|
源码地址:https://github.com/NanoNets/docext[1] 概述docext 是一个由视觉语言模型(vlm)提供支持的全面的本地文档智能工具包。vlm 使用的是基于 Qwen2.5VL-3B 的模型,应该是在此模型基础上进行的微调。 它提供了三个核心功能: 1.pdf/image 转 markdown:将文档转换为具有智能内容识别的结构化标记,包括 LaTeX 方程、签名、水印、表和语义标记。 2.文档信息提取:从发票、护照和其他文档类型等文档中无 ocr 地提取结构化信息(字段、表等),并进行置信度评分。 3.智能文档处理排行榜(https://idp-leaderboard.org/):一个全面的基准测试平台,跟踪和评估视觉语言模型在OCR、关键信息提取(Key Information Extraction, KIE)、文档分类、表提取和其他智能文档处理任务中的性能。 核心特点文档转换(1) latex 公式识别,行内和块的公式使用 latex 表示 输入:  官方案例部分输出结果如下:  (2) 智能图片描述,对于所有图片,使用去替代原来图片中的内容; 输入:  官方案例部分输出结果如下:  (3)签名/水印/页码的检测,检测和标记文档中的签名、水印和页码,并分别放入到、、<page_number></page_number>中; 输入: 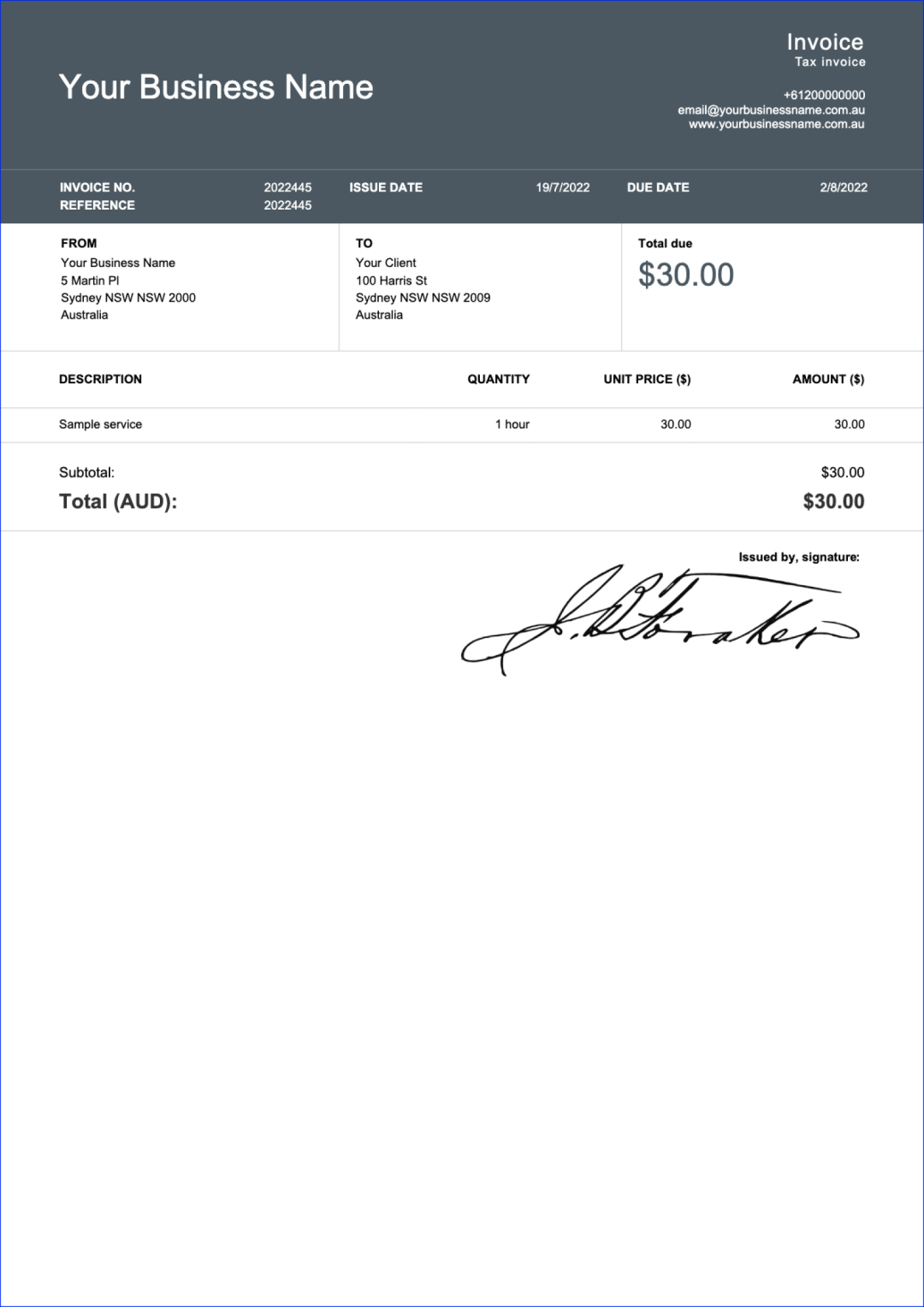 官方案例部分输出结果如下:  输入: 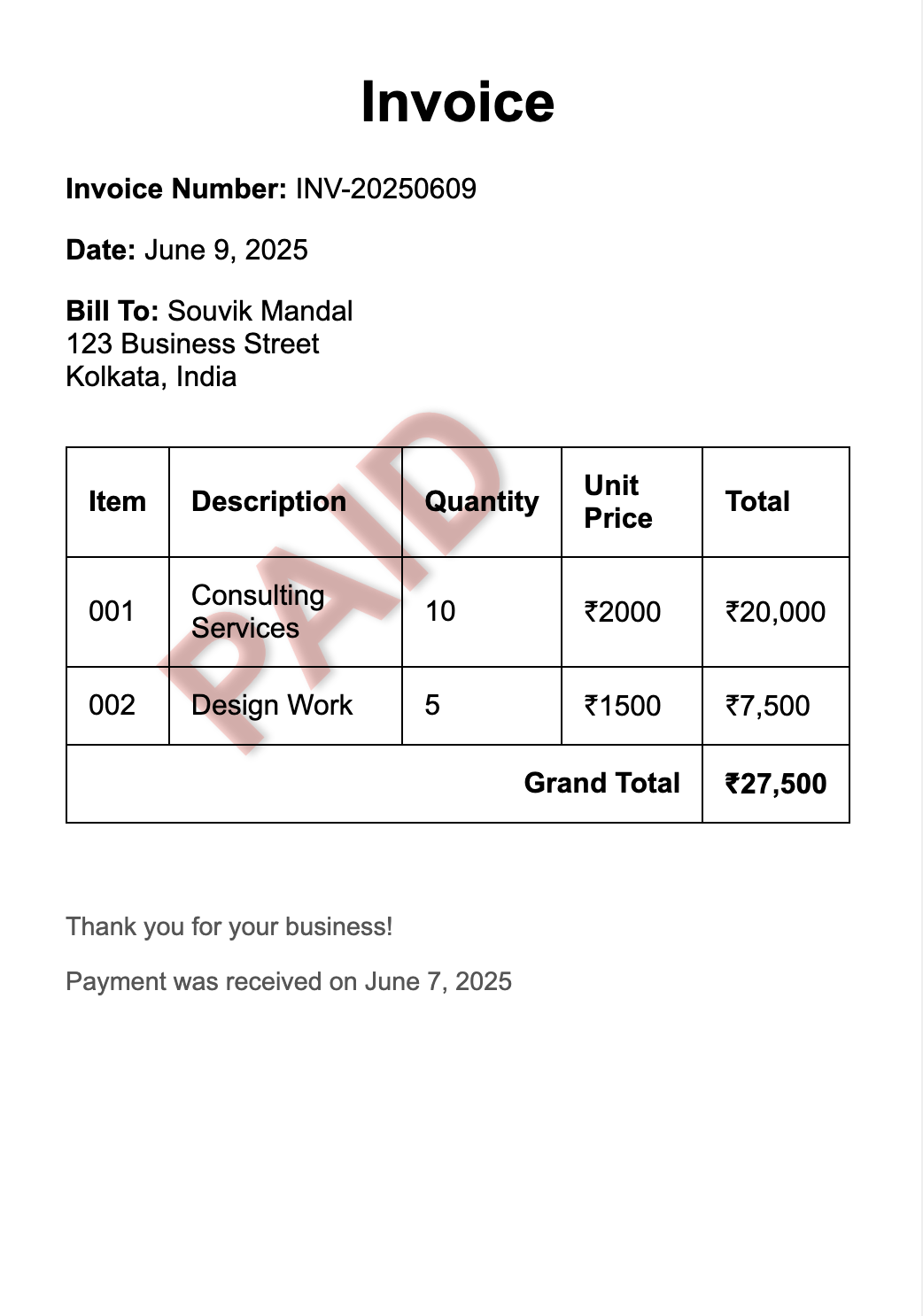 官方案例部分输出结果如下 :  (4) 复选框和单选按钮:将表单复选框和单选按钮转换为标准化的 Unicode 符号(☐, ☑, ☒) 输入: 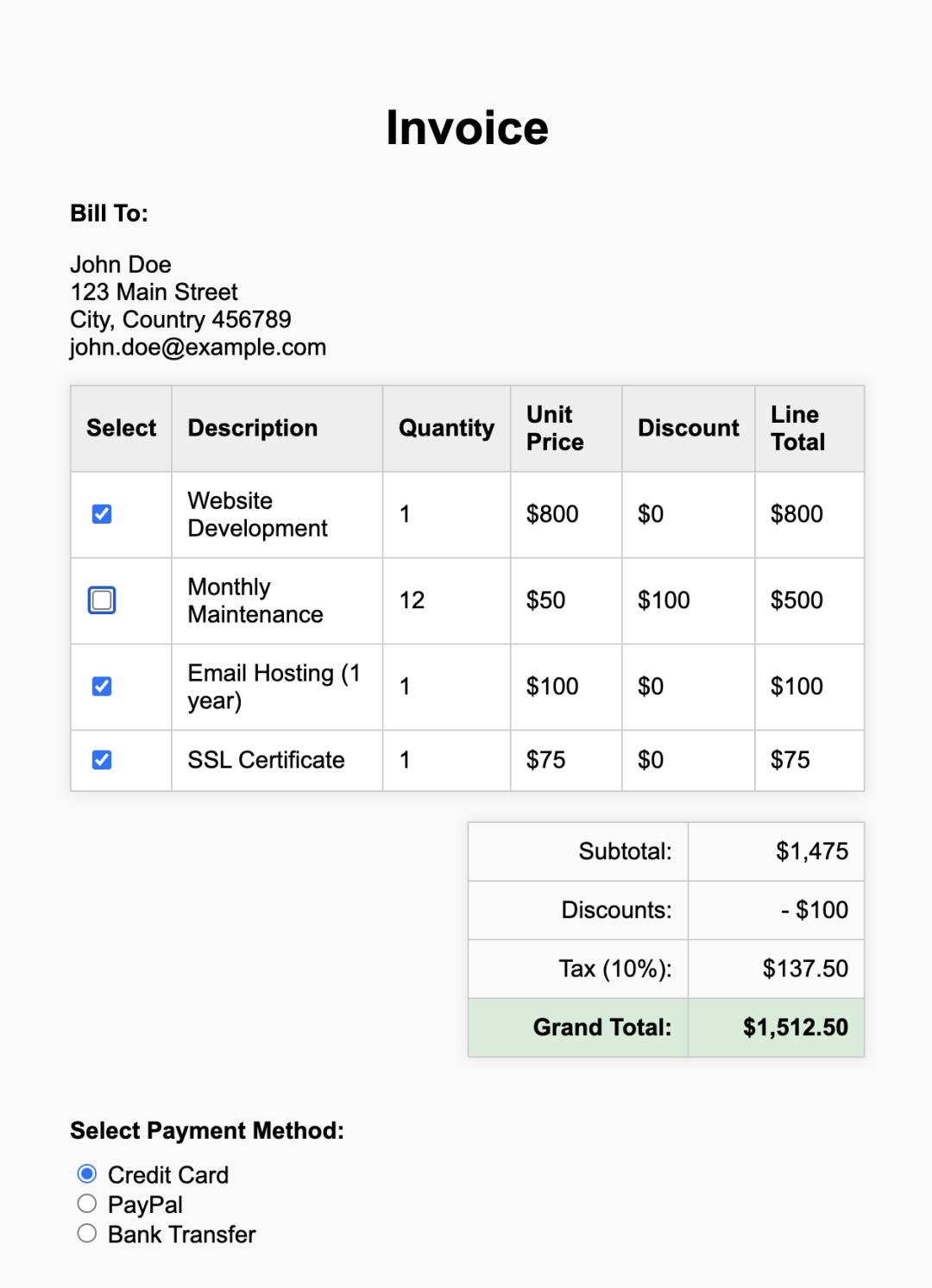 