|
后训练(Post-Training)是指在预训练模型的基础上,针对特定的任务或数据集进行额外的训练。这个阶段通常涉及到微调(Fine-tuning)和对齐 (Alignment),即调整预训练模型的参数以适应新的任务。 
黑色: 预训练阶段 红色: 后训练阶段 紫色: 推理测试阶段 
Post-training重要性-后训练扩展律Post-training scaling laws 已经出现Pre-traing阶段的scaling law  
GPT(Generative Pretrained Transformer)系列是典型的自回归语言模型。在 GPT 模型中,它的生成过程是基于自回归机制。例如,在文本生成任务中,给定一个初始的输入文本序列(可以是一个单词、一个句子或一段话),模型会预测下一个单词出现的概率分布。假设输入序列是 “The cat”,模型会计算在这个序列之后不同单词(如 “runs”“jumps”“sleeps” 等)出现的概率,然后从这个概率分布中采样一个单词作为下一个生成的单词。


随着训练时的计算量和测试时的计算量的增加,模型性能也会随之提升。 这里以Llama 3来示例: 
1.持续通过人工标注或机造方式生成偏好pair样本,训练Reward Model; 2.基于当前能力最好的模型,随机采集一批{Prompt},每个Prompt拿最好的模型做K次数据生成采样,每个Prompt就得到K条< rompt,Responsek>数据; rompt,Responsek>数据; 3.拒绝采样:对第2步采样K个<rompt,Responsek>数据,用Reward Model打分,并从中选取打分最高topN条样本。作为指令微调的精选样本,训练SFT Model; 4.训完SFT Model,再通过持续收集的偏好对样本(同步骤1)做对齐学习(Llama使用的是DPO)。最终得到了一个比当前模型更好的模型; 5.持续做步骤1~步骤4,飞轮迭代优化模型。 
采样模型多次,让RM选出最好的回复,作为SFT data的一部分。部分细节如下: 采样什么模型?两种情况。迭代中表现Avg score最好的模型,或者在某个particular capability上表现最好的模型。 采样多少次?K=10~30,即一般采样10-30次。 prompt哪来?人工标注的prompts。并在后训练迭代后期引入特殊的system prompts。

采样什么模型?部署多个不同数据配比和对齐方法训练的模型,针对每个prompt选取两个不同的模型进行采样。原因:不同模型能够在不同的能力维度上表现出差异,数据质量和多样性更好。 偏好等级?四个等级:显著更好(significantly better),更好(better),稍微更好(slightly better),略微更好(marginally better)。 允许修改:标注同学可以进一步优化chosen response,最后edited > chosen > rejected。 迭代式难度:最后随着模型改进逐步提高prompt复杂度。
微调是指在预训练模型的基础上,使用特定任务的数据集进行进一步训练,以使模型适应特定任务或领域。其目的是优化模型在特定任务上的性能,使模型能够更好地适应和完成特定领域的任务。 SFT (Supvised Fine tuning ) 微调方法 全量微调 VS 部分微调 全量微调Full Fine-Tuning,FFT是指在预训练模型的基础上,使用特定任务的数据集对模型的所有参数进行进一步训练,以使模型更好地适应特定任务或领域的过程。 部分微调 PEFT(parameter-efficient fine-tuning)参数高效微调一种针对大型预训练模型的微调技术,旨在减少训练参数的数量,从而降低计算和存储成本,同时保持或提升模型性能仅微调模型中的一小部分参数,常见方法如下: 其中:  是预训练模型的原始权重矩阵。 是预训练模型的原始权重矩阵。
A 和 B 是两个低秩矩阵,其维度远小于 W。 通过这种方式,LoRA 只需要更新 A 和 B 的参数,而不是整个 W。这显著减少了需要更新的参数数量,从而提高了微调的效率。 对齐是指通过各种技术手段,使模型的输出与人类的偏好和价值观对齐,确保模型的行为和决策符合人类社会的期望和标准。对齐技术旨在解决模型可能带来的潜在问题,如生成有害内容、不符合伦理的输出等。强化学习是实现模型对齐的核心工具,即可通过人类反馈强化学习(RLHF)(Reinforcement Learning from Human Feedback)的方式,通过训练奖励模型对齐模型输出与人类偏好,强化学习中需要用到的关键组成部分如下 1. 带有人类偏好反馈的标签数据 2. 奖励模型(Reward Model)-> 奖励信号 3. 强化学习策略优化算法 DPO(Direct Preference Optimization) 直接偏好优化 PPO (Proximal Policy Optimization)近端策略优化 GRPO(Group Relative Policy Optimization)组内相关策略优化算法
强化学习策略优化算法 DPO VS PPO VS GRPORHLF即基于人类反馈的强化学习的训练流程中的涉及到的策略优化算法,常见的有以下几种: 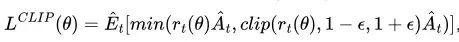
其中 是新旧策略概率之比,反映新旧策略的改进情况。 是新旧策略概率之比,反映新旧策略的改进情况。  是优势估计值,反映智能体选择某个动作的好坏。 是优势估计值,反映智能体选择某个动作的好坏。
clip是剪辑机制,反映经过剪辑后的改进结果,防止进步过快或退步过多,保待稳定的训练过程。 选择最小值: 1)基于新策略直接计算出来的值,2)经过剪辑后的值,保持训练的稳定性。 优化过程相对直接。不需要训练一个单独的奖励模型。直接利用人类偏好排序数据(概率比)来构建目标函数并优化策略; 目标:最大化用户偏好数据的生成概率,同时减少用户非偏好数据的生成概率; 无需明确的奖励模型,更多依赖于用户提供的偏好排序或比较数据,不需要同环境进行交互,适用于需要从静态数据(如用户的偏好反馈)中学习的任务 ,并且高度依赖用户反馈的数据质量;
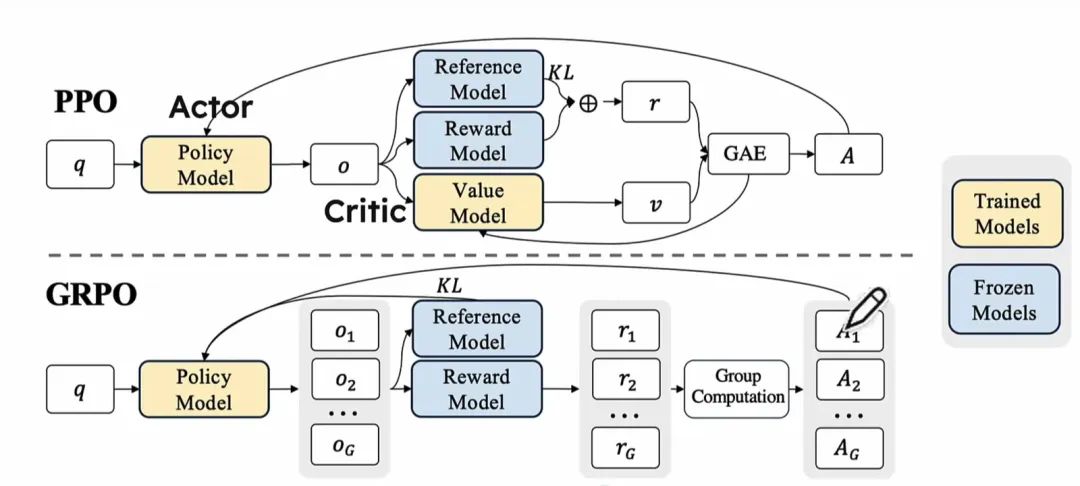

