|
OpenAI的产品负责人 Miquel 联合Piotr 发布了一份超全面的Context Engineering 深度指南 (原文付费,主要是图多,还给了例子~) 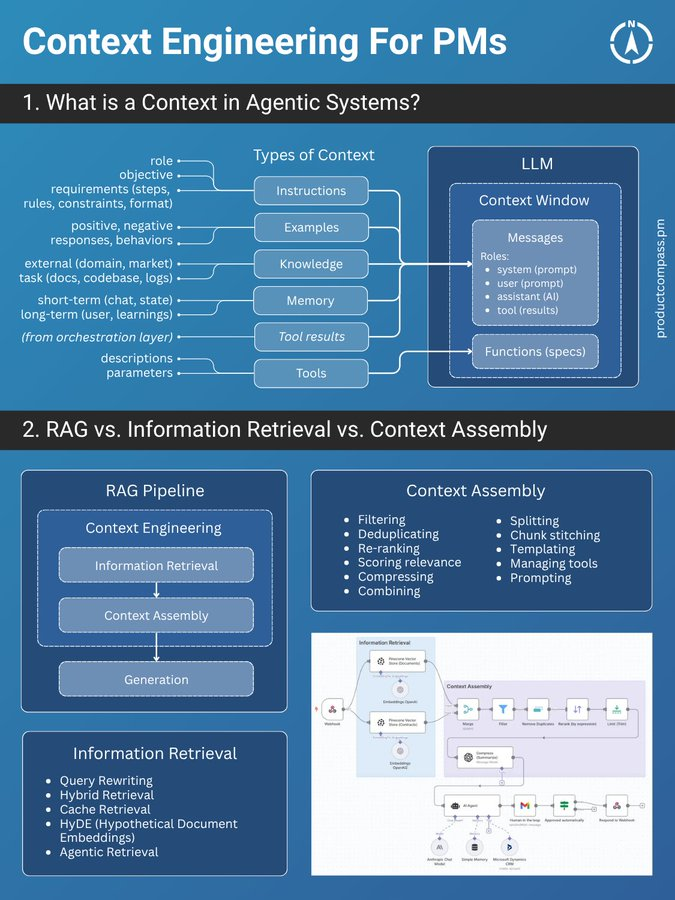 到底什么是 Context Engineering简单说,Context Engineering 的核心是构建一套系统,高效地为LLM的上下文窗口(Context Window)填充最优质的内容,从而最大化模型的性能。 如果你觉得提示词工程(Prompt Engineering)就是全部,那格局就小了。 提示词工程只是在用户与AI交互的最后一环做文章。 而上下文工程是一个更广阔的战场,它涵盖了在生成提示词之前的所有准备活动——从数据检索、筛选到信息组装,它是一个完整的系统工程。 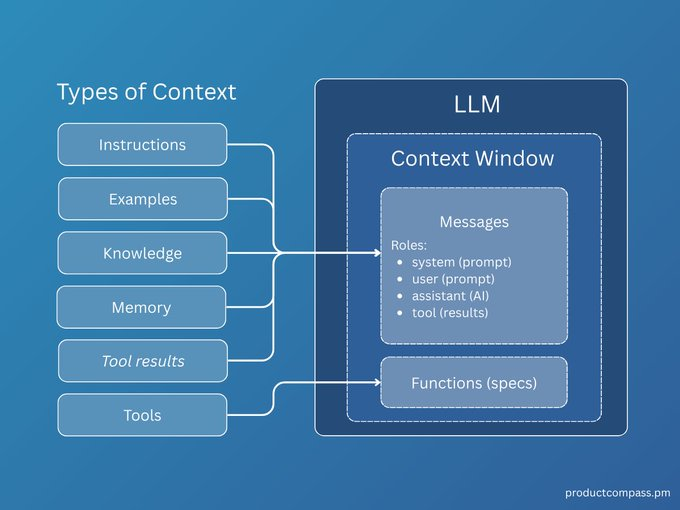 给AI提供的6种核心上下文那么,我们到底在给模型的上下文中“喂”些什么呢?共有6种核心类型: - 指令 (Instructions):最直接的命令,告诉模型“你要做什么”。
- 范例 (Examples):也就是Few-shot,给模型几个例子,让它照着学。
