一、整体架构
1.1 架构概述
dify 的 RAG(检索增强生成)架构是一个完整的文档处理、索引和检索系统,旨在提高大语言模型生成内容的准确性和相关性。该架构由三个主要模块组成:文档处理模块、向量化与索引模块、检索与重排模块。
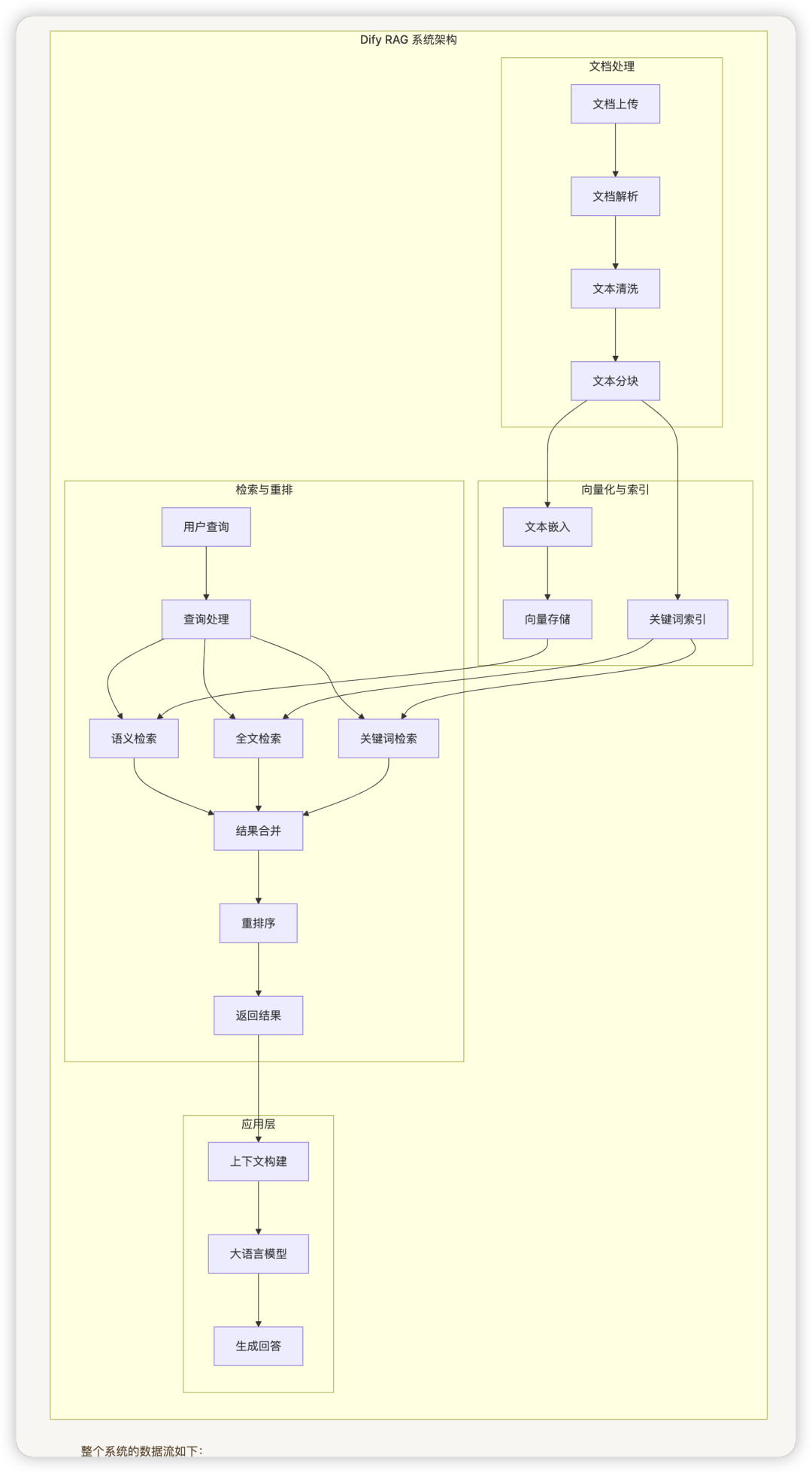
整个系统的数据流如下:
- 向量化模块将这些段落转换为向量表示并存储在向量数据库中
- 用户查询时,检索模块根据配置的检索方法找到相关段落
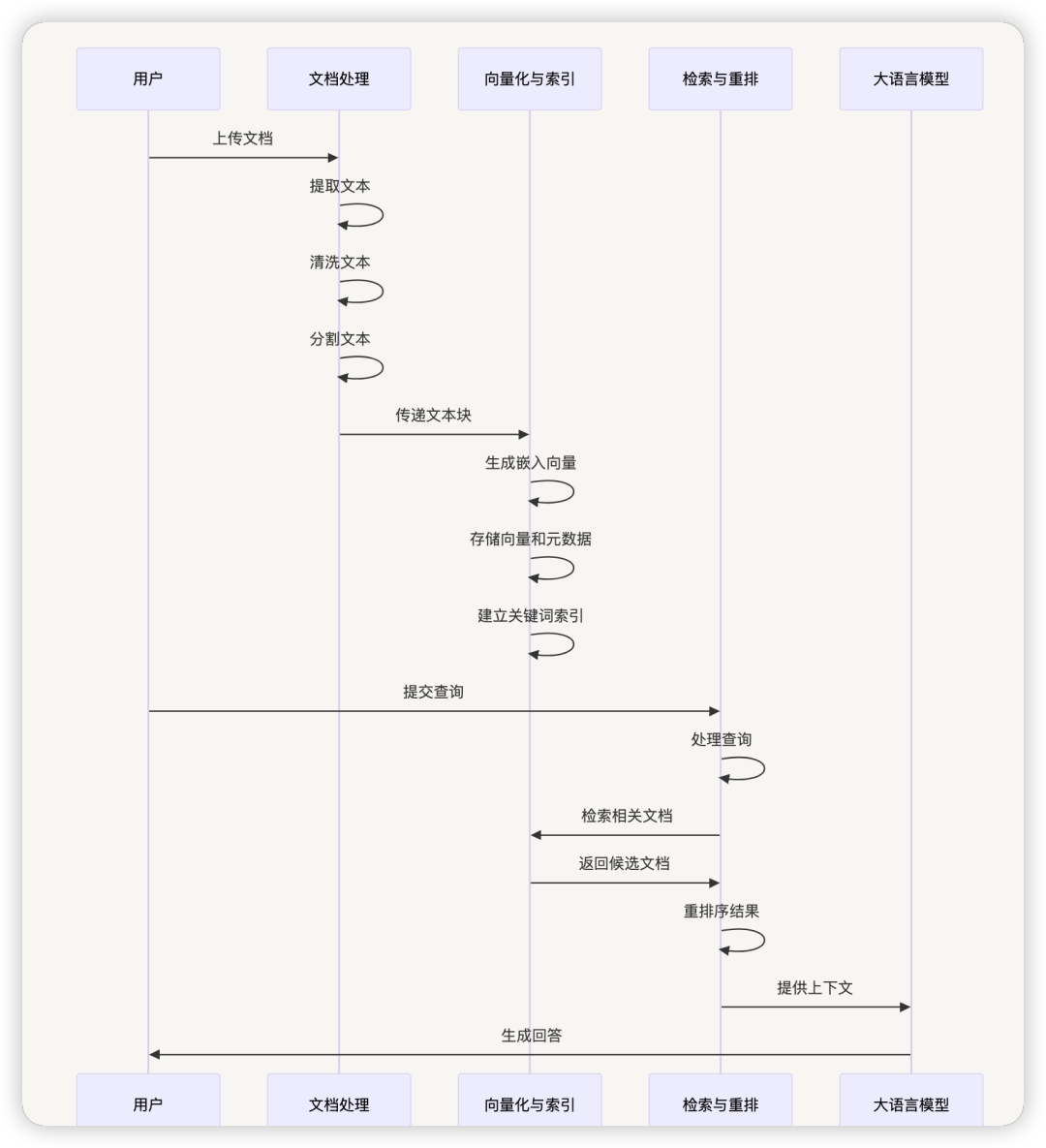
1.2 数据模型关系
Dify RAG 系统的核心数据模型包括:
- Dataset:知识库,包含多个文档,是 RAG 的基本单位
- DocumentSegment:文档分段,是实际被索引和检索的最小单位
- DatasetKeywordTable:关键词表,用于支持关键词搜索
这些实体之间的关系是:一个 Dataset 包含多个 Document,一个 Document 包含多个 DocumentSegment。Dataset 通过index_struct 字段存储向量数据库的配置信息。
二、文档处理模块
2.1 设计思路
文档处理模块负责将各种格式的文档转换为可被索引的文本段落。该模块采用 ETL(提取-转换-加载)模式设计,具有高度的可扩展性和灵活性。
主要功能包括:
2.1 文档处理架构
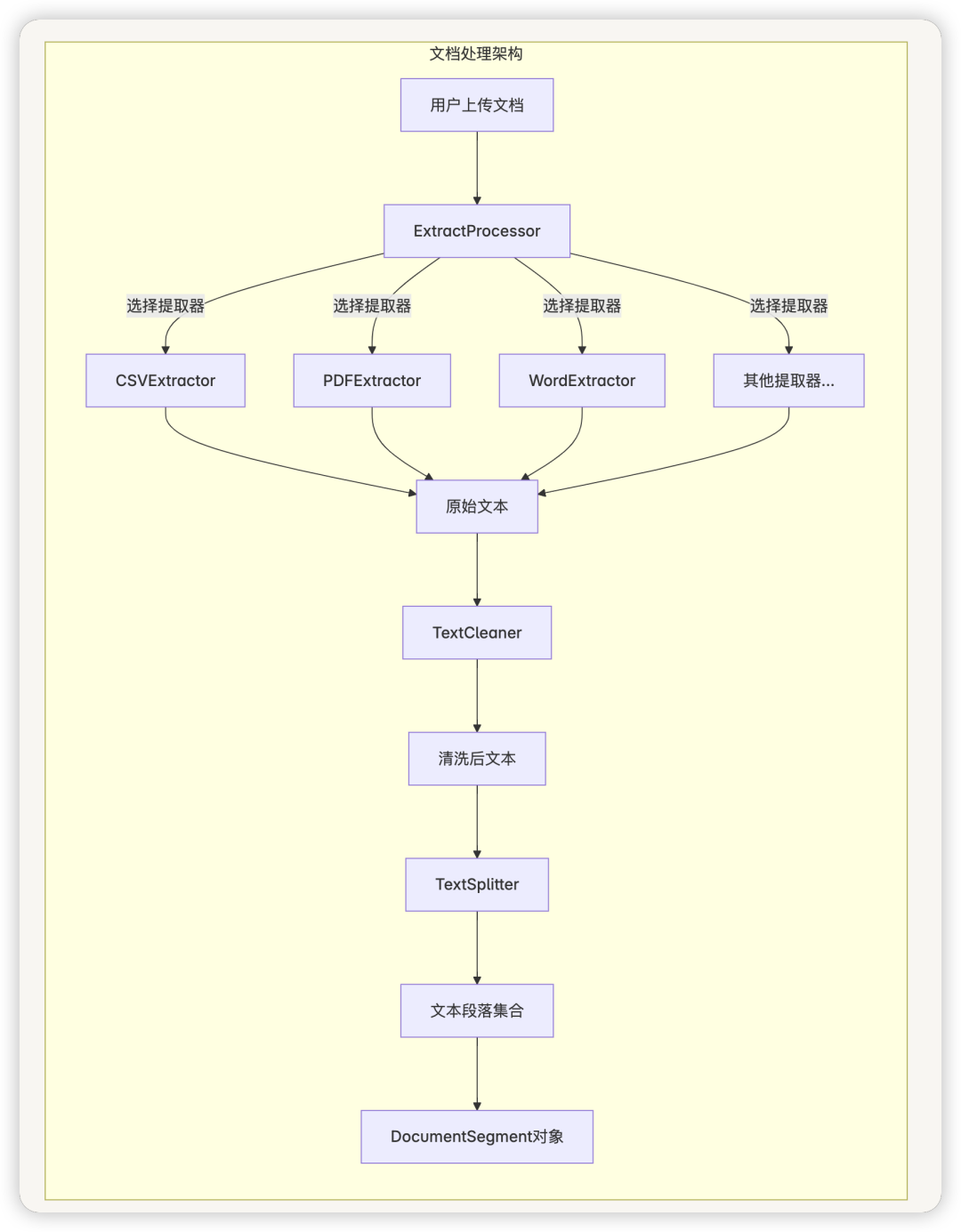
2.3 核心组件
ExtractProcessor
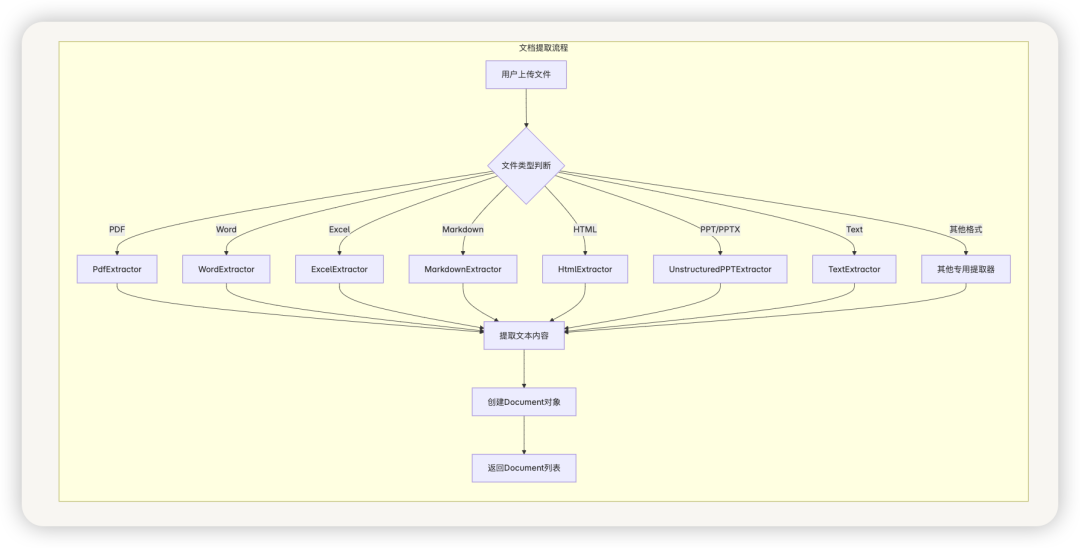
ExtractProcessor是文档处理的入口,负责根据文档类型选择合适的提取器进行文本提取。它支持多种文档格式,包括:
提取器采用策略模式设计,可以轻松扩展以支持新的文档格式。
ExtractProcessor类实现
classExtractProcessor:
@classmethod
defextract(cls, extract_setting: ExtractSetting, is_automatic: bool = False,
file_path: str = None)-> list[Document]:
# 根据数据源类型和文件类型选择合适的提取器
ifextract_setting.datasource_type == DatasourceType.FILE.value:
# 根据文件扩展名选择不同的提取器
iffile_extension =='.pdf':
extractor = PdfExtractor(file_path)
eliffile_extensionin['.md','.markdown']:
extractor = UnstructuredMarkdownExtractor(file_path) \
ifis_automaticelseMarkdownExtractor(file_path)
# ... 其他文件类型的处理
returnextractor.extract()
文档提取流程
TextSplitter
TextSplitter负责将长文本分割成适当大小的段落,是 RAG 系统性能的关键组件。它提供以下功能:
- 支持不同的分词器(Tiktoken、HuggingFace)进行准确的 token 计算
分割策略可以通过处理规则进行配置,允许用户根据不同类型的文档调整分割参数。
TextSplitter实现类
classTextSplitter(BaseDocument, ABC):
def__init__(
self,
chunk_size: int =4000,
chunk_overlap: int =200,
length_function: Callable[[str], int] = len,
keep_: bool = False,
add_start_index: bool = False,
)->None:
# 初始化分割器参数
self._chunk_size = chunk_size
self._chunk_overlap = chunk_overlap
self._length_function = length_function
self._keep_separator = keep_separator
self._add_start_index = add_start_index
@abstractmethod
defsplit_text(self, text: str)-> list[str]:
"""Split text into multiple components."""
