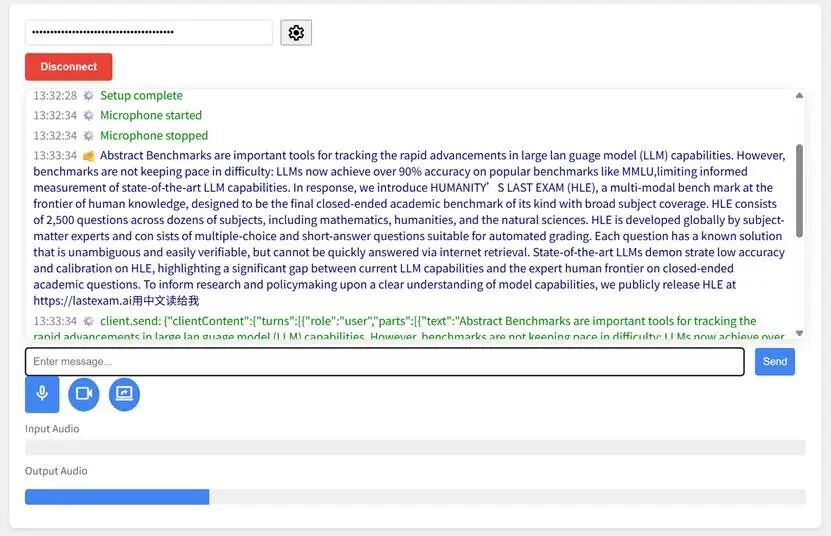
|
快速0成本部署你的专属Gemini多模态AI助手!
没错,就是Google最新发布的Gemini 2.0,不仅完全免费,还支持语音对话、视频通话、屏幕分享等功能。
2.开启摄像头让AI"看"到你在做什么、识别物体、判别物料等(场景自己脑补)。我已经帮你踩过所有的坑,整理了最详细的保姆级教程。
不管你是技术小白还是资深开发者,跟着我的步骤,保证让你拥有一个比ChatGPT Plus还要强大的AI助手,而且永久免费!
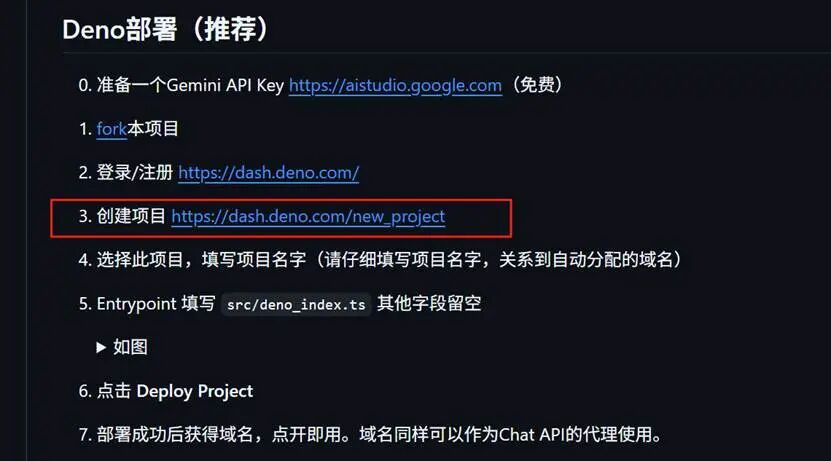
废话不多说,上干货! 部署指南 第一步:进入https://github.com/tech-shrimp/gemini-playground,也就是tech-shrimp提供的快捷部署方案。
第二步:按Deno部署流程,选择fork本项目,把项目复制到自己名字下面。
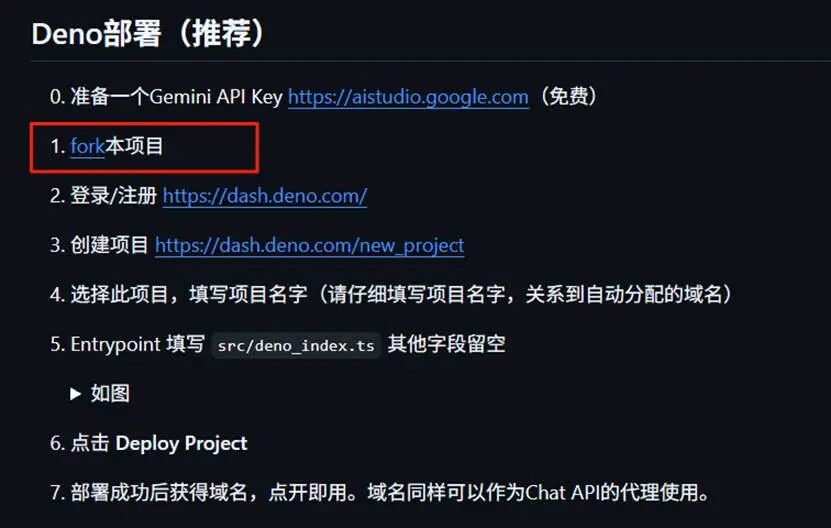
点击:Create fork
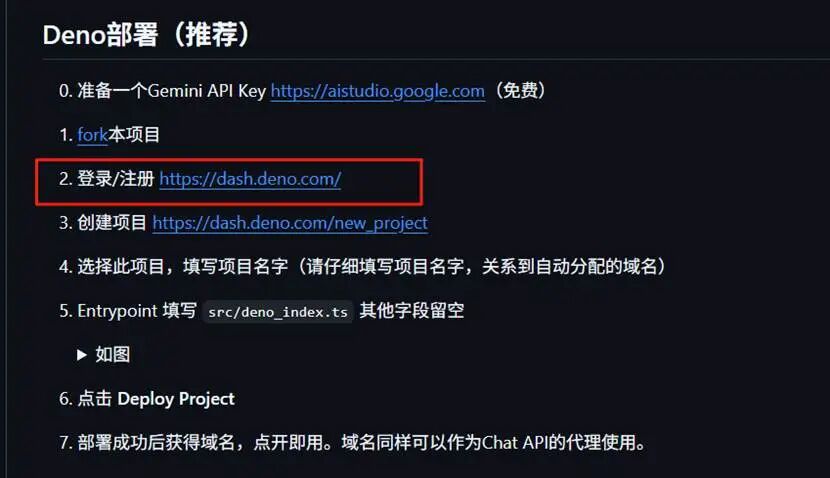