- 知识 (Knowledge):从外部数据源(如RAG)检索到的信息,作为回答的依据。
- 记忆 (Memory):存储过去的对话历史,让AI有“记忆力”。
- 工具结果 (Tool results):调用API或外部工具后返回的结果。
- 工具 (Tools):告诉模型它有哪些工具(API、函数)可以用。
这6种核心内容共同构成了一个AI Agent的“世界观”和“行动力”。 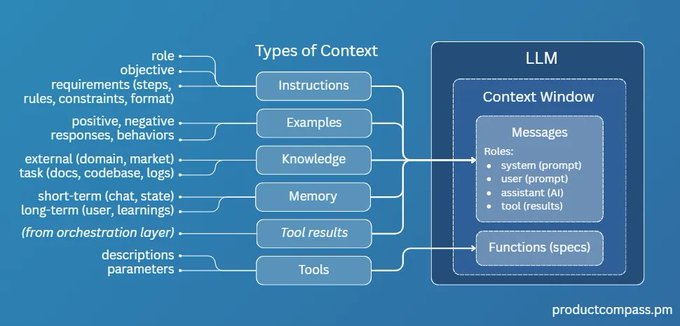 RAG只是其中一环,别神话了!聊到上下文,很多人第一反应就是RAG(检索增强生成)。RAG是上下文工程中最关键的一环,但它不是全部。 一个完整的RAG流程通常分为三步: - 信息检索 (Information Retrieval):从向量数据库、API等外部源拉取数据。
- 上下文组装 (Context Assembly):将检索到的数据进行结构化、过滤,塞进提示词。
- 生成 (Generation):LLM基于组装好的上下文生成最终回复。
上下文工程主要关注前两步,即“检索”和“组装”。它决定了最终送到LLM的内容质量如何。 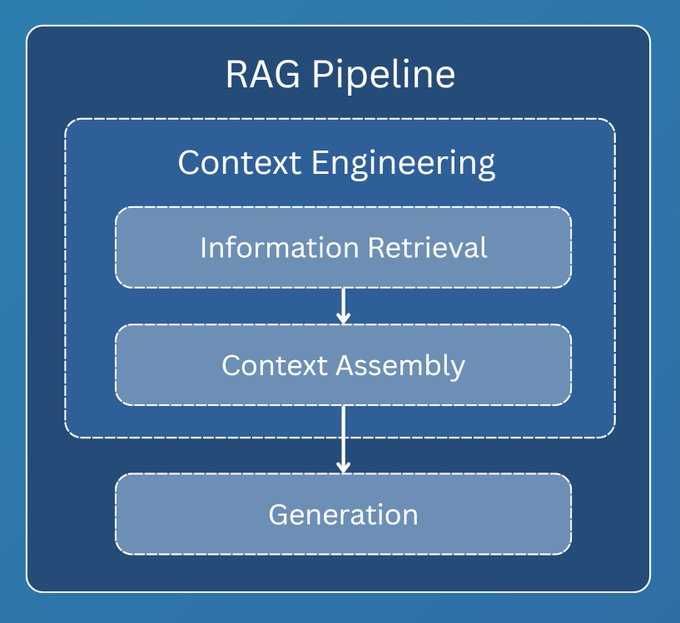 信息检索的进化信息检索技术本身也在疯狂进化。