Fine-Tuning,即微调。我尝试用我的理解叙述微调的含义:在原有模型的基础上,通过补充一些数据,用这些补充的数据对原有模型进行训练,训练的过程对原有模型的部分参数进行调整,从而使模型能在某些特定的场景下表现更优。
所以,大模型微调可以提高其在特定场景下的表现,同时,会降低大模型在通用场景下的能力。
今天,我们从一个简单的例子入手,先来感受下Fine-Tune微调到底是什么。这个例子可以在笔记本电脑上跑,需要的配置不高。在开始本文的实践案例前,你可以对模型训练一窍不通,本文将带你跑通整个过程,同时解释其中一些概念。
0. 环境准备
使用模型训练利器 huggingface(http://www.huggingface.co/)来进行模型训练和微调。执行以下代码进行安装:
#pip安装
pipinstalltransformers#安装最新的版本
#conda安装
condainstall-chuggingfacetransformers#只4.0以后的版本
huggingface简介:
1. 加载训练数据集
这里可以直接使用datasets库中的load_dataset函数进行在线加载,只需要指定HuggingFace中的数据集名称即可。
本文以 rotten_tomatoes 数据集为例。
这是一个对电影评论进行情感分类的数据集。
save_to_disk函数用来将加载的数据集保存到本地的一个目录下。
将加载到的数据集分成 train 部分和 validation 部分。
importdatasets
fromdatasetsimportload_dataset
#数据集名称
DATASET_NAME="rotten_tomatoes"
#加载数据集
raw_datasets=load_dataset(DATASET_NAME)
raw_datasets.save_to_disk(os.path.join("D:\\GitHub\\LEARN_LLM\\FineTune\\FineTune1\\data",DATASET_NAME))
#训练集
raw_train_dataset=raw_datasets["train"]
#验证集
raw_valid_dataset=raw_datasets["validation"]
2. 加载模型
这里直接使用transformers库中AutoModelForCausalLM的from_pretrained函数,填入预训练的模型名称,然后它就会在运行过程中自动在线加载该模型。本文使用 gpt2 模型。
fromtransformersimportAutoModelForCausalLM
#模型名称
MODEL_NAME="gpt2"
#加载模型
model=AutoModelForCausalLM.from_pretrained(MODEL_NAME,trust_remote_code=True)
3. 加载 Tokenizer
通过HuggingFace,可以指定模型名称,运行时自动下载对应Tokenizer。直接使用transformers库中AutoTokenizer的from_pretrained函数,填入对应的模型名称。
fromtransformersimportAutoTokenizer,AutoModel
#加载tokenizer
tokenizer=AutoTokenizer.from_pretrained(MODEL_NAME,trust_remote_code=True)
tokenizer.add_special_tokens({'pad_token':'[PAD]'})
tokenizer.pad_token_id=0
4. 处理训练数据集
使用datasets库中的map函数进行数据处理。map函数参数如下:
map(
function:Optional[Callable]=None,
with_indices:bool=False,
with_rank:bool=False,
input_columns:Optional[Union[str,List[str]]]=None,
batched:bool=False,
batch_size:Optional[int]=1000,
drop_last_batch:bool=False,
remove_columns:Optional[Union[str,List[str]]]=None,
keep_in_memory:bool=False,
load_from_cache_file:bool=True,
cache_file_names:Optional[Dict[str,Optional[str]]]=None,
writer_batch_size:Optional[int]=1000,