登录https://dash.deno.com/, 进来以后直接使用github登录。
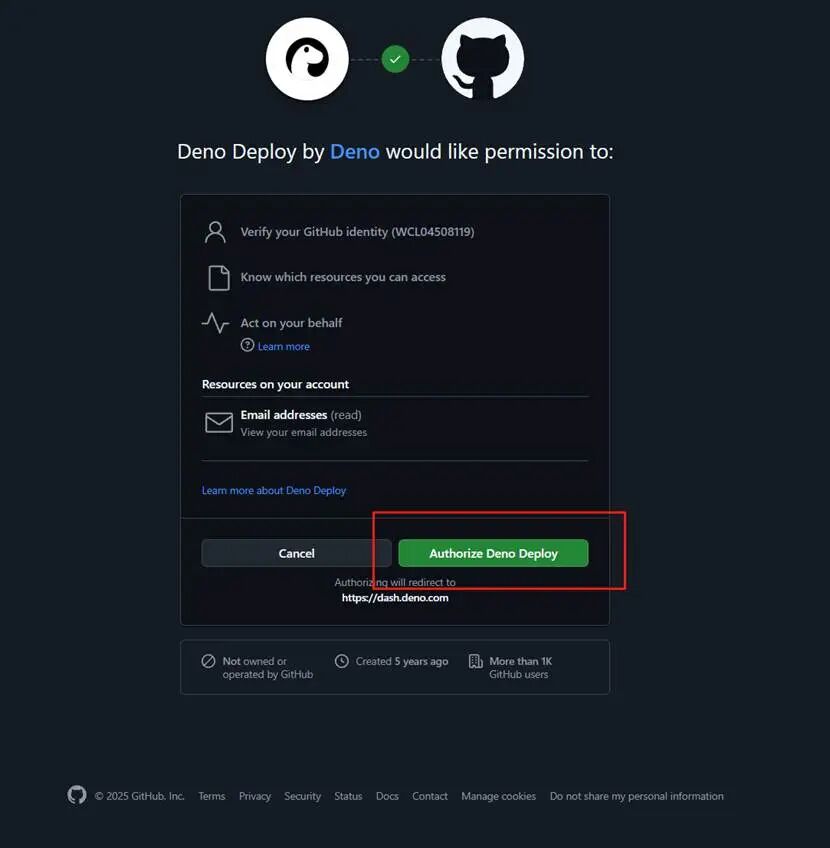
进行授权

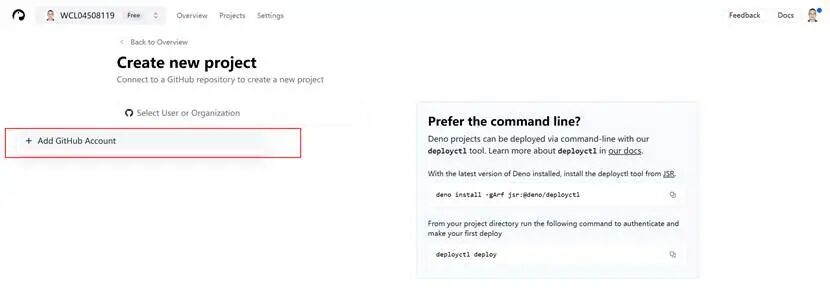
选择Add GitHub Account
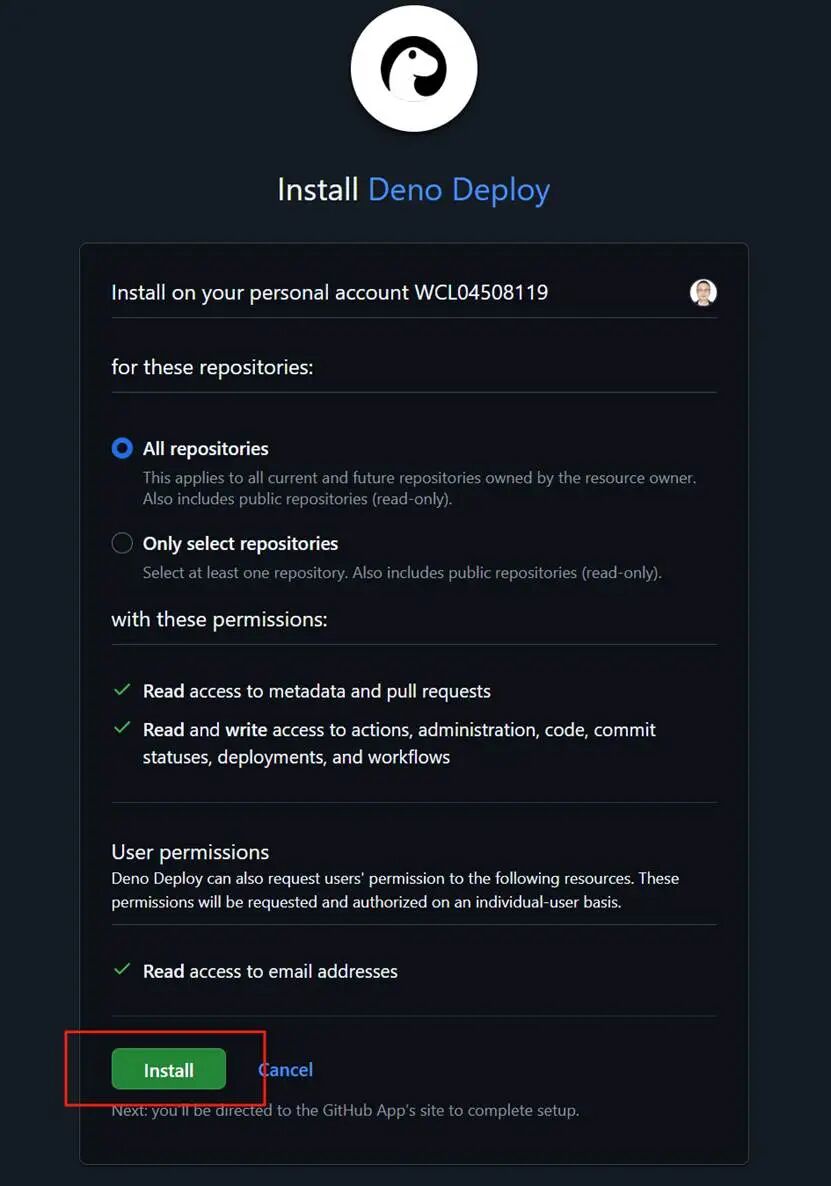
点击安装
然后选好github账号
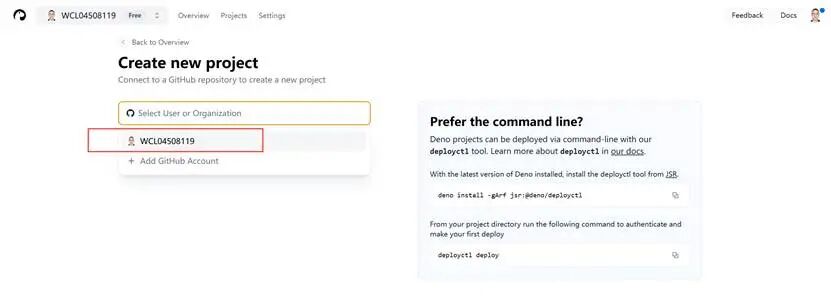
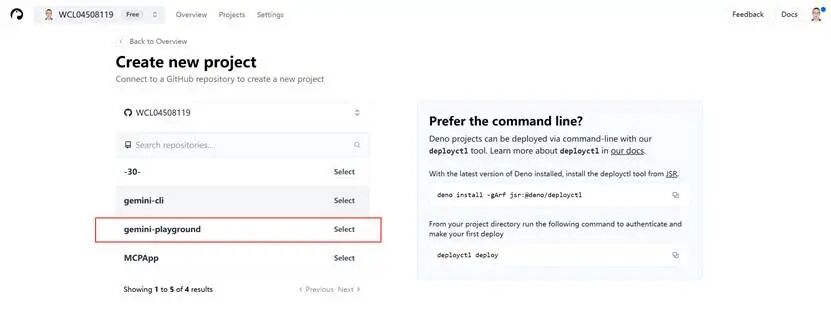
这里面要搞一个自己喜欢的名字,我是用我的名字的首写字母以及数字。
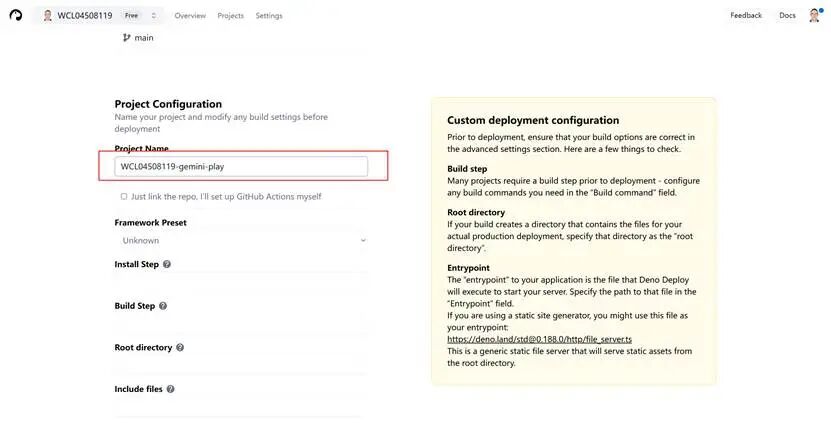
选择src目录里面的deno index.ts
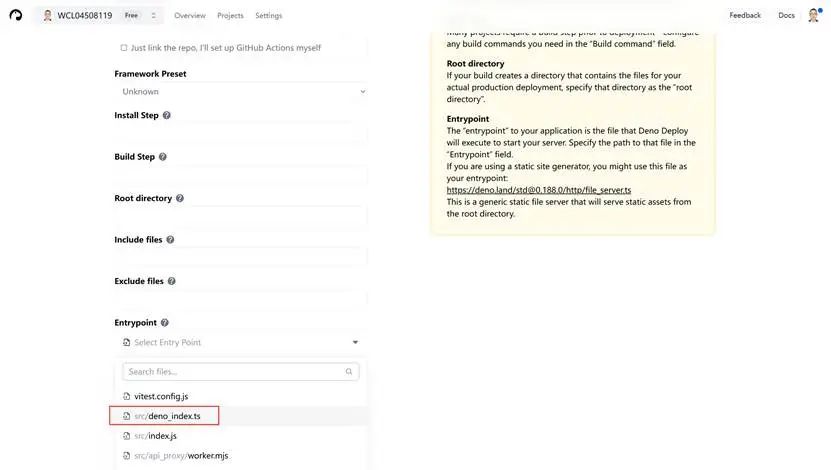
点击部署
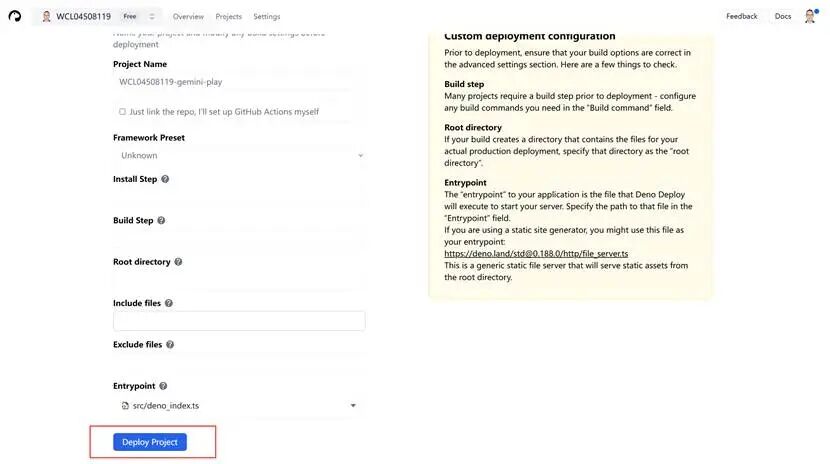
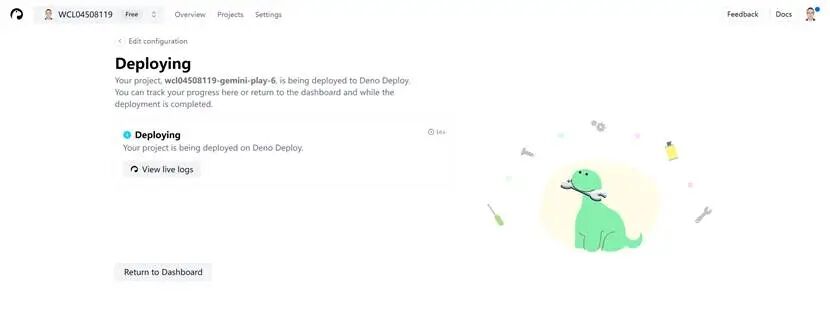
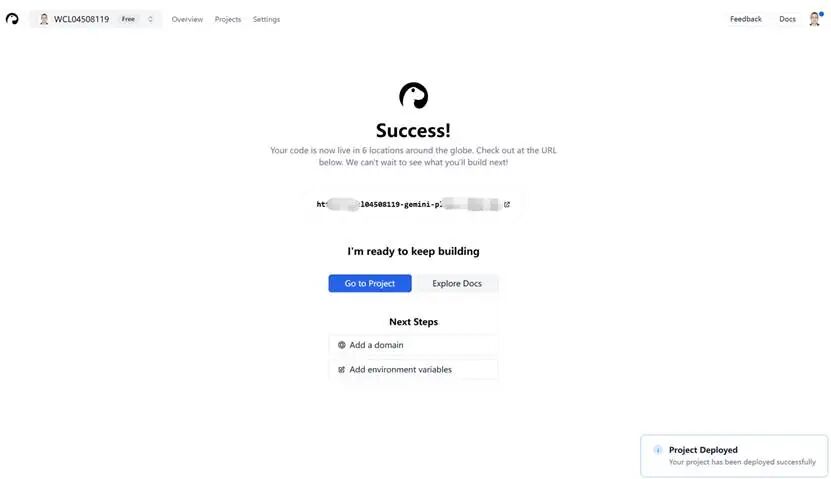