官方案例部分结果如下: 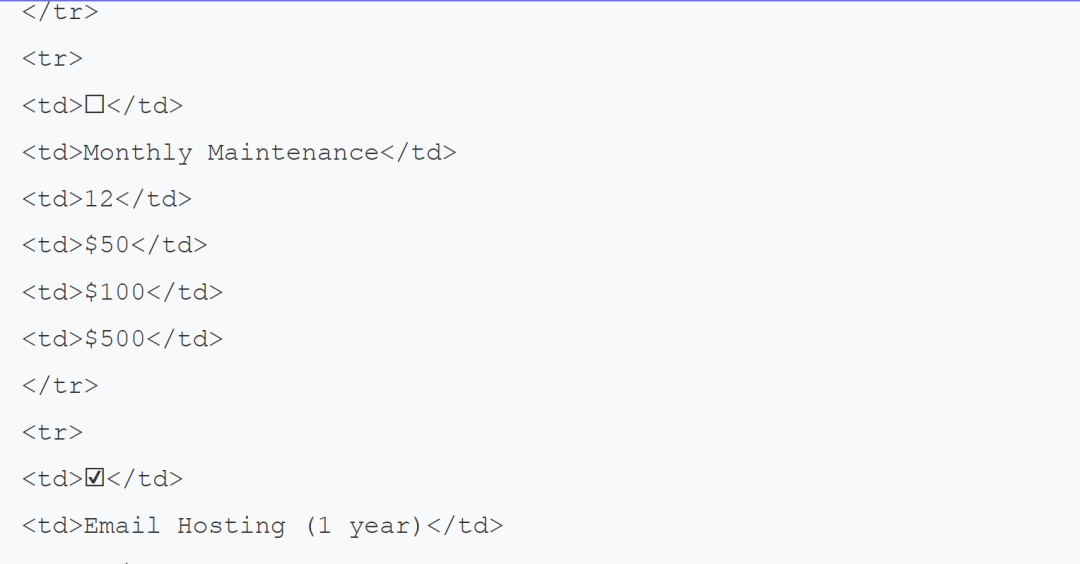 (5) 表格检测:将复杂的表格转换成 html 的表格表示 输入: 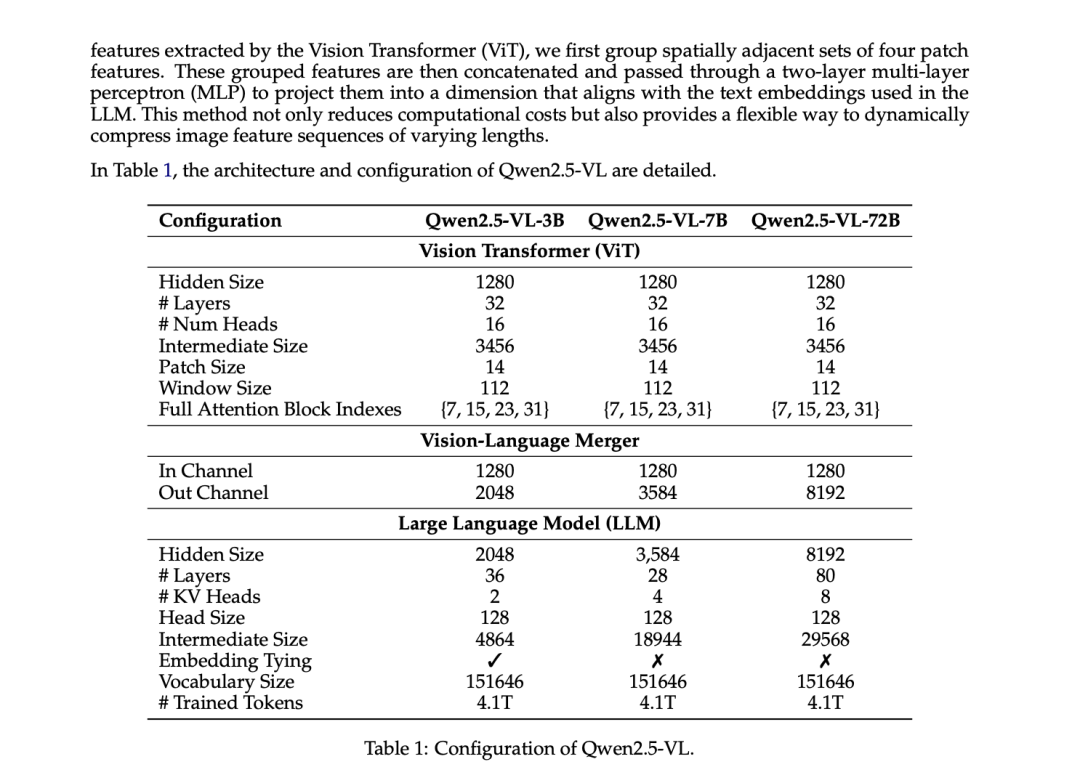 官方案例部分结果如下:  智能文档处理排行榜该基准评估七个关键文档智能挑战的性能; 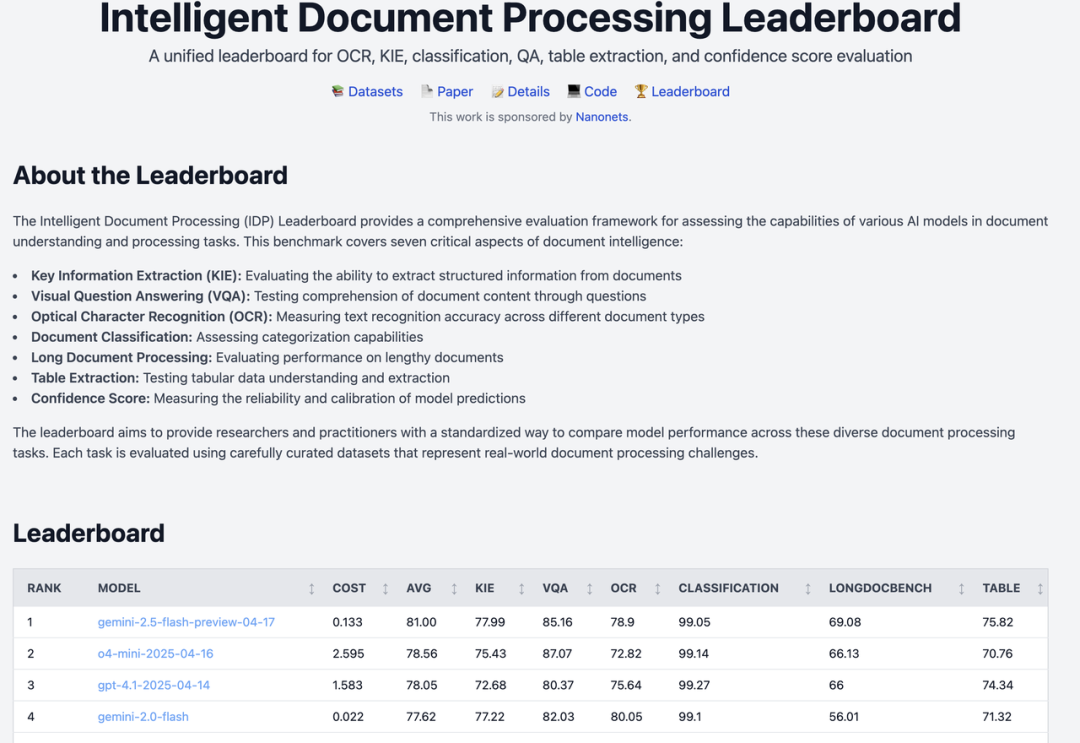 (1) 关键信息提取(KIE):从非结构化文档文本中提取结构化字段。 (2) 视觉问答(VQA):通过问答来评估对文档内容的理解。 (3) 光学字符识别(OCR):测量识别印刷和手写文本的准确性。 (4) 文档分类:评估模型对各种文档类型进行分类的准确性。 (5) 长文档处理:测试模型对冗长的、上下文丰富的文档的推理。 (6) 表提取:从复杂的表格格式中提取基准结构化数据。 (7) 可信度评分校准:评估模型预测的可靠性和置信度。 补充工具提到可以输出可信度评分,从源码来看主要是将用户的输入以及大模型的输出结果+打分的 prompt 让大模型对用户的输入和大模型的输出结果打分。 | 