defcreate_documents(
self, texts: list[str], metadatas: Optional[list[dict]] = None
)-> list[Document]:
# 从分割后的文本创建文档对象
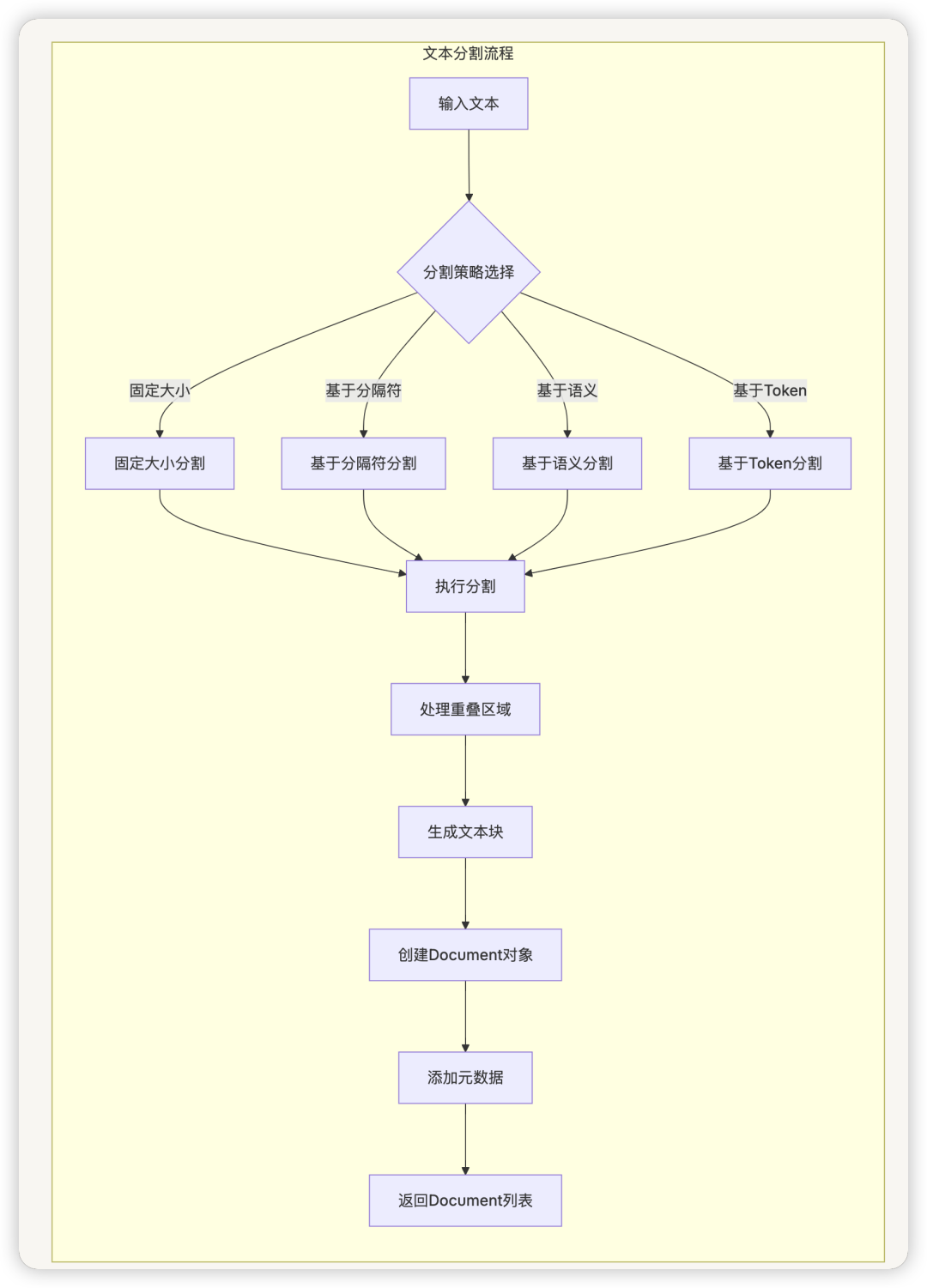
文档切块是RAG中的关键步骤,Dify 使用TextSplitter类及其子类来实现不同的切块策略:
FixedRecursiveCharacterTextSplitter:固定大小的递归字符分割EnhanceRecursiveCharacterTextSplitter:增强的递归字符分割
切块后的文档片段会保留原始文档的元数据,并添加唯一标识符(doc_id)和内容哈希值(doc_hash)。
文本分割流程
TextCleaner
TextCleaner负责文本清洗,去除不必要的格式和噪声,提高索引和检索质量。清洗操作包括:
三、向量化与索引模块
3.1 设计思路
向量化与索引模块负责将文本段落转换为向量表示并存储在向量数据库中,同时创建关键词索引以支持混合搜索。该模块采用工厂模式和适配器模式设计,支持多种向量数据库和嵌入模型。
主要功能包括:
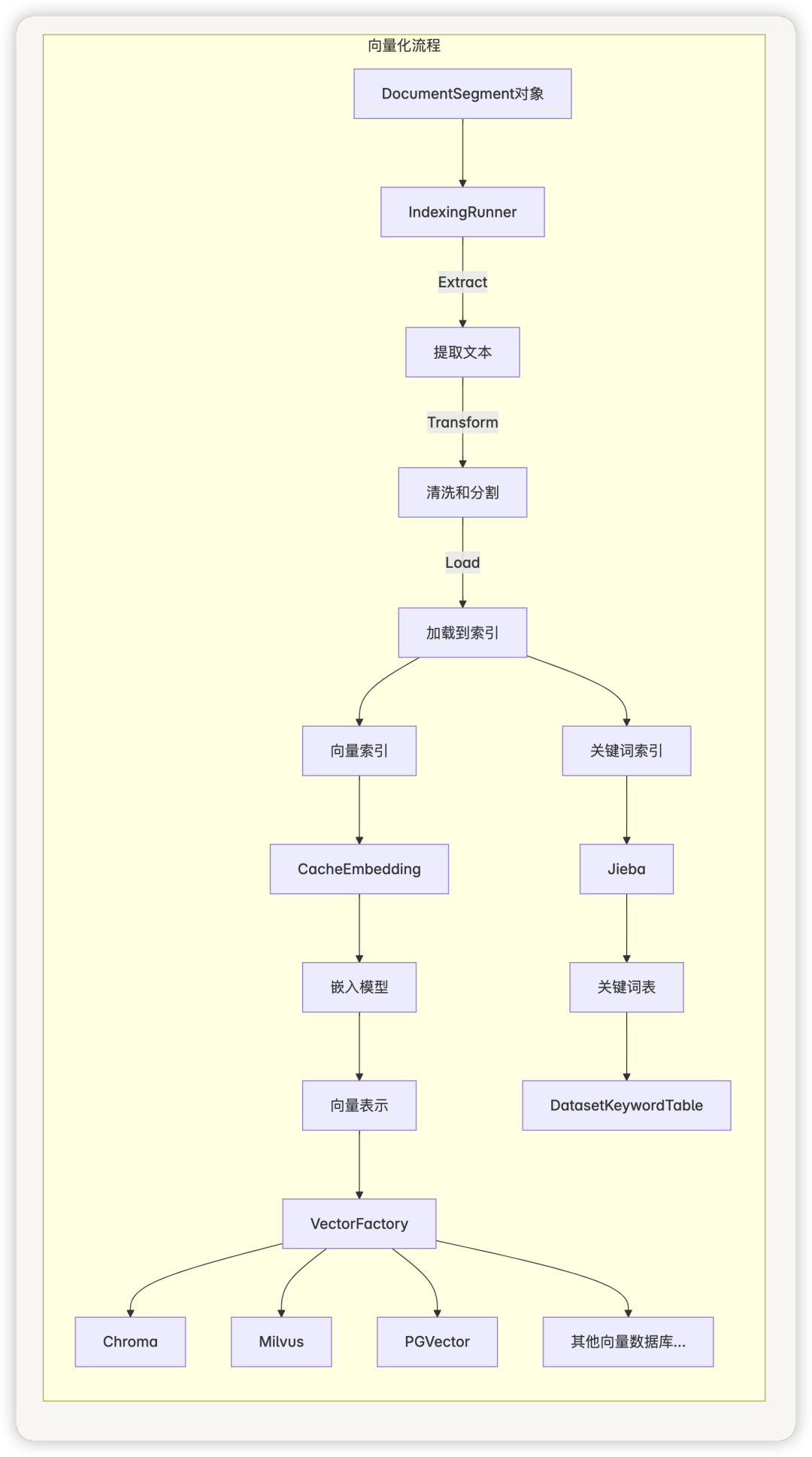
3.2 向量化流程图
3.3 核心组件
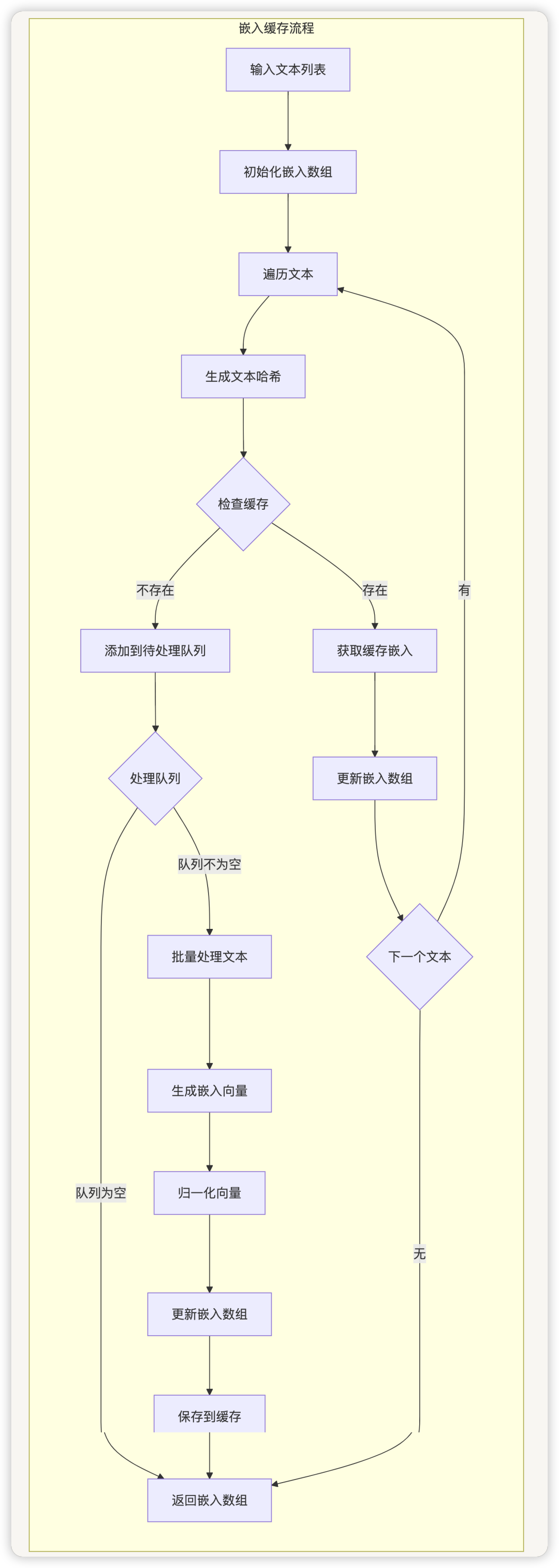
嵌入缓存(CacheEmbedding)
Dify使用CacheEmbedding类来管理文本嵌入过程,它具有缓存功能,可以避免重复计算嵌入向量:
- 如果不存在,调用嵌入模型生成向量,并将结果存入缓存
classCacheEmbedding(Embeddings):
def__init__(self, model_instance: ModelInstance, user: Optional[str] = None)->None:
self._model_instance = model_instance
self._user = user
defembed_documents(self, texts: list[str])-> list[list[]]:
# 使用文档嵌入缓存或存储(如果不存在)
text_embeddings = [Nonefor_inrange(len(texts))]
embedding_queue_indices = []
# 检查缓存中是否存在嵌入
fori, textinenumerate(texts):
hash = helper.generate_text_hash(text)
embedding = db.session.query(Embedding).filter_by(
model_name=self._model_instance.model,
hash=hash,
provider_name=self._model_instance.provider
).first()
ifembedding:
text_embeddings[i] = embedding.get_embedding()
else:
embedding_queue_indices.append(i)
# 处理未缓存的嵌入
ifembedding_queue_indices:
# 生成嵌入并缓存
嵌入缓存流程
向量工厂(VectorFactory)
Dify 支持多种向量数据库,通过工厂模式实现:
classVector:
def__init__(self, dataset: Dataset, attributes: list = None):