部署成功后会自动生成一个域名
接下来需要搞一个谷歌的
Cemini APl key:
https://aistudio.google.com/
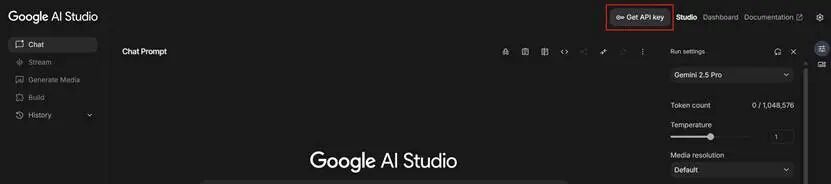
创建API密钥(密钥要保密),这个密钥是可以一直免费使用的
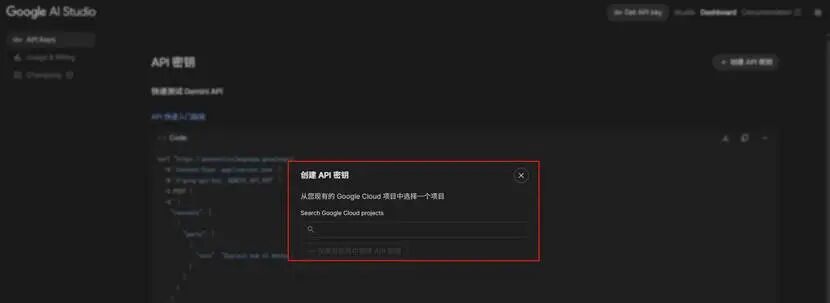
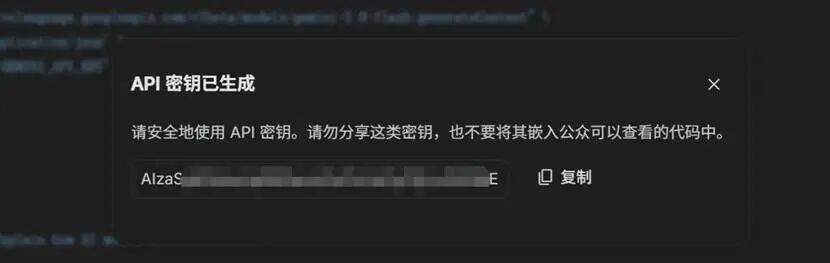
把创建好的密钥复制粘贴到网站里,直接点击connect
初始设置步骤:权限配置
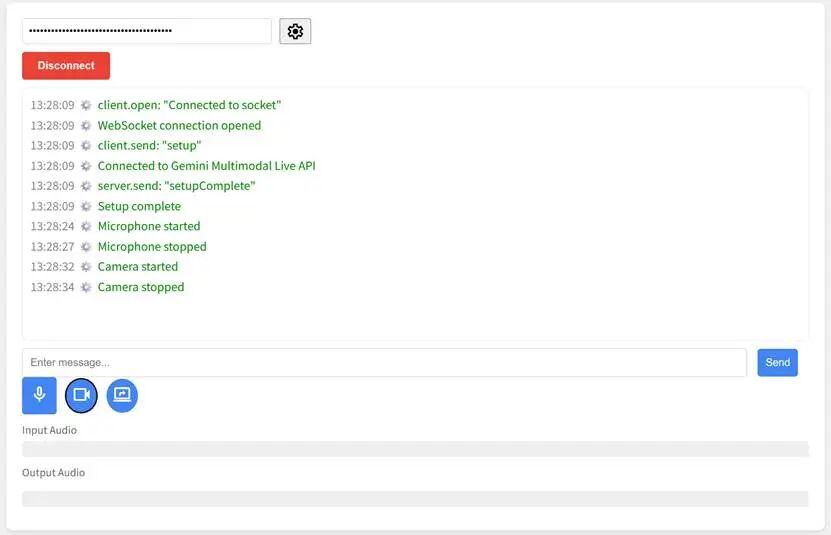
当首次使用时系统会请求以下权限:
1.麦克风权限 用于语音输入和实时对话 支持连续对话模式 可识别语音指令和自然对话
2.摄像头权限 用于视觉识别和分析 支持实时图像处理 可进行场景理解和物体识别
重要提示:请在浏览器弹窗中选择"允许",确保功能正常运行。 功能对照
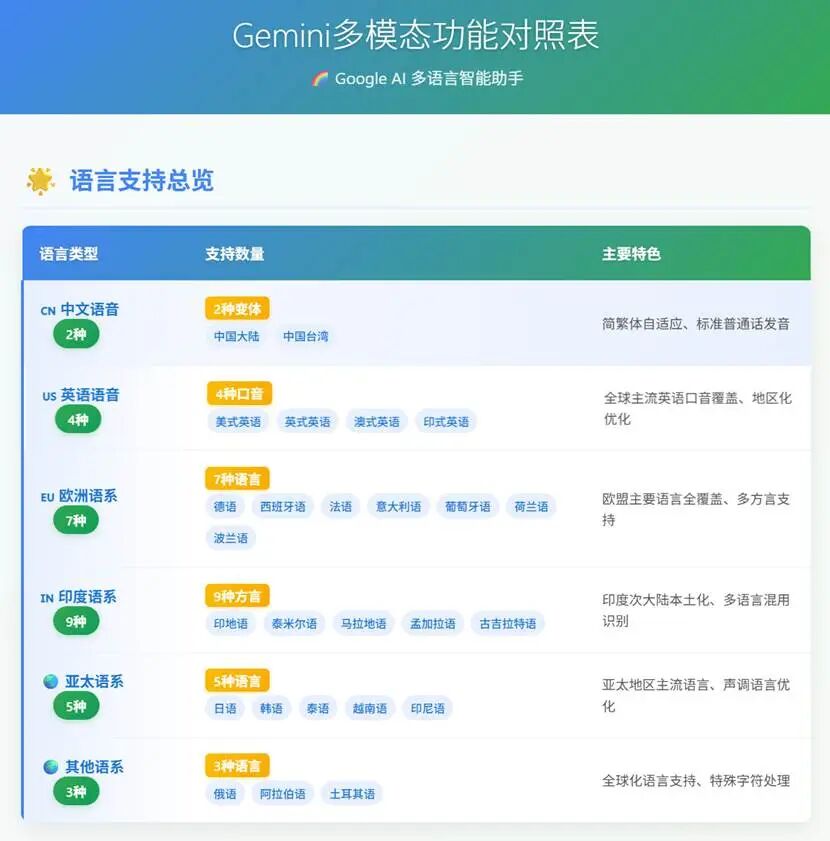
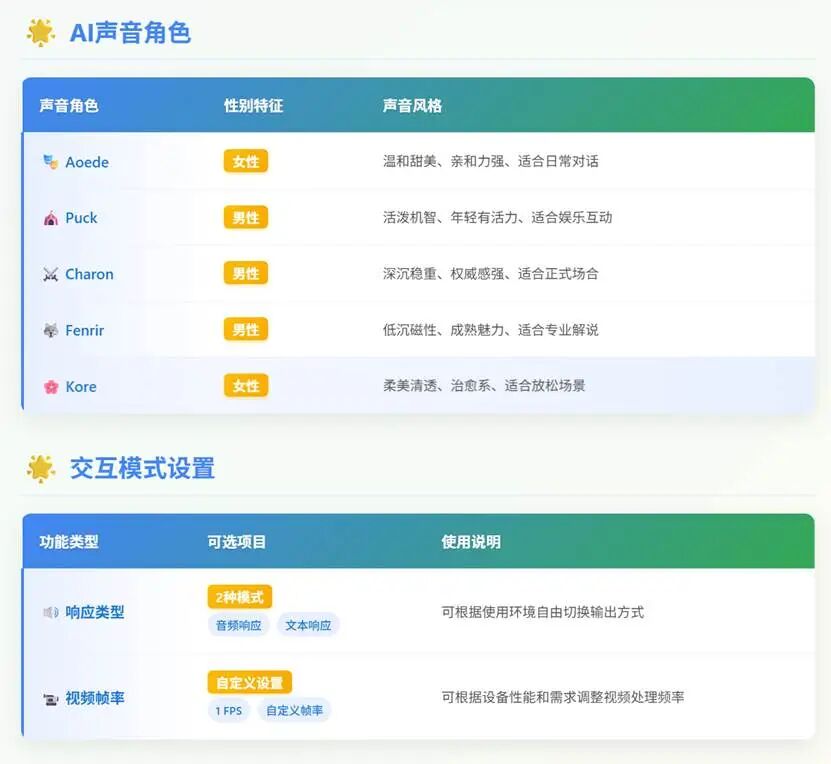

