ingFang SC", system-ui, -apple-system, "system-ui", "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 17px;font-style: normal;font-variant-ligatures: normal;font-variant-caps: normal;font-weight: 400;letter-spacing: 0.544px;orphans: 2;text-align: justify;text-indent: 0px;text-transform: none;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;white-space: normal;text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;background-color: rgb(255, 255, 255);line-height: 1.75em;visibility: visible;">沿着 AI 的发展脉络,本系列文章从Seq2Seq到RNN,再到Transformer,直至今日强大的GPT模型,我们将带你一步步深入了解这些关键技术背后的原理与实现细节。无论你是初学者还是有经验的开发者,相信读完这个系列文章后,不仅能掌握Transformer的核心概念,还能对其在整个NLP领域中的位置有一个全面而深刻的认识。那就让我们一起开始这段学习之旅吧!
PyTorch、TensorFlow 等深度学习编程框架极大简化了深度神经网络的训练过程,“训练手写数字识别模型”可能是很多同学编写的第一段深度学习代码。 importtorchimporttorch.nnasnnimporttorch.optimasoptimfromtorchvisionimportdatasets, transforms
# 准备数据train_loader = torch.utils.data.DataLoader( datasets.MNIST('./data', train=True, download=True, transform=transforms.ToTensor()), batch_size=64, shuffle=True)
# 定义模型classSimpleNet(nn.Module): def__init__(self): super(SimpleNet, self).__init__() self.fc1 = nn.Linear(28*28,128) self.relu = nn.ReLU() self.fc2 = nn.Linear(128,10) defforward(self, x): x = x.view(-1,28*28) x = self.fc1(x) x = self.relu(x) x = self.fc2(x) returnx
model = SimpleNet()