ifattributesisNone:
attributes = ['doc_id','dataset_id','document_id','doc_hash']
self._dataset = dataset
self._embeddings = self._get_embeddings()
self._attributes = attributes
self._vector_processor = self._init_vector()
def_init_vector(self)-> BaseVector:
vector_type = dify_config.VECTOR_STORE
ifself._dataset.index_struct_dict:
vector_type = self._dataset.index_struct_dict['type']
vector_factory_cls = self.get_vector_factory(vector_type)
returnvector_factory_cls().init_vector(self._dataset, self._attributes, self._embeddings)
@staticmethod
defget_vector_factory(vector_type: str)-> type[AbstractVectorFactory]:
match vector_type:
case VectorType.CHROMA:
core.rag.datasource.vdb.chroma.chroma_vectorimportChromaVectorFactory
returnChromaVectorFactory
# ... 其他向量数据库的支持
向量工厂模式

支持的向量数据库包括:
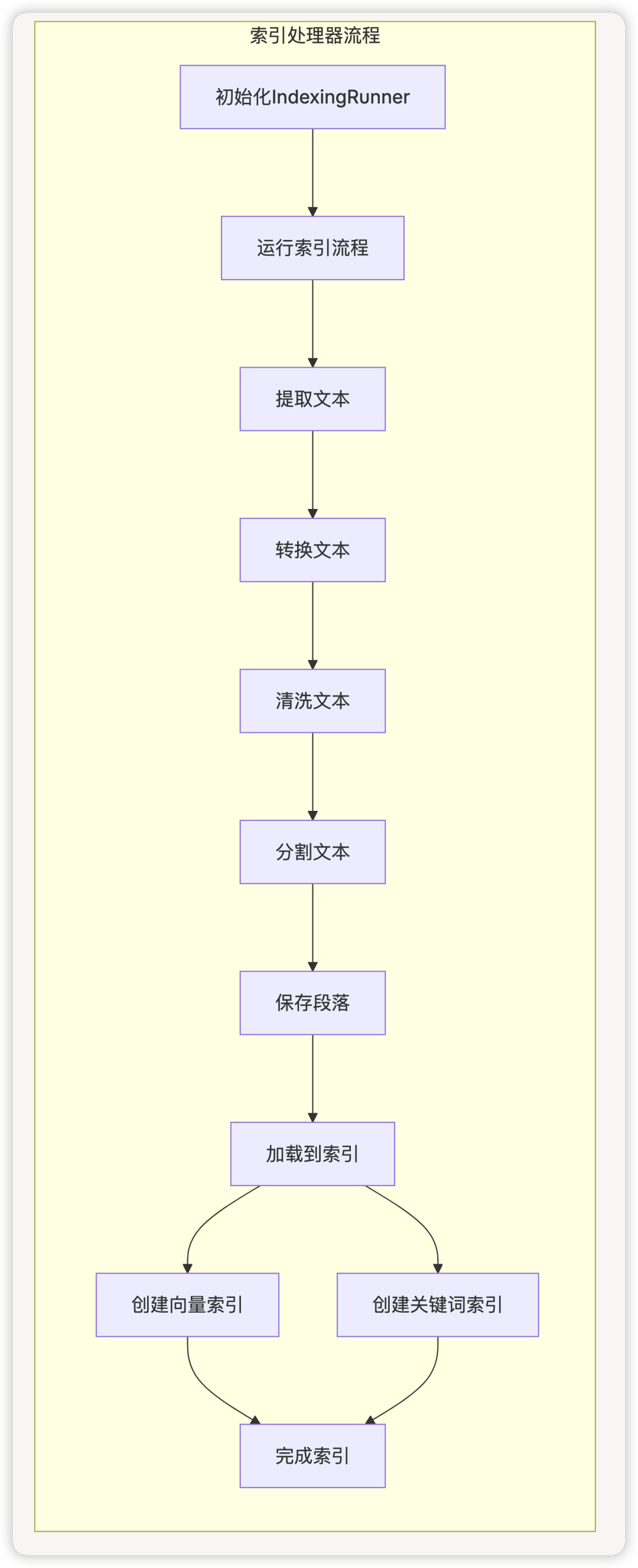
索引处理器(IndexingRunner)
IndexingRunner负责协调整个索引过程,包括文档提取、转换和加载。它实现了完整的 ETL 流程:
- Load:将处理后的段落加载到向量数据库和关键词索引中
classIndexingRunner:
def__init__(self, dataset, document_id, document_model, document_content, document_metadata, tenant_id, user_id):
# 初始化
defrun(self):
# 1. 提取文本
documents = self.extract()
# 2. 转换(分割和清洗)
= self.transform(documents)
# 3. 保存段落
self.save_segments()
# 4. 加载到索引
self.load()
索引处理流程
段落索引处理器(ParagraphIndexProcessor)
段落索引处理器实现了提取、转换、加载和检索方法:
classParagraphIndexProcessor(IndexProcessorBase):
defextract(self, extract_setting: ExtractSetting)-> list[Document]:
# 提取文档
returnExtractProcessor.extract(extract_setting)
deftransform(self, documents: list[Document])-> list[Document]:
# 清洗和分割文本
cleaned_documents = self.clean(documents)