features:Optional[Features]=None,
disable_nullable:bool=False,
fn_kwargs:Optional[dict]=None,
num_proc:Optional[int]=None,
desc:Optional[str]=None,
)
该函数通过一个映射函数function,处理Dataset中的每一个元素。如果不指定function,则默认的函数为lambda x: x。
参数batched表示是否进行批处理
参数batch_size表示批处理的大小,也就是每次处理多少个元素,默认为1000。
参数drop_last_batch表示当最后一批的数量小于batch_size,是否处理最后一批。
remove_columns表示要删除的列的名称,删除列是在数据处理结束后删除,不影响function的使用
数据处理过程代码:
#标签集
named_labels=['neg','pos']
#标签转token_id
label_ids=[
tokenizer(named_labels[i],add_special_tokens=False)["input_ids"][0]
foriinrange(len(named_labels))
]
MAX_LEN=32#最大序列长度(输入+输出)
DATA_BODY_KEY="text"#数据集中的输入字段名
DATA_LABEL_KEY="label"#数据集中输出字段名
#定义数据处理函数,把原始数据转成input_ids,attention_mask,labels
defprocess_fn(examples):
model_inputs={
"input_ids":[],
"attention_mask":[],
"labels":[],
}
foriinrange(len(examples[DATA_BODY_KEY])):
inputs=tokenizer(examples[DATA_BODY_KEY][i],add_special_tokens=False)
label=label_ids[examples[DATA_LABEL_KEY][i]]
input_ids=inputs["input_ids"]+[tokenizer.eos_token_id,label]
raw_len=len(input_ids)
input_len=len(inputs["input_ids"])+1
ifraw_len>=MAX_LEN:
input_ids=input_ids[-MAX_LEN:]
attention_mask=[1]*MAX_LEN
labels=[-100]*(MAX_LEN-1)+[label]
else:
input_ids=input_ids+[0]*(MAX_LEN-raw_len)
attention_mask=[1]*raw_len+[tokenizer.pad_token_id]*(MAX_LEN-raw_len)
labels=[-100]*input_len+[label]+[-100]*(MAX_LEN-raw_len)
model_inputs["input_ids"].append(input_ids)
model_inputs["attention_mask"].append(attention_mask)
model_inputs["labels"].append(labels)
returnmodel_inputs
#处理训练数据集
tokenized_train_dataset=raw_train_dataset.map(
process_fn,
batched=True,
remove_columns=raw_train_dataset.column_names,
desc="Runningtokenizerontraindataset",
)
#处理验证数据集
tokenized_valid_dataset=raw_valid_dataset.map(
process_fn,
batched=True,
remove_columns=raw_valid_dataset.column_names,
desc="Runningtokenizeronvalidationdataset",
)
5. 定义数据规整器
训练时自动将数据拆分成 Batch
#定义数据校准器(自动生成batch)
collater=DataCollatorWithPadding(
tokenizer=tokenizer,return_tensors="pt",
)
6. 定义训练超参
LR=2e-5#学习率
BATCH_SIZE=8#Batch大小