# 损失函数和优化器criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环forepochinrange(5): fordata, targetintrain_loader: outputs = model(data) # 前向传播 loss = criterion(outputs, target) # 计算损失 optimizer.zero_grad() # 梯度清零 loss.backward() # 反向传播 optimizer.step() # 更新参数
乍一看,这些代码简洁明了,但可能每一步都让初学者疑惑: 其实,这段极简代码背后,隐藏着深度神经网络训练的全部流程和基本概念,如果不理解这些核心流程和关键概念,就很难深入调参、排查问题,也无从掌控模型训练质量。本文将结合上面这个最常见的 DNN 训练 demo,逐步拆解每一环,从原理到常见名词,帮你彻底吃透神经网络训练的全过程。从粗粒度上上来讲,深度神经网络训练过程有 5 步: 1.前向传播 2.计算损失 3.反向传播 4.更新参数 5.循环训练 前向传播是 DNN 训练的第一步,输入数据通过网络的各层(输入层、隐藏层、输出层)进行处理,生成预测输出。 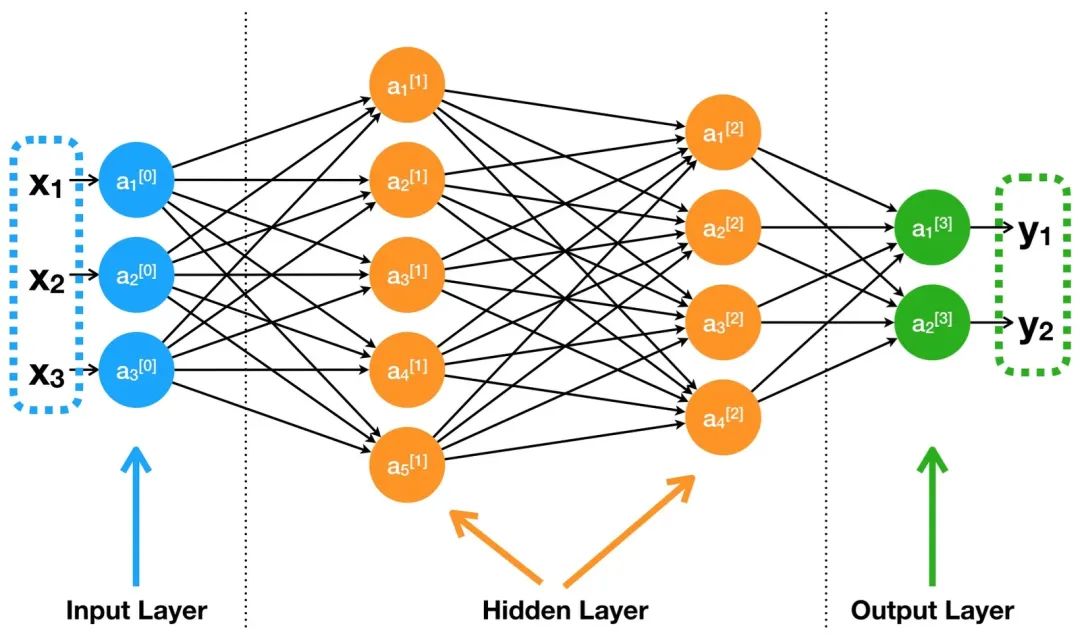
从技术角度看,前向传播是一个顺序计算过程,数据从输入层开始,经过隐藏层,最终到达输出层。在这个过程中,数据通过加权连接和激活函数进行转换,使网络能够捕捉复杂的模式。整个过程有几步 1.初始化:网络接收输入数据,通常是一个特征向量或矩阵。这些输入数据将通过网络的第一层传递。 2.线性变换:在每一层中,输入数据与该层的权重矩阵相乘,然后加上偏置向量。这个操作被称为线性变换或仿射变换。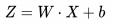
3.非线性激活:线性变换的结果通过一个非线性激活函数,如 ReLU、Sigmoid 或 Tanh。这一步为网络引入非线性,使其能够学习复杂的模式。 4.重复:步骤 2 和 3 在网络的每一层重复,每一层的输出作为下一层的输入。 5.输出:最后一层的激活函数通常根据任务类型选择,如分类任务使用 Softmax,回归任务可能使用线性激活。 线性与非线性 线性(Linear)的概念源自数学中的线性函数。在机器学习和深度学习中,线性的基本含义可以总结如下: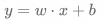 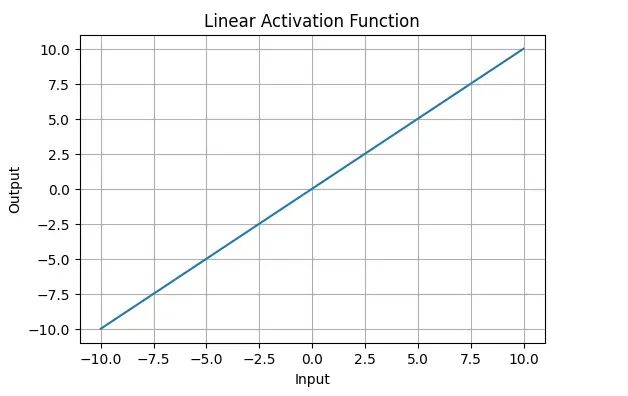
x 是输入变量,w 是权重,b 是偏置,y 是输出,输入 x 和输出 y 之间的关系是简单的比例关系,图像是一条直线。线性函数只能表示简单的单一斜率关系,无法捕捉更复杂的模式。 非线性(Non-linear)是指输入与输出之间的关系无法用简单的线性表达式描述。非线性系统可以描述更加复杂、多样化的输入输出关系,是神经网络捕捉复杂模式的核心要素。