returnself.split(cleaned_documents)
defload(self, dataset_id: str,: list[Document])->None:
# 创建向量索引和关键词索引
self.create_vector_index(dataset_id, segments)
self.create_keyword_index(dataset_id, segments)
defretrieve(self, dataset_id: str, query: str, **kwargs)-> list[Document]:
# 调用检索服务
returnService.retrieve(
retrival_method=kwargs.get('_method','semantic_search'),
dataset_id=dataset_id,
query=query,
top_k=kwargs.get('top_k',2),
score_threshold=kwargs.get('score_threshold',0.0),
reranking_model=kwargs.get('reranking_model'),
reranking_mode=kwargs.get('reranking_mode','reranking_model'),
weights=kwargs.get('weights')
)

Jieba关键词索引
Jieba组件负责从文本中提取关键词并建立索引,支持关键词搜索和混合搜索。它提供:
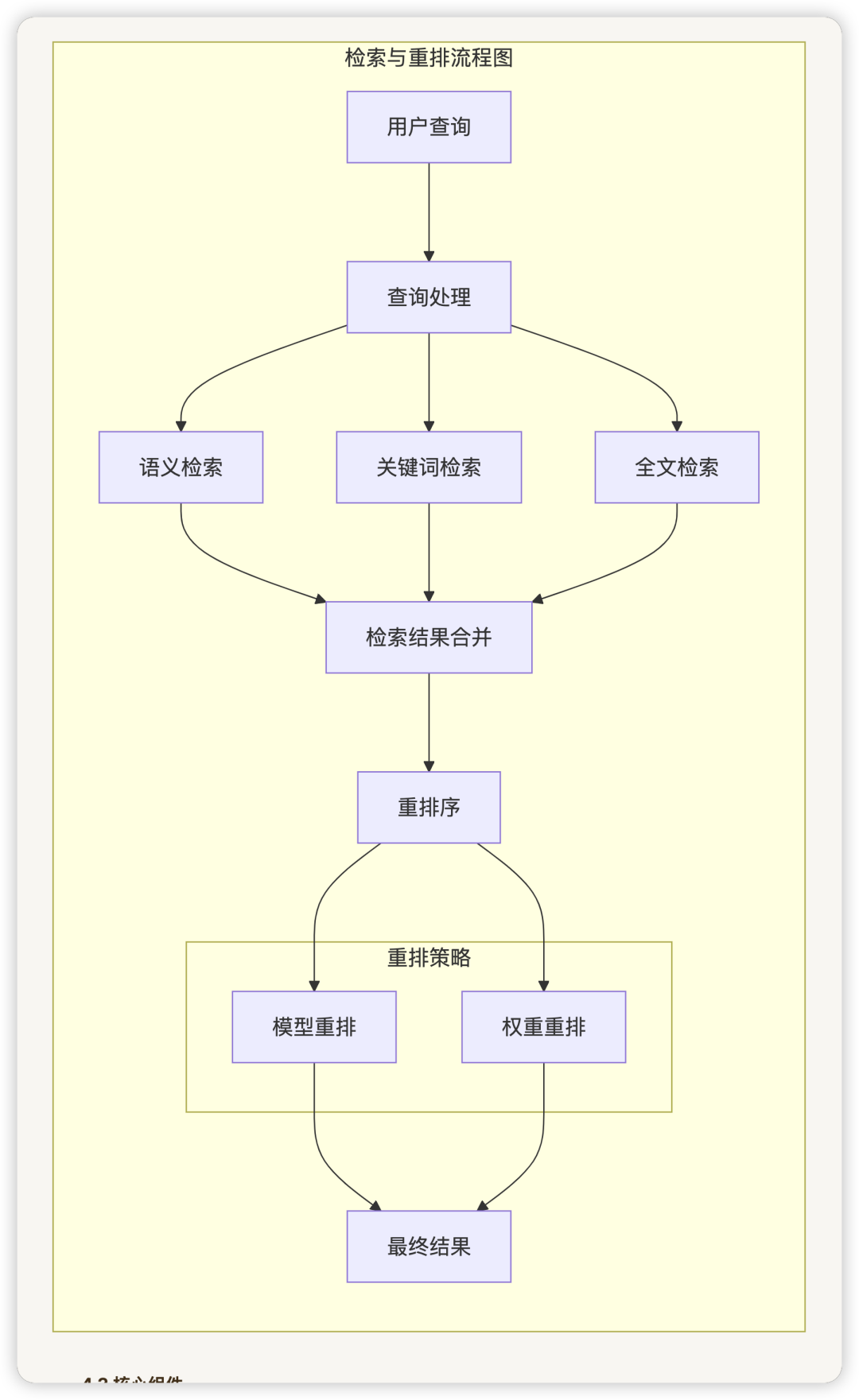
四、检索与重排模块
4.1 设计思路
检索与重排模块负责根据用户查询找到最相关的文本段落,并对结果进行优化排序。该模块支持多种检索方法和重排策略,可以根据不同场景进行配置。
主要功能包括:
4.2 检索与重排流程图
4.3 核心组件
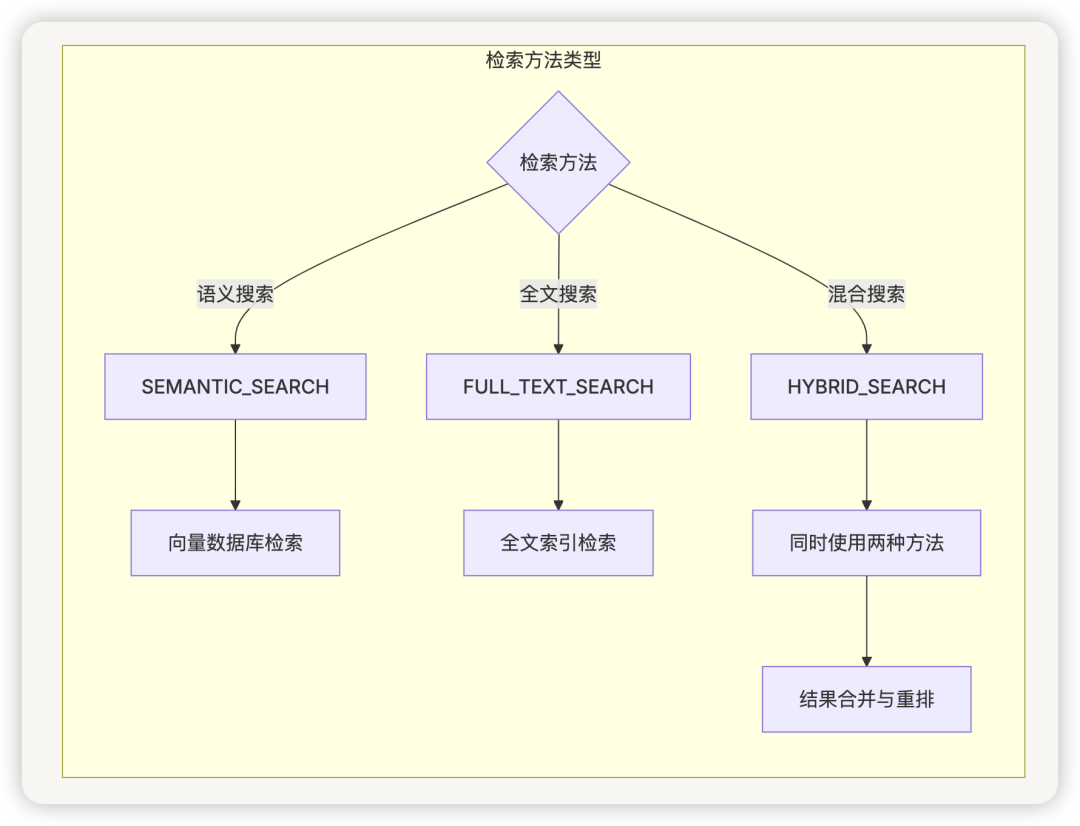
检索方法(RetrievalMethod)
RetrievalMethod是一个枚举类,定义了系统支持的检索方法:
- SEMANTIC_SEARCH:语义搜索,基于向量相似度
- FULL_TEXT_SEARCH:全文搜索,基于倒排索引
- HYBRID_SEARCH:混合搜索,结合语义和关键词
classMethod(Enum):
SEMANTIC_SEARCH ='semantic_search'
FULL_TEXT_SEARCH ='full_text_search'
HYBRID_SEARCH ='hybrid_search'
@staticmethod
defis_support_semantic_search(retrieval_method: str)-> bool:
returnretrieval_methodin{Method.SEMANTIC_SEARCH.value, RetrievalMethod.HYBRID_SEARCH.value}
@staticmethod
defis_support_fulltext_search(_method: str)-> bool:
returnretrieval_methodin{RetrievalMethod.FULL_TEXT_SEARCH.value, RetrievalMethod.HYBRID_SEARCH.value}
检索方法流程图
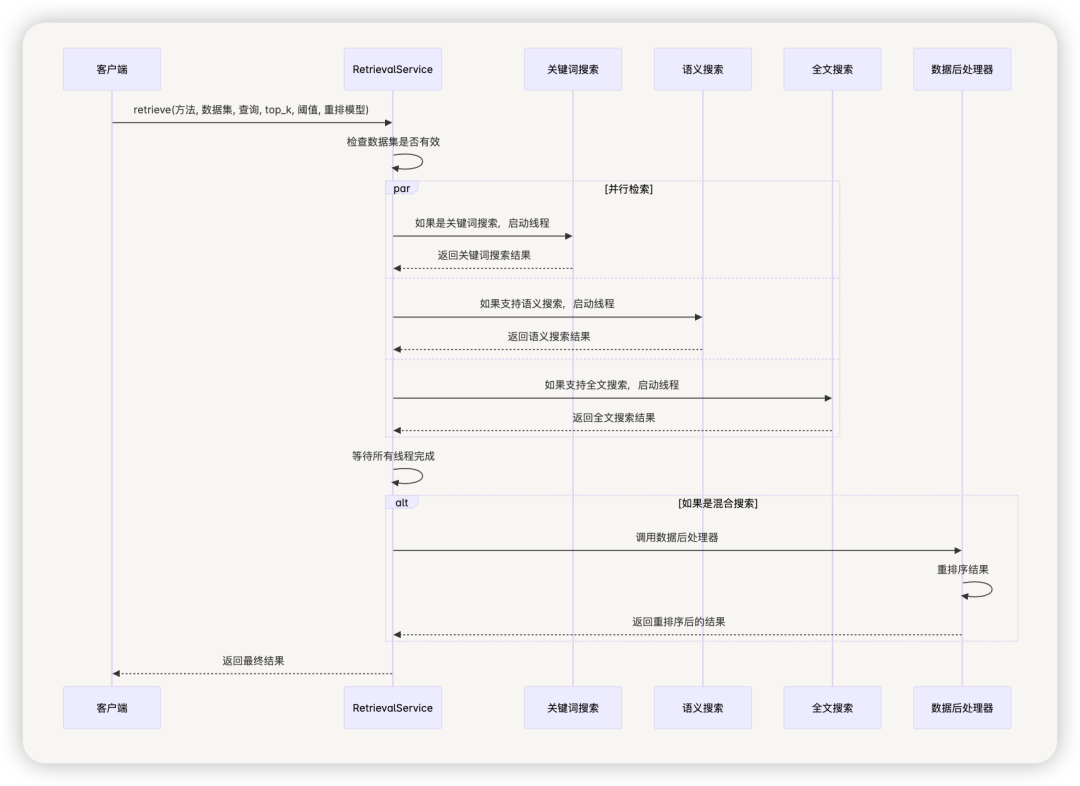
检索服务(RetrievalService)
Service是检索功能的核心实现,负责根据配置的检索方法执行搜索并返回结果。它提供以下功能:
主要方法包括:
retrieve:主检索方法,根据检索方法执行搜索embedding_search:向量相似度搜索实现full_text_index_search:全文索引搜索实现
检索服务协调不同的检索方法并处理结果:
classService:
@classmethod
defretrieve(cls, retrival_method: str, dataset_id: str, query: str,
top_k: int, score_threshold: Optional[] =.0,
reranking_model: Optional[dict] = None, reranking_mode: Optional[str] ='reranking_model',
weights: Optional[dict] = None):
# 获取数据集
dataset = db.session.query(Dataset).filter(Dataset.id == dataset_id).first()
ifnotdatasetordataset._document_count ==0ordataset._segment_count ==0:
return[]
all_documents = []
threads = []
exceptions = []
# 关键词搜索
ifretrival_method =='keyword_search':
keyword_thread = threading.Thread(target=Service.keyword_search, kwargs={...})
threads.append(keyword_thread)
keyword_thread.start()
# 语义搜索
ifMethod.is_support_semantic_search(retrival_method):
embedding_thread = threading.Thread(target=Service.embedding_search, kwargs={...})
threads.append(embedding_thread)
embedding_thread.start()
# 全文搜索
ifMethod.is_support_fulltext_search(retrival_method):
full_text_index_thread = threading.Thread(target=RetrievalService.full_text_index_search, kwargs={...})
threads.append(full_text_index_thread)
full_text_index_thread.start()
# 等待所有线程完成
forthreadinthreads:
thread.join()
# 混合搜索需要后处理
ifretrival_method ==Method.HYBRID_SEARCH.value:
data_post_processor = DataPostProcessor(str(dataset.tenant_id), reranking_mode,
reranking_model, weights,False)
all_documents = data_post_processor.invoke(
query=query,
documents=all_documents,
score_threshold=score_threshold,
top_n=top_k
)
returnall_documents