强化学习 RM(Reward Model)奖励模型的优化思路在传统的强化学习RL框架中,智能体通过与环境的交互来学习,以最大化累积奖励。但这种方法有时会面临奖励设计困难和学习效率低下的问题。为了解决这些难题,RLHF(Reinforcement Learning from Human Feedback)引入人类作为奖励信号的来源。人类反馈可以采取多种形式,包括直接的奖励信号、排名反馈、偏好比较等。 LLM as a judge:判别式的RM的准确率不足,可以用于事实性,输出风格等的判定; Generative RM:先CoT自然语言推断的,再给出奖励信号,Let's verfify step by step ; Critic Model:随着大模型的不断迭代,其输出的内容越来越准确,错误也变得更加隐蔽,就算是专业的AI训练师也很难察觉那些错误所在,open ai训练了CriticGPT这种谈论家模型,用于加强RLHF,但注意用model去建模reward,可能会因为过度对齐人类的偏好而引入bias; Outcome-based Reward Model(ORM)到Process-based Reward Model(PRM)向着模型能生成正确的推理能力的方式去优化
注意reward model可能会被hacking的问题,可以将不同的reward model混在一起训练, 让模型训多轮后也比较难找到RM的漏洞。 推理阶段(Test-time computation)的优化思路: 快思考 -> 慢思考 

通过控制模型在生成文本时自动生成推理步骤(即理由或rationales),从而提高模型的预测能力和推理性能; 在训练阶段,先基于前序token停下,进行think阶段,产出从多个thought,选择某一个thought加上前序token,进行预测下一个token,然后经过奖励模型的评判,进行反馈学习; 在推理阶段,利用think及talk对应的prompt来引导进入慢思考,在think结束后,再进行talk;

SFT->示范给模型怎么样做是对的 RL->在环境中不断的试错,累积奖励,理论上RL能榨干模型,能突破人类的上限,但reward要能写好 SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training RL 在泛化方面的优势:RL,特别是在基于结果的奖励下进行训练时,能够在基于规则的文本和视觉变体中实现泛化。这表明强化学习在处理不同情境和变化时具有更强的适应能力。强化学习通过与环境的交互不断调整策略,从而能够学习到更通用的知识和行为模式。 SFT 在记忆方面的倾向:SFT 则倾向于记忆训练数据,在分布外的场景中难以很好地泛化。这是因为监督微调主要是通过最小化预测与真实标签之间的误差来调整模型参数,容易使模型过度拟合训练数据。
SFT 对 RL 训练的重要性:尽管 RL 在泛化方面表现出色,但文章指出 SFT 对于有效的 RL 训练仍然至关重要。SFT 能够稳定模型的输出格式,为后续的 RL 训练奠定基础。没有经过 SFT 的模型可能在输出格式上不稳定,导致 RL 训练难以收敛或效果不佳。 DeepSeek-R1 

对于test-time阶段的处理,提及对于RPM及MCTS等手段,未被证实有效果; R1-ZERO仅使用RL,未使用SFT; Reward Model未使用RPM等相对复杂的模型,而是仅使用的了rule-based的RM; 强化学习算法使用的自家的GPPO,相对于PPO等,更加的简单,也更考验RM的设计能力;
给后续的推理模型后训练很多启发,仅RL也可以得到非常好的推理效果。 | 