神经网络的每一层通常都包含两步:“线性变换”再加上“非线性激活函数”。比如我们的模型定义中: self.fc1=nn.Linear(28*28,128)self.relu=nn.ReLU() 前向传播时: x=self.fc1(x)x=self.relu(x) 激活函数的作用是什么?如果只有线性层,无论多少层,整个网络其实本质上还是一个线性变换,表达能力有限。而激活函数(如 ReLU、Sigmoid、Tanh 等)引入了非线性特性,使得复杂的函数建模成为可能。 代码中使用了 ReLU 作为激活函数: classSimpleNet(nn.Module):def__init__(self):super(SimpleNet,self).__init__()self.fc1=nn.Linear(28*28,128)self.relu=nn.ReLU()self.fc2=nn.Linear(128,10)defforward(self,x):x=x.view(-1,28*28)x=self.fc1(x)x=self.relu(x)x=self.fc2(x)returnx self.relu(x)让激活函数 ReLU 被应用到了
在训练深度神经网络时一个常见的问题是过拟合。当模型的复杂度远高于训练数据的数量时,模型会开始“记忆”训练数据中的噪声和随机波动,而不是学习其潜在的通用规律。这导致模型在训练集上表现极好,但在未见过的测试集上表现很差,即模型的泛化能力很弱。 过拟合的一个深层原因是神经元之间的协同适应(Co-adaptation)。一个复杂的神经网络中,某些神经元可能会“抱团”,共同学习来修正其他神经元的错误。这种紧密的依赖关系使得模型变得脆弱,一旦输入数据有轻微变化,这种脆弱的依赖链条就可能被打破,导致预测错误。它们没有各自学到独立的特征。
Dropout 的提出正是为了解决这个问题,Dropout 的核心思想非常简单:在训练过程的每次迭代中,随机地“丢弃”(即暂时使其输出为0)一部分神经元。 由于任何一个神经元都可能在下一次迭代中被随机丢弃,所以网络不能过度依赖于任何一个或一小撮神经元的特定组合。这迫使每个神经元都必须学会一些独立的、更有用的特征,因为它需要与随机选择的其他神经元子集协同工作。这打破了神经元之间复杂的协同适应关系,使得模型泛化能力增强。 PyTorch 提供了简单易用的 Dropout 实现,可以在模型定义时直接添加: importtorchimporttorch.nnasnnimporttorch.optimasoptim
# 定义模型classDropoutNet(nn.Module): def__init__(self): super(DropoutNet, self).__init__() self.fc1 = nn.Linear(28*28,512) self.dropout = nn.Dropout(0.5) # 设置 Dropout 概率为 50% self.fc2 = nn.Linear(512,10) defforward(self, x): x = x.view(-1,28*28) x = self.fc1(x) x = torch.relu(x) # 激活函数 x = self.dropout(x) # 应用 Dropout x = self.fc2(x) returnx
# 初始化模型model = DropoutNet()
数据也有归一化的概念,不过应用在模型训练前的数据准备阶段,在训练深度神经网络时,每一层的参数在每次迭代后都会更新。这就导致了下一层网络的输入数据的分布会发生变化。