检索服务时序图
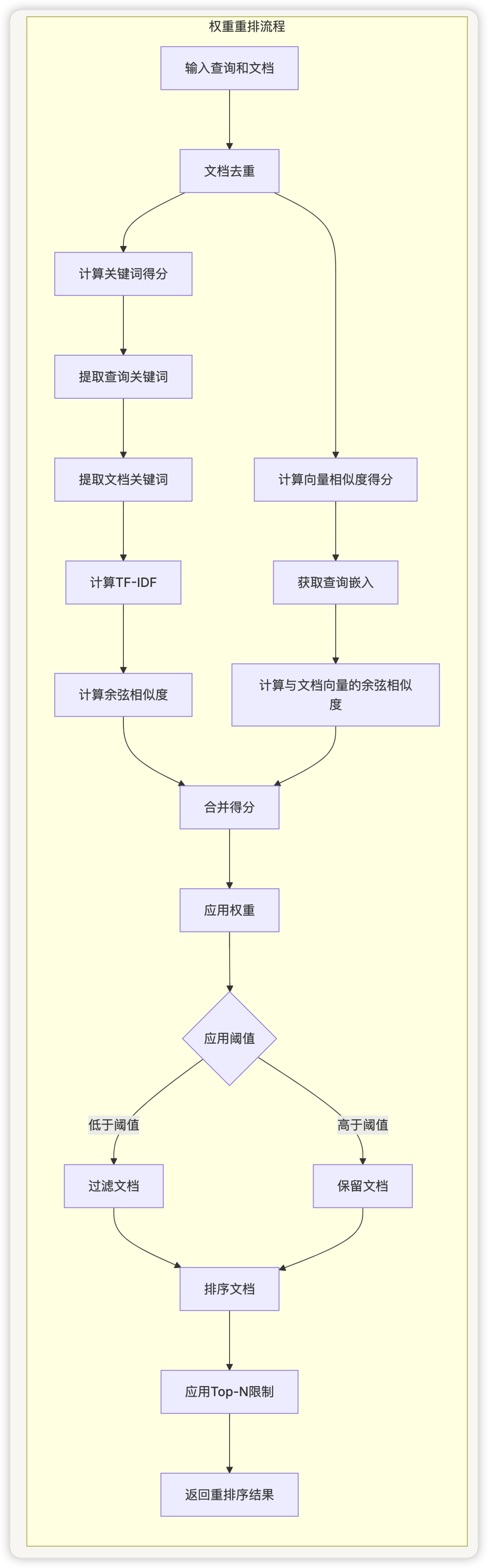
权重重排(WeightRerankRunner)
WeightRerankRunner实现了基于权重的重排序策略,可以根据不同因素对检索结果进行优化排序。它考虑以下因素:
通过调整不同因素的权重,可以优化检索结果的相关性和质量。
权重重排结合了关键词得分和向量相似度得分:
classWeightRerankRunner:
def__init__(self, tenant_id: str, weights: Weights)->None:
self.tenant_id = tenant_id
self.weights = weights
defrun(self, query: str, documents: list[Document], score_threshold: Optional[float] = None,
top_n: Optional[int] = None, user: Optional[str] = None)-> list[Document]:
# 去重
docs = []
doc_id = []
unique_documents = []
fordocumentindocuments:
ifdocument.metadata['doc_id']notindoc_id:
doc_id.append(document.metadata['doc_id'])
docs.append(document.page_content)
unique_documents.append(document)
documents = unique_documents
# 计算关键词得分和向量得分
rerank_documents = []
query_scores = self._calculate_keyword_score(query, documents)
query_vector_scores = self._calculate_cosine(self.tenant_id, query, documents, self.weights.vector_setting)
# 合并得分
fordocument, query_score, query_vector_scoreinzip(documents, query_scores, query_vector_scores):
score = self.weights.vector_setting.vector_weight * query_vector_score + \
self.weights.keyword_setting.keyword_weight * query_score
ifscore_thresholdandscore < score_threshold:
continue
document.metadata['score'] = score
rerank_documents.append(document)
# 排序并返回结果
rerank_documents = sorted(rerank_documents, key=lambdax: x.metadata['score'], reverse=True)
returnrerank_documents[:top_n]iftop_nelsererank_documents
权重重排流程图
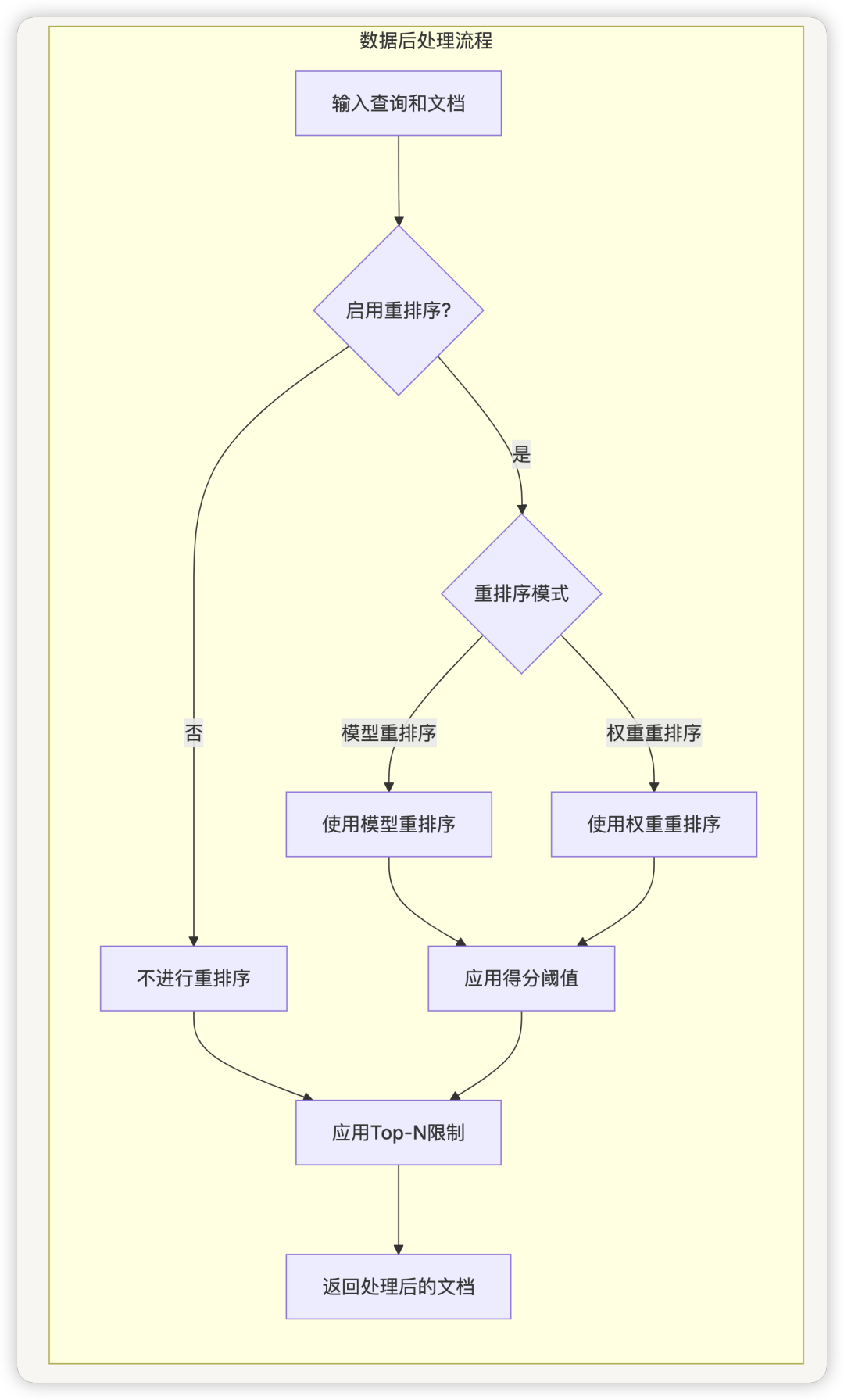
数据后处理器(DataPostProcessor)