别再以为RAG就是简单地做个向量检索了,我们来快速扒一扒它的几种主流范式。 这个章节是个带交互的图,完全免费,地址在这: https://rag.productcompass.pm/ 1. Vanilla RAG最基础的版本,直接“检索+生成”,简单粗暴,效果也最拉胯。 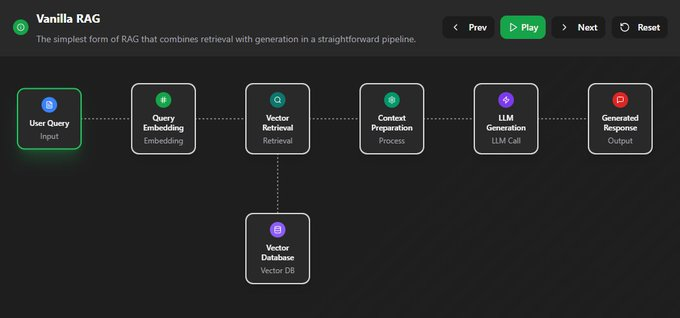 2. Standard RAG进阶版,加入了“查询重写”和“结果重排”,先优化问题,再筛选答案,质量更高。 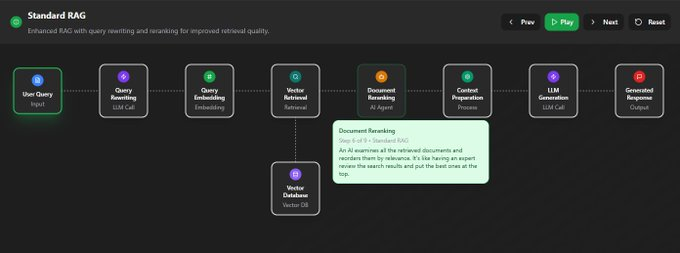 3. 缓存增强生成 (CAG)它不检索,而是提前把可能用到的信息“缓存”到上下文里。适合数据稳定且上下文窗口够大的场景。 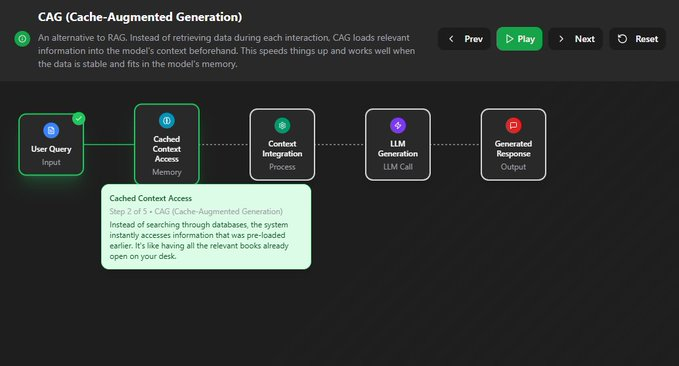 4. Hybrid RAG大力出奇迹,把多种检索方法(向量、关键词、知识图谱等)全用上,追求最全面的信息。 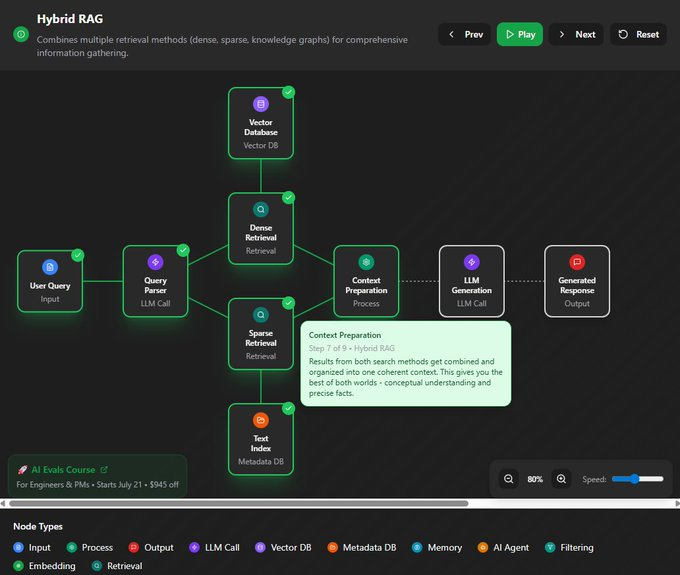 5. 假设性文档嵌入 (HyDE)它先让LLM根据你的问题,脑补一篇“完美的答案”(假设性文档),然后再用这个脑补的答案去匹配真实文档,据说能解决查询和文档之间的语义鸿沟。 