随着网络层数的加深,这种微小的变化会不断累积,导致高层网络的输入分布发生剧烈变动。 归一化就是在网络的每一层输入端,强行将数据的分布重新拉回到一个稳定、标准的范围内(例如,均值为 0,方差为 1)。常见有两种归一化方法: 1.BatchNorm(批归一化)旨在确保同一特征在不同样本间保持相似的分布。它在训练过程中对本批样本数据的每个特征维度横向进行归一化。 2.LayerNorm(层归一化)则着眼于单个样本内部的特征。它对单个样本的所有特征纵向进行归一化,使其完全独立于批次中的其他样本。 选择哪种归一化方法,本质上是在回答一个问题:“我们认为数据的哪个维度上更应该共享同一个统计规律?” 因此在现代深度学习实践中: “残差”是一个数学术语,来源于统计学和机器学习领域,表示实际值与预测值之间的差异。在神经网络中的“残差连接”,正是基于这种意义,将“残差”巧妙融入网络结构的设计中。 在深度神经网络中,更多的层数能够捕获更加复杂的特征,理论上增加层数会使模型的拟合能力更强。但在实际训练时发现,随着网络层数的加深,模型的性能可能会开始下降,新增的网络层往往难以学习到有效的内容,甚至只是重复已有的特征。这种现象被称为退化问题(Degradation Problem)。 想象我们有一个目标任务——让团队成员接力撰写一篇高质量的论文。传统做法是由第一个人起草初稿,然后传递给下一个人,每个人阅读理解后,用自己的表述重写再传递下去。然而,随着传递次数增多,最终的文章可能已经偏离了最初的主题。表现出色的前几段内容会被后续重写的修改削弱,甚至可能导致整体质量下降。 一种改进方式是:每个人只需在上一位同事的基础上补充自己的修改意见,而无需完全重写。如果发现前面的内容已经非常优秀,可以选择不作任何改动。在这种策略下,文章的整体质量能够随着参与人数的增加而逐步提高,而不会因为频繁重写而被破坏。 这也正是残差连接的核心思想:与其让网络层直接学习一个复杂的、从输入到输出的完整映射,不如让它学习输入和输出之间的“残差”或“差异”(对论文的修改意见)。 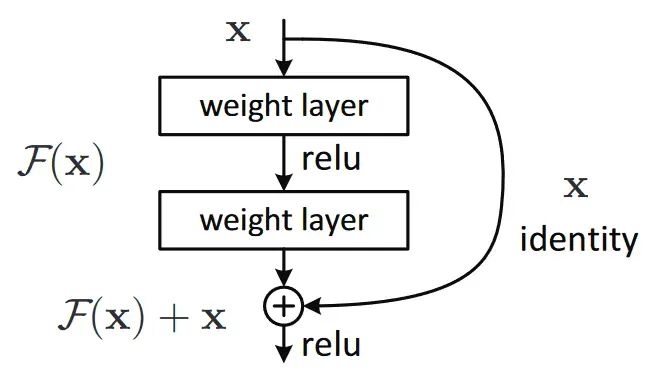
这意味着原始输入的信息可以“跳过”当前层,直接传递到输出端。当前层只需学习如何对这个原始信息进行精炼和优化(即学习残差),而不是从零开始生成。通过为神经网络中的每一层增加一个捷径路径(Shortcut Path),直接将输入数据跳跃传递到后续层的输出,这些层只需负责学习补偿性的小变动,从而使得优化任务更加简单。 了解了归一层和残差连接的概念,再看 Transformer 好像又简单了一些呢。 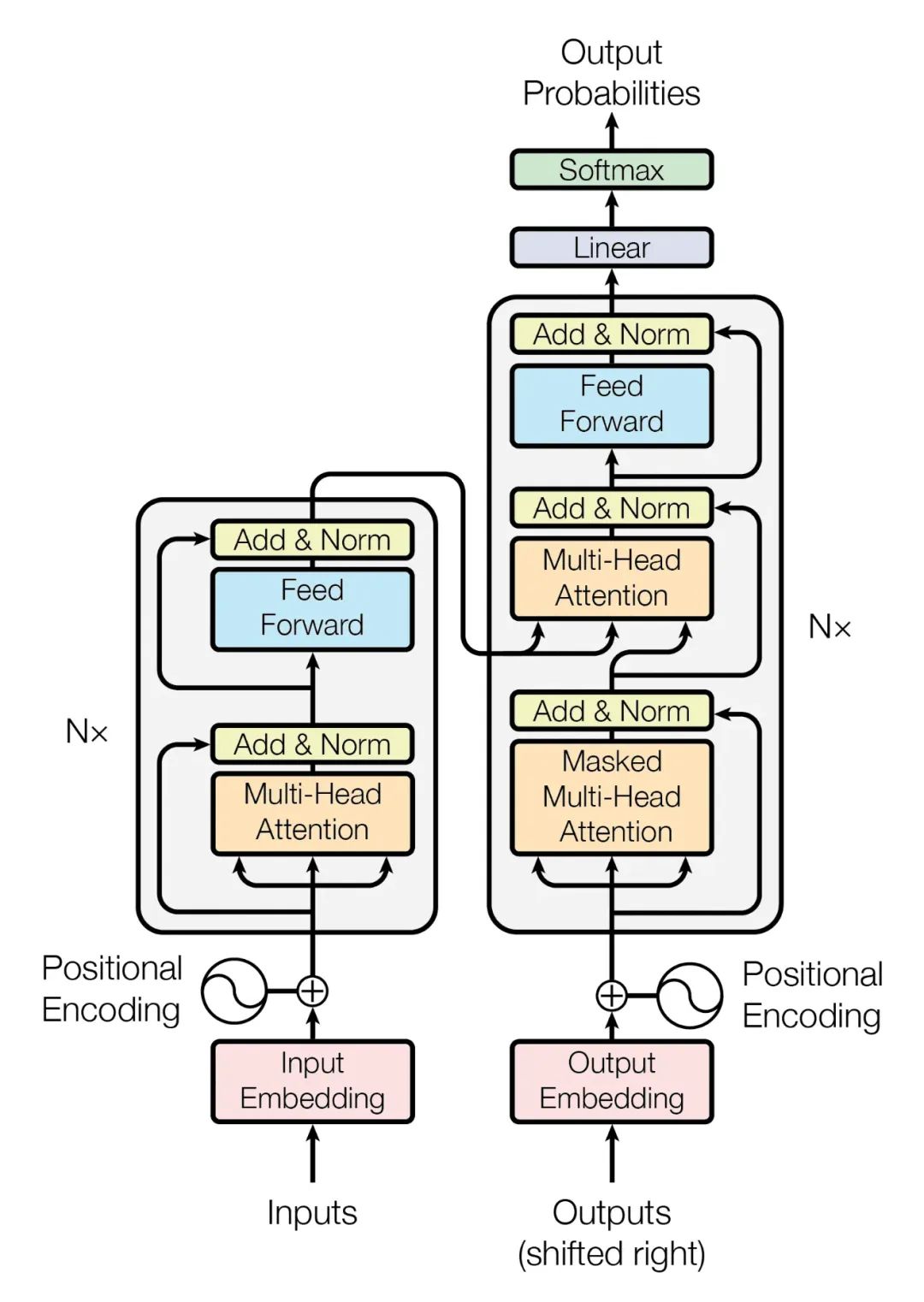
这段 demo 代码也没有那么面目可憎了。 importtorchimporttorch.nnasnn