应用示例 接下来就开始工作了!开启摄像头它能看一切,解读一切
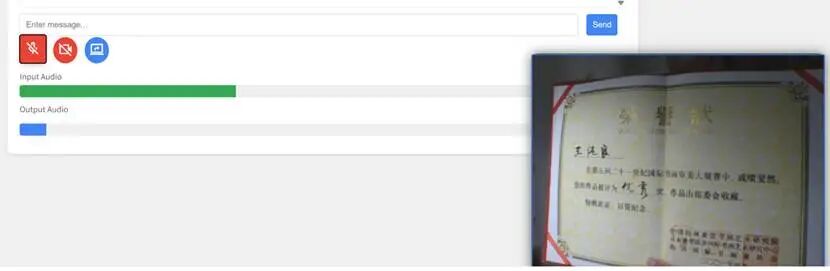
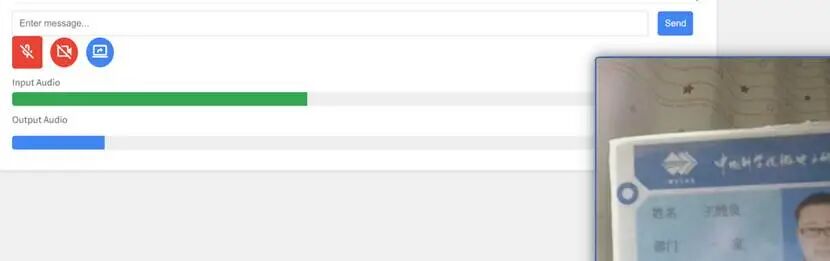
屏幕共享 窗口共享:只会共享某个应用窗口的画面。例如,你在本地电脑播放一段视频,AI可以实时识别并用中文为你翻译,非常适合专注于单一内容的使用场景。小编用它看个美国大片实时翻译成中文给我。。。 当你把窗口共享给它后,你在产品上的任何操作任务,它都有可能给予指导(具体效果取决于你如何训练它,也就是微调)。 整个屏幕共享:会将你的整个电脑桌面共享给AI,它不仅能解读你播放的视频,还会记录并理解你在屏幕上的各种操作,从而根据你的需求提供解释或辅助。 拓展应用想象 有了这样强大的多模态AI能力,你甚至可以考虑将它集成到更多硬件设备中。比如智能音箱、监控系统,或者如果你有动手能力(钣金、铸造、微电子),甚至可以尝试打造自己的AI机器人助手。 图片为小编与联想人形机器人合影 给它英文,用中文读给我听;
你也可以使用终端做实时翻译,对方说外星语,它会实时翻译给你。
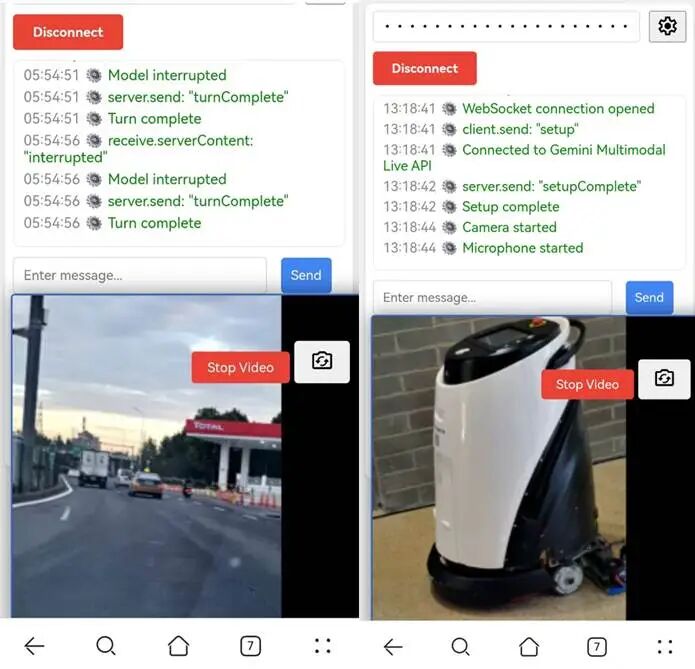