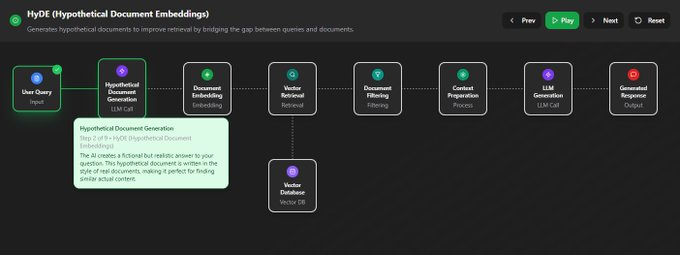 6. Agentic RAG在这里,AI Agent会自己决定何时、何地、如何去检索信息,它能进行动态规划和多步推理。简单来说,AI从一个被动的查询者,变成了主动的思考者和决策者。 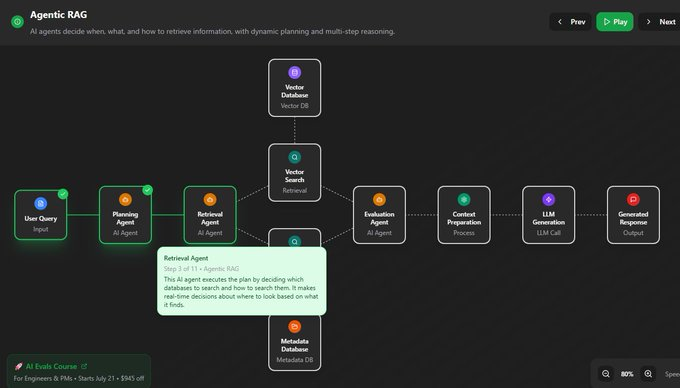 上下文组装 - Context Assembly找到了信息,怎么“喂”给模型又是一门学问。这就是上下文组装(Context Assembly)要解决的问题。 目标很简单:提供最精简、最相关、结构最清晰的信息。 这需要一系列技术,比如信息压缩、重新排序、格式化等。   例如,使用XML这样的结构化格式,可以清晰地划分不同类型的上下文,极大地帮助模型理解任务。 作者提供的lovable bug fixing Agent的示例:https://github.com/phuryn/examples/blob/main/prompts/context_engineering/bug_fixing_agent_context.xml 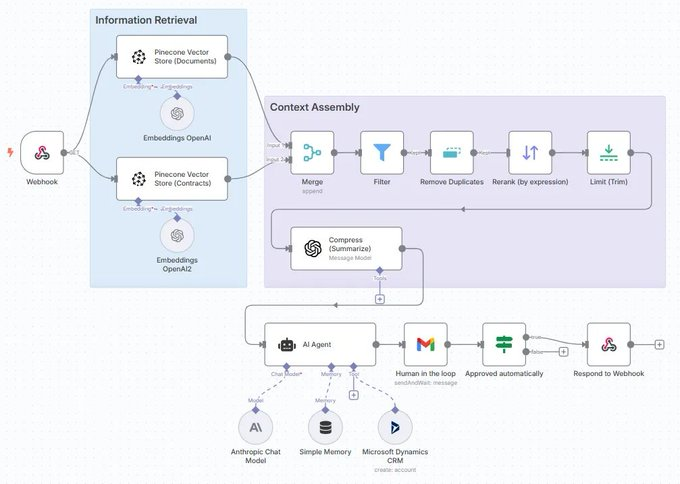 | 