classTransformerBlock(nn.Module): def__init__(self, embedding_dim, ff_dim): super().__init__() self.norm1 = nn.LayerNorm(embedding_dim) # 用于 self-attention 模块 self.norm2 = nn.LayerNorm(embedding_dim) # 用于 FFN 模块 self.attention = nn.MultiheadAttention(embedding_dim, num_heads=8) self.feed_forward = nn.Sequential( nn.Linear(embedding_dim, ff_dim), nn.ReLU(), nn.Linear(ff_dim, embedding_dim) ) defforward(self, x): # 自注意力模块 attention_out, _ = self.attention(x, x, x) x = x + attention_out # 残差 x = self.norm1(x) # LayerNorm # 前向传播模块 ff_out = self.feed_forward(x) x = x + ff_out # 残差 x = self.norm2(x) # LayerNorm returnx
当数据完成前向传播,我们会得到一个预测结果 outputs。下一步就是衡量这个预测结果与真实标签 labels 之间的差距。这个差距我们用一个数值来表示,称之为损失(Loss)。 机器学习的目标,就是通过不断地调整模型的参数,来最小化这个损失函数的值,从而让模型的预测尽可能地接近真实值。 损失函数定义了“差距”的计算方式。不同的任务需要不同的损失函数:熵衡量的是一个概率分布的不确定性或信息量。一个分布越混乱、越不可预测,它的熵就越大。
对差值取平方有两个好处: 1.消除正负号的影响,让误差 “绝对值化”,防止求和之后误差互相抵消; 2.放大误差便于模型优化,例如误差为 3 和 0.4,平方后变为 9 和 0.16,差异更明显。
因为数字识别是分类任务,所以文章最开始的代码使用了交叉滴损失作为损失函数 criterion=nn.CrossEntropyLoss() 正则化是在损失函数中加入一个惩罚项,限制或惩罚模型的复杂度,从而迫使模型去学习更简单、更具泛化能力的模式,以此来避免过拟合。我们知道,模型训练的目标是最小化损失函数。原来的损失函数只关心预测误差: 原始损失 = Error(预测值,真实值) 加入了正则化之后,新的损失函数(或称为目标函数)变成了: 新目标函数 = 原始损失 + λ⋅模型复杂度惩罚项 模型复杂度惩罚项是一个用来衡量模型有多复杂的函数。通常模型的参数(权重)越大,我们就认为模型越复杂。最经典的正则化技术主要有 L1 正则化和 L2 正则化,它们是对模型参数(权重)进行惩罚。 另外前面已经提到的 Dropout 也是一种正则化技术,其在神经网络中极其有效。 我们已经知道了模型预测得“有多差”(损失值 Loss),现在最关键的问题来了:如何调整模型的参数(权重 W 和偏置 b)来减小这个 Loss 呢?答案就是反向传播。 反向传播的数学基石是微积分中的链式法则,它允许我们计算一个复杂函数(整个网络的损失函数)中,每个参数对最终输出(Loss)的偏导数,这个偏导数就是梯度(Gradient)。 1. 导数是微积分的一个核心概念,用来描述一个函数在某一点的变化率。简单来说,导数表示函数的输入发生微小变化时,输出的变化速度。 2. 几何上,导数表示曲线 y=f(x) 在某一点 x 处切线的斜率。如果导数值为正,则函数在该位置是上升的;如果为负则函数下降;如果导数为零,这点可能是极小值、极大值或拐点。 3. 偏导数是指多元函数(即输入有多个变量的函数)固定其他变量不变时,函数关于某个自变量的导数。
