个自己创建的弹窗中显示。但是发现弹窗成功弹出,但里面是空的。 通过 F12 开发者工具的“控制台”和“网络”面板发现,请求链接返回的是整个 Ragflow 应用的 HTML 主页面。这是第一个碰到的障碍:单页应用(SPA)的路由机制。就是服务器被配置为将所有无法直接匹配的路径都重定向到应用的入口 index.html,由前端 JavaScript 来接管后续的路由和数据加载。这说明最初的脚本从一开始就敲错了门。 4.2 寻找真正的 API 既然直接请求链接行不通,那一定有一个隐藏的、真正用来获取文件内容的 API 接口,这就要通过监视 Ragflow 自身的网络请求来找到它。 通过在知识库页面操作,成功的在“网络”面板捕获到了一个形如 /v1/chunk/list 的 API 请求。但是当脚本去请求这个新发现的 API 时,服务器却返回了“401 未授权”的错误。测试下来发现其实是两层防御问题需要克服下: 第一层防御:HttpOnly Cookie 最初尝试用 document.cookie 手动附加 Cookie,但失败了。这意味着最关键的登录凭证被存储在 HttpOnly Cookie 中,JavaScript 无法读取。 第二层防御:授权令牌 (Authorization Token) 即使让油猴脚本自动携带 Cookie,请求依然失败。最后发现,Ragflow 使用了更安全的 Token 认证机制。真正的“通行证”不是 Cookie,而是一个存储在 localStorage 中的、名为 Authorization 的令牌,它必须被放在请求头中发送。 4.3 与前端框架的终极博弈 在拥有了所有正确的钥匙(API 地址、请求方法、认证令牌、请求参数),成功获取到了包含 Markdown 内容的 JSON 数据。现在只需要将它显示出来即可。但是弹窗就是无法稳定地显示在页面上。有时会闪现一下,有时干脆没有任何反应,控制台也没有任何错误。 通过使用 debugger 冻结时间的方式发现,弹窗确实被成功添加到了页面上,但几乎在同一瞬间就被 Ragflow 的前端框架(React)给“净化”或移除了,因为它不属于框架管理的“虚拟 DOM”结构。这个算是碰到了现代前端框架最核心的壁垒——绝对的 DOM 控制权。任何试图在框架“管辖范围”之外直接操作 DOM 的行为,都注定会失败。 4.4 放弃对抗,另辟蹊径 最后我放弃了在原页面显示弹窗的方案,选择和 RAGFlow 的原生文件预览方式一样,在新标签页中渲染。也就是在脚本拦截点击后,在后台完成所有正确的数据请求。然后,它将获取到的元数据和 Markdown 内容,动态地构建成一个完整的、独立的 HTML 页面。最后,通过打开一个新标签页来展示这个页面。 最后展示的效果中,进一步提取了文档的元数据(如 ID、创建时间等),并采用 iOS 扁平化设计风格,将所有信息以清晰的卡片式布局呈现出来。 5 写在最后 5.1 关于油猴脚本 单页应用路由、Token 身份认证、前端框架的 DOM 控制权,几乎是每一个试图对现代 Web 应用进行个性化增强的开发者都会遇到的“三座大山”。而在 RAG 流程乃至更广泛的 Web 应用生态中,油猴脚本所代表的客户端注入模式,积极意义远超“小打小闹”的范畴: 敏捷与个性化 官方产品迭代有其固定的节奏和优先级。而作为一线用户的痛点往往是即时且个性化的。油猴脚本可以快速实现特定工作流中的功能补完,将产品打磨成最适合自己或团队的形态。 低风险与高兼容性 这种增强方式是非侵入式的,不用修改任何服务端代码,也不触碰核心前端应用的文件。这意味着它几乎不会对原系统的稳定性造成任何风险。只要 Ragflow 的核心 API 保持稳定,即使前端界面升级,脚本大概率也能继续工作,维护成本极低。 5.2 从 UI 增强到工作流自动化 这个 Markdown 预览脚本只是抛砖引玉,各位可以解决自己在使用 Ragflow 或其他工具时遇到的个性化问题。值得探索的方向还有: 知识库管理增强 编写脚本,在知识库文档列表页面,为每个文档增加“计算预估 Token 数”、“快速查看分块摘要”等按钮,在上传和管理阶段提供更多决策支持。 聊天交互的自动化 在聊天输入框旁,增加一个“常用 Prompt 模板”面板,一键发送复杂的指令。或者增加一个“导出对话”按钮,将当前问答流程以特定格式保存到本地。 跨系统工作流集成 更高阶的玩法,是让脚本成为连接器。例如,在预览页面增加一个按钮,可以将某个重要的 Chunk 内容,连同其元数据,一键发送到 Notion、Obsidian 等笔记软件中。 注:我针对不同网站的使用,之前开发了挺多零散的油猴脚本,都是些非常实用和好用的小工具,我考虑下个月空点打包成插件发出来,感兴趣的欢迎蹲一蹲,或者如果有什么小众需求可以 po 在评论区。 脚本已发布在知识星球中 | 