你也可以把它对接到你家摄像头上,也可以做到你的车载摄像头里,但是一定要经过测试 管理智能体:用AI来管理AI 本地GEMINI模型代理托管执行方案 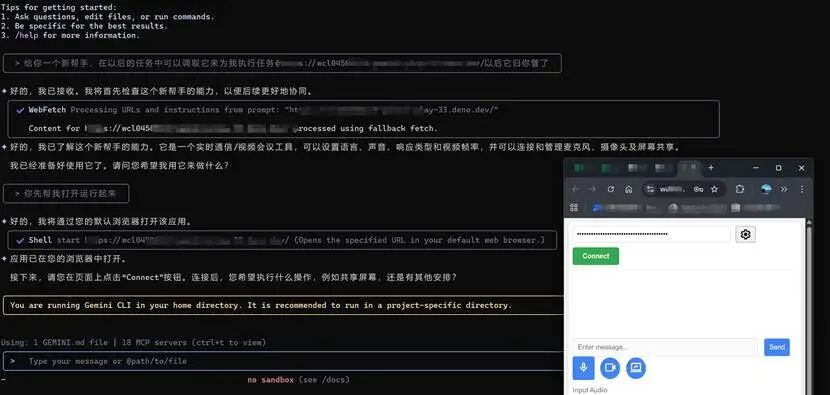
Gemini 是如何调取智能体为我执行任务的? 其实以上简单来说,智能体就像一个智能的项目经理:
1.首先它会理解俺的需求当我给它一个任务时,它首先要搞清楚我到底想要什么,然后把大任务拆分成一个个小步骤。
2.选择合适的工具它有很多"专业助手"(工具),比如读文件的、运行代码的、搜索信息的。针对每个小任务,会挑选最合适的工具来完成。(当然这些能里有的是它自带的,有的是我通过MCP给它植入的)
3.执行并检查结果让工具干活后,它会仔细检查结果是否正确。如果出错了,不会放弃,而是会:
实在不行就问我,是不是要换个思维或方案(也就是确认机制)
4.整合交付所有小任务都完成后,智能体把结果整理好给我,还会告诉我它做了什么。
这就像我请一个助理帮我办事,遇到问题还会主动想办法解决,实在解决不了才会来问你。
我抽取了一套代理执行wcl -33机制:让本地GEMINI模型作为中间管理层,负责调取和操作wcl -33这个智能体,以下是技术全貌 执行架构:
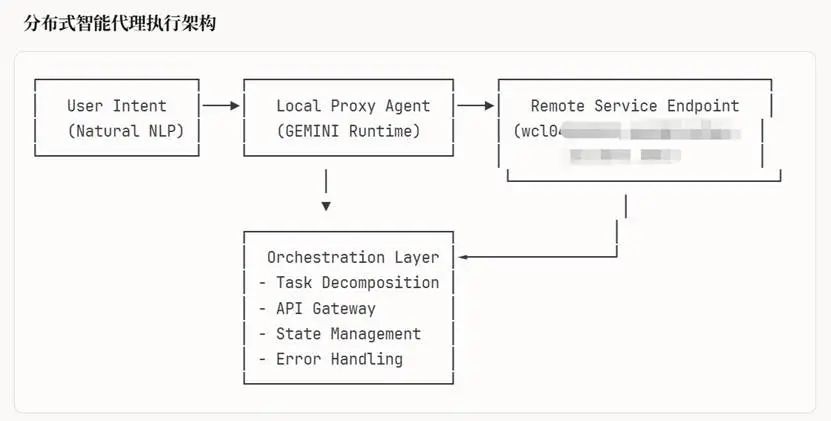
技术栈架构层次:
L4 - Presentation Layer (用户接口层)
- Natural Language Processing Interface
- Intent Recognition & Parsing
- Context-Aware Request Formatting
L3 - Business Logic Layer (业务逻辑层)
- Local GEMINI Model Runtime Environment
- Task Queue Management System
- Intelligent Routing & Load Balancing
L2 - Service Integration Layer (服务集成层)
- RESTful API Client Abstraction
- WebSocket Connection Pool Management
- Authentication & Security Token Handling
- Circuit Breaker Pattern Implementation
L1 - Infrastructure Layer (基础设施层)