模型整个训练过程包含两个阶段:前向传播和反向传播。 阶段一:前向传播 (Forward Propagation) 1.输入数据:将一个或一批训练数据输入到网络的第一层。 2.逐层计算:数据从输入层开始,逐层向前流动。每一层的神经元接收上一层的输出,进行加权求和与激活函数计算,然后将结果传递给下一层。 3.生成输出:直到最后一层输出模型的预测结果ŷ。 4.计算损失:用损失函数比较模型的预测y,计算出总的损失值L。 整个过程就像水流顺着管道从头流到尾,最终得到一个误差值。 阶段二:反向传播 (Backward Propagation) 梯度(误差信号)将从网络的末端开始,反向传播回网络的每一层 1.从损失函数开始:计算损失L对网络最后一层输出ŷ的梯度。这是梯度计算的起点。 2.逐层向后计算:利用链式法则,将梯度从当前层反向传播到前一层。具体来说,就是计算损失L对当前层所有参数(w,b)以及对当前层输入(即上一层的输出)的梯度。 3.梯度传递:上一层接收到从后一层传来的梯度信号后,继续用同样的方法计算本层的梯度,并继续向前传递。 4.到达输入层:这个过程一直持续到网络的第一层。当这个过程完成时,我们就得到了损失L对网络中所有参数的梯度。 整个过程就像把在终点产生的误差,按照原路“归因”或“分摊”给每一层的每一个参数,搞清楚每个参数对最终的总误差贡献了多少“责任”。 反向传播过程看起来就很数学、很复杂,幸运的是 PyTorch、TensorFlow 等深度学习框架内置了自动求导 (Autograd) 引擎,它会自动构建计算图,并利用链式法则为我们计算所有参数的梯度。我们只需要简单地调用一个函数。 当我们在一个张量上调用 #训练循环forepochinrange(5):fordata,targetintrain_loader utputs=model(data)#前向传播loss=criterion(outputs,target)#计算损失optimizer.zero_grad()#梯度清零loss.backward()#反向传播optimizer.step()#更新参数 utputs=model(data)#前向传播loss=criterion(outputs,target)#计算损失optimizer.zero_grad()#梯度清零loss.backward()#反向传播optimizer.step()#更新参数 计算出梯度后,我们就有了调整参数的方向。下一步就是实际去“更新”它们。 梯度下降 (Gradient Descent) 是一种在机器学习和深度学习中广泛使用的优化算法。它的主要目标是找到使某个损失函数达到最小值的模型参数,因为希望最小化损失函数,所以我们需要沿着函数值下降最快的方向移动。 梯度下降是一个迭代过程,它会重复以下步骤,直到达到某个停止条件(比如损失函数的值足够小,或者迭代次数达到上限): 1.初始化参数:首先,我们会给模型的权重和偏置等参数设置一个初始值(通常是随机值)。 2.