INTERVAL=100#每多少步打一次log/做一次eval
#定义训练参数
training_args=TrainingArguments(
output_dir="./output",#checkpoint保存路径
evaluation_strategy="steps",#每N步做一次eval
overwrite_output_dir=True,
num_train_epochs=1,#训练epoch数
per_device_train_batch_size=BATCH_SIZE,#每张卡的batch大小
gradient_accumulation_steps=1,#累加几个step做一次参数更新
per_device_eval_batch_size=BATCH_SIZE,#evaluationbatchsize
logging_steps=INTERVAL,#每INTERVAL步log一次
save_steps=INTERVAL,#每INTERVAL步保存一个checkpoint
learning_rate=LR,#学习率
)
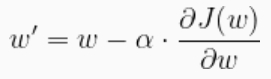
Batch Size:是指在训练时,一次提供给模型的数据的数量。在训练时,模型需要对整个训练数据集进行训练,但是数据集通常很大,如果一次把整个数据集提供给模型训练,可能导致内存不足或运算时间太长。因此,我们通常将数据集分成若干个Batch,每次提供一个Batch给模型训练。Batch Size就是指一个Batch中数据的数量。
训练epoch数:在训练模型时,通常会设定训练的epoch数,这意味着模型会在训练数据集上训练多少遍。训练epoch数较多意味着模型会更加充分地学习训练数据集,但同时也会增加训练时间。
检查点(CheckPoints):是指通过周期性(迭代/时间)的保存模型的完整状态,在模型训练失败时,可以从保存的检查点模型继续训练,以避免训练失败时每次都需要从头开始带来的训练时间浪费。检查点模式适用于模型训练时间长、训练需要提前结束、fine-tune等场景,也可以拓展到异常时的断点续训场景。
7. 定义训练器
#节省显存
model.gradient_checkpointing_enable()
#定义训练器
trainer=Trainer(
model=model,#待训练模型
args=training_args,#训练参数
data_collator=collater,#数据校准器
train_dataset=tokenized_train_dataset,#训练集
eval_dataset=tokenized_valid_dataset,#验证集
#compute_metrics=compute_metric,#计算自定义评估指标
)
8. 开始训练
#开始训练
trainer.train()
全部的依赖包如下:
importdatasets
fromdatasetsimportload_dataset
fromtransformersimportAutoTokenizer,AutoModel
fromtransformersimportAutoModelForCausalLM
fromtransformersimportTrainingArguments,Seq2SeqTrainingArguments
fromtransformersimportTrainer,Seq2SeqTrainer
importtransformers
fromtransformersimportDataCollatorWithPadding
fromtransformersimportTextGenerationPipeline
importtorch
importnumpyasnp
importos,re
fromtqdmimporttqdm
importtorch.nnasnn
运行成功后的样子如下,会显示当前训练进度、预计耗时等:
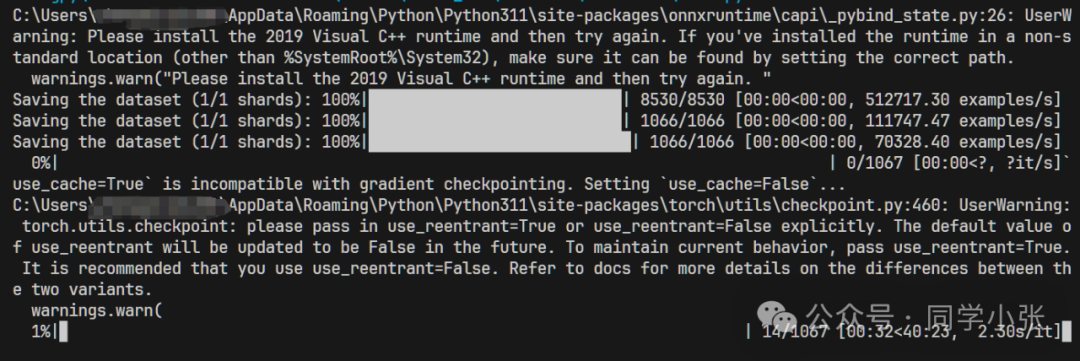
训练完之后: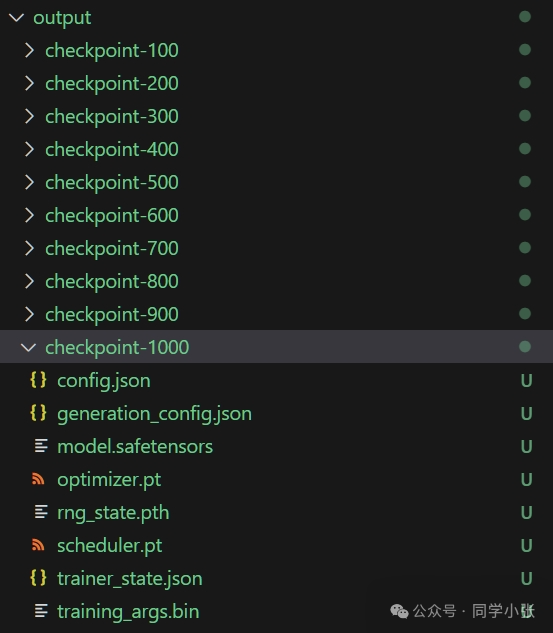
9. 总结
本文以Hugging face上的情感分类数据集和gpt2模型为例,展示了训练过程。同时针对Hugging face训练模型的一些接口和一些概念做了简要介绍,零基础也可以跑通该例子。
总结模型训练的过程:
(1)加载数据集
(2)数据预处理
(3)加载模型
(4)加载模型的Tokenizer
(5)定义数据规整器
(6)定义训练超参:学习率、批次大小、…
(7)定义训练器
(8)开始训练
通过这个流程,你就能跑通模型训练过程。