DataPostProcessor负责对检索结果进行后处理,包括重排序、去重和格式化。它支持多种重排序策略,可以根据不同场景进行配置。
数据后处理器负责重排序和结果处理:
classDataPostProcessor:
def__init__(self, tenant_id: str, reranking_mode: str, reranking_model: Optional[dict],
weights: Optional[dict], enable_reranking: bool = True):
# 初始化
definvoke(self, query: str, documents: list[Document], score_threshold: Optional[float] = None,
top_n: Optional[int] = None)-> list[Document]:
# 根据模式选择重排序方法
ifself.enable_rerankingandself.reranking_mode == RerankMode.RERANKING_MODEL.value:
# 使用模型重排序
returnself.rerank_model_runner.run(query, documents, score_threshold, top_n)
elifself.enable_rerankingandself.reranking_mode == RerankMode.WEIGHT.value:
# 使用权重重排序
returnself.weight_rerank_runner.run(query, documents, score_threshold, top_n)
else:
# 不重排序,直接返回
returndocuments[:top_n]iftop_nelsedocuments
数据后处理流程图
五、总结
Dify 的 RAG 系统是一个功能完整、灵活可扩展的检索增强生成框架,具有以下特点:
多格式文档支持:支持 PDF、Word、Excel、Markdown、HTML、CSV 等多种文档格式。
灵活的文本分块:支持多种分块策略,包括固定大小、基于分隔符和基于语义的分块。
高效的向量化:实现了嵌入缓存机制,提高了向量化效率。
多样的存储选项:支持 Chroma、Milvus、PGVector、Qdrant 等多种向量数据库。
多种检索方法:支持语义搜索、全文搜索、关键词搜索和混合搜索。
高级重排序:支持基于模型的重排序和基于权重的重排序。
并行处理:使用多线程并行执行不同的检索方法,提高效率。
可扩展架构:采用工厂模式和抽象基类,便于扩展新的功能。
通过这些组件的协同工作,Dify 的 RAG 系统能够有效地处理和检索大量文档,为大语言模型提供准确的上下文信息,从而生成更加准确和相关的回答。ingFang SC", system-ui, -apple-system, "system-ui", "Helvetica Neue", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; font-size: 17px; letter-spacing: 0.544px; text-align: right; word-spacing: 0px; -webkit-tap-highlight-color: transparent; margin: 0px; padding: 0px; outline: 0px; max-width: 100%; box-sizing: border-box !important; overflow-wrap: break-word !important;">