计算损失:使用当前的参数值,计算模型在训练数据上的损失函数值,损失函数衡量了模型的预测结果与实际结果之间的差异。 3.计算梯度:计算损失函数对每个参数的偏导数,得到梯度。这个梯度告诉我们,如果沿着哪个方向稍微调整参数,损失函数会增加得最快。 4.更新参数:沿着梯度的反方向更新参数。更新的步长由一个叫做学习率 (Learning Rate)的超参数决定。学习率越大,每次更新的步长就越大;学习率越小,步长就越小。 数学表达式通常是: 新参数 = 当前参数 - 学习率×梯度 5.重复:回到步骤 2,用新的参数值重新计算损失,然后继续更新,直到损失函数收敛到一个最小值。 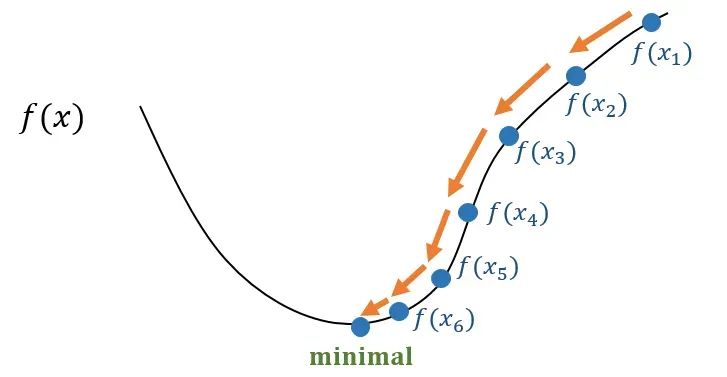
就像一个盲人下山。他看不见整个山的全貌,只能通过脚下地面的坡度来判断方向。 他会先在山上的某个位置站定。 然后,他会用脚感受周围哪个方向的坡度最陡峭(这是梯度)。 为了下山,他会选择与坡度最陡峭方向相反的方向迈出一步(这是负梯度方向)。 每一步迈多远(学习率)也很关键。步子太小,下山太慢;步子太大,可能会直接跳过最低点,甚至跌到山谷外面。 他会重复这个过程,一步一步地朝着山谷的最低点前进。
梯度下降是一种基本的优化算法,它定义了如何根据损失函数的梯度来更新模型参数。虽然原始的梯度下降在实际应用中,它存在一些局限性,比如: 收敛速度慢:尤其是在数据量大的情况下,每次计算所有样本的梯度会非常耗时。 容易陷入局部最小值:在非凸损失函数中,可能会停留在非全局最优的局部最小值。 对学习率敏感:学习率设置不当容易导致震荡或收敛过慢。
为了克服这些限制,研究人员开发了各种改进型优化器。这些优化器在基本梯度下降的基础上,引入了额外的机制来提高训练效率、稳定性和收敛性。 这就是代码中Adam、 # 损失函数和优化器criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环for epoch in range(5): for data, target in train_loader: outputs = model(data) # 前向传播 loss = criterion(outputs, target) # 计算损失 optimizer.zero_grad() # 梯度清零 loss.backward() # 反向传播 optimizer.step() # 更新参数
梯度消失和梯度爆炸是深度神经网络训练过程中,由于反向传播中链式法则的乘法效应导致的两个极端问题
至此,我们完成了一个完整的训练步骤(iteration)。但只走一步是远远不够的。我们需要将整个数据集过一遍,这个过程称为一个周期 (Epoch)。然后我们会重复很多个 Epoch,让模型在数据上反复学习。 在一个 Epoch 中,对于每一批(batch)数据: 1.前向传播:输入数据,得到预测值。 2.计算损失:用损失函数计算预测值和真实值之间的差距。 3.反向传播:调用loss.backward(),计算每个参数的梯度。 4.更新参数:调用 这个循环不断重复,模型的参数被持续优化,损失值(Loss)会不断下降,模型在训练数据和未见过的验证数据上的表现会越来越好,直到达到收敛或满足我们设定的停止条件 | 