- HTTP/HTTPS Transport Protocol
- JSON/Protocol Buffer Serialization
- Distributed Logging & Monitoring
- Fault Tolerance & Retry Mechanisms
核心组件详述:
- Intelligent Proxy Gateway:本地GEMINI模型作为智能网关,实现请求路由、负载均衡和故障转移
- Asynchronous Task Orchestrator:异步任务编排器,支持复杂工作流的分解与并行执行
- Adaptive Caching Layer:自适应缓存层,基于访问模式优化响应时延
- Service Mesh Integration:微服务网格集成,实现服务发现、流量管理和安全策略
工作流程:
任务委托:我将具体的执行需求告知本地GEMINI模型,而不是直接操作这个智能体。
- 连接到目标URL
- 解析服务接口和功能
- 根据我的需求调用相应的API或功能
- 处理返回的数据和结果
- 监控服务状态和可用性
- 优化调用策略和参数
- 处理异常和错误重试
- 格式化输出结果供我查阅
以下是我给大家归整了一些企业级应用场景(当然不止这些)
最后:两个思维转换 从优化到重塑
AI时代已经到来。关键问题不再是"AI能做什么",而是"你想用AI创造什么价值"。
大多数人在工作中使用AI时,习惯性地想着如何优化现有流程——让报告写得更快,让数据分析更准确,让沟通更高效。这种思路本身没有错,但也许、可能、大概格局有限。
真正的机会在于跳出优化思维,进入重塑思维:
1.不是让现有任务做得更好,而是质疑这个任务是否还有存在的必要,或是有没有其他的任务替代合并。
2.不是在既定的道路上跑得更快,而是开辟一条全新的跑道。
3.不是修补旧流程的漏洞,而是设计全新的价值创造方式。
比如,与其优化客服回复速度,不如重新思考:我们能否用AI创造一种让客户根本不需要求助的体验?或是客户觉得求助的过程就是上瘾的体验! 从需求到场景思维的转变
传统的产品人往往陷入"用户说什么我们做什么"的思维陷阱。但真正有效的方法是:尽量少谈用户需求,多谈用户场景。
用户需求思维的局限性:
用户场景思维的优势:
- 补充大量用户信息,构建完整画像(也就是说你的上下文很多)
记住:最大的浪费不是效率低下,而是高效地做着错误或是低价值的事情。
AI给了我们重新定义很多东西本质的机会,别把它仅仅当作提升工具。 | 









