|
本期主要是为后面深入大模型微调的研究进行开篇,需要理清楚模型蒸馏、检索增强、模型微调的基本概念和区别 蒸馏:适合快速部署、资源受限的场景 RAG(检索增强):适合需要外部信息增强、实时更新的应用 微调:适合领域专用、高精度需求的场景 蒸馏(Knowledge Distillation)老师讲技能传授给学生,继往圣之绝学 概念:将一个大而复杂的"老师"(即一个大模型)的知识,提取并简化成一个"小而轻便的学生"来执行任务。通过这种方式,虽然"学生"模型比"老师"小,但它仍然能够保留老师大部分的的能力。 | | 优点 | 快速执行任务,适合资源有限的场景(如移动设备、低功耗设备)减少计算开销,需要的计算和存储资源少,适合商业化产品的快速响应和低成本要求 通过蒸馏,依然能保留大模型的一部分知识,模型的性能基本可以得到保证 | 缺点 | 虽然蒸馏模型能够保留大部分知识,但会丢失一些细节,尤其是在复杂任务上的表现可能逊色于原始大模型。 为了蒸馏出高效的小模型,通常需要大量标注数据,且训练过程较为复杂。 | 适用条件 | 比如手机、物联网设备 当需要迅速推出一个市场化的产品时,蒸馏可以帮助在保证合理精度的前提下,快速减小模型的体积 | 典型案例 | DeepSeek-R1模型 百度的Ernie轻量化模型 华为的MindSpore
|
检索增强生成(RAG)老师去找参考资料,虽然我不懂,但我可以帮你找一下 概念:RAG不仅仅依赖模型的内部知识,还通过外部的检索系统统(如数据库、文档或网络)来增强生成的内容。它就像是一个"知识更加全面、查阅资料更高效的学生"。 | | 优点 | 能够在生成答案时,利用外部数据库或文档,确保模型提供的信息更准确、更有针对性。 模型可以通过检索最新的资料来增强回答,适应快速变化的环境。 当数据更新或领域知识不断变化时,RAG能帮助模型获取最新信息,而不需要重新训练整个模型 | 缺点 | 如果外部数据源的质量不高或无法获取,模型的输出质量会受到影响。 每次生成回答时需要进行检索,可能导致延迟增加,尤其是在大规模的数据库检索时。 | 适用条件 | 如果模型应用场景需要实时获取最新信息,比如金融分析、新闻推荐、医疗诊断等,RAG是一个很好的选择。 需要结合多种有针对性来源的信息来生成答案时,RAG能够提供更具综合性的解决方案。 | 典型案例 | |
微调(Fine-Tuning)让学生精进技能,闻道有先后,术业有专攻, 青出于蓝而胜于蓝 概念:它是在一个已经学习过大量基础知识的"学生"上,通过专项训练,让其在某些特定任务上表现得更好。可以看作是对原始模型进行定制,使其更适应具体任务。 | | 优点 | 通过微调,可以让模型在某个特定领域(如法律文书分析、医学影像识别、写公司的代码、回答特定问题)上表现得更优秀。 只需要少量的训练数据,就能使模型快速适应新的领域或任务。 不需要从头训练模型,节省了大量的计算资源和时间。 | 缺点 | 如果微调数据量不足,容易导致模型在特定任务上过拟合,影响泛化能力。 微调仍然需要领域内的标注数据,尤其是在一些新领域或小众领域。 | 适用条件 | 当模型已经具备一定基础的知识(例如通用语言模型),但需要在特定领域(如法律、医疗)提高性能时,微调是最有效的策略。 微调对于特定任务的表现提升非常显著,但如果任务本身需要极大的多样性或动态调整,可能需要结合其他方法。 | 典型案例 | 字节跳动的飞书智能客服 华为云的ModelArts 腾讯云AI开放平台 写我们公司的SQL代码
|
选型参考 | | 蒸馏 | 如果目标是快速推出产品,且应用场景对模型体积和响应速度有严格要求(例如移动端应用、边缘计算设备等),那么采用蒸馏可能是最优选择。 通过蒸馏,可以减小模型的体积,加快推向市场的速度,同时保证一定的精度。 | RAG | 如果产品需要处理的是大量不确定、动态的信息,并且希望保持生成结果的准确性和时效性(例如智能客服、金融咨询等),那么RAG将会非常适用。 它能够实时获取外部信息并结合生成高质量的答案,适合数据流动快速、知识更新频繁的场景。 | 微调 | 如果已经拥有一个基础模型,且希望让其在某个特定领域(如医疗、法律、写SQL等)表现更好,能够提高精准度和用户体验,那么微调是最佳选择。 通过微调,模型能够适应特定领域的需求,提高商业化应用中的性能和可用性。 |
微调模型LoRA极简入门论文原文:https://arxiv.org/abs/2106.0968 LoRA是什么LORA (Low-Rank Adaptation) 微调是一种针对大规模预训练模型的优化技术,用于在较少计算资源和数据的情况下,对这些模型进行有效微调。 LORA通过引入低秩矩阵来减少模型参数的更新量,进而显著降低训练的计算开销,同时保持微调的性能。由于LLM参数量巨大,直接微调耗费大量资源,LORA的做法是冻结模型的绝大部分参数,只更新很小一部分参数。这就像修车时不需要重造整辆车,而是只修理一些特定的部件。 矩阵的秩是指矩阵中线性无关行或列的最大数量,低秩矩阵表示矩阵的秩较低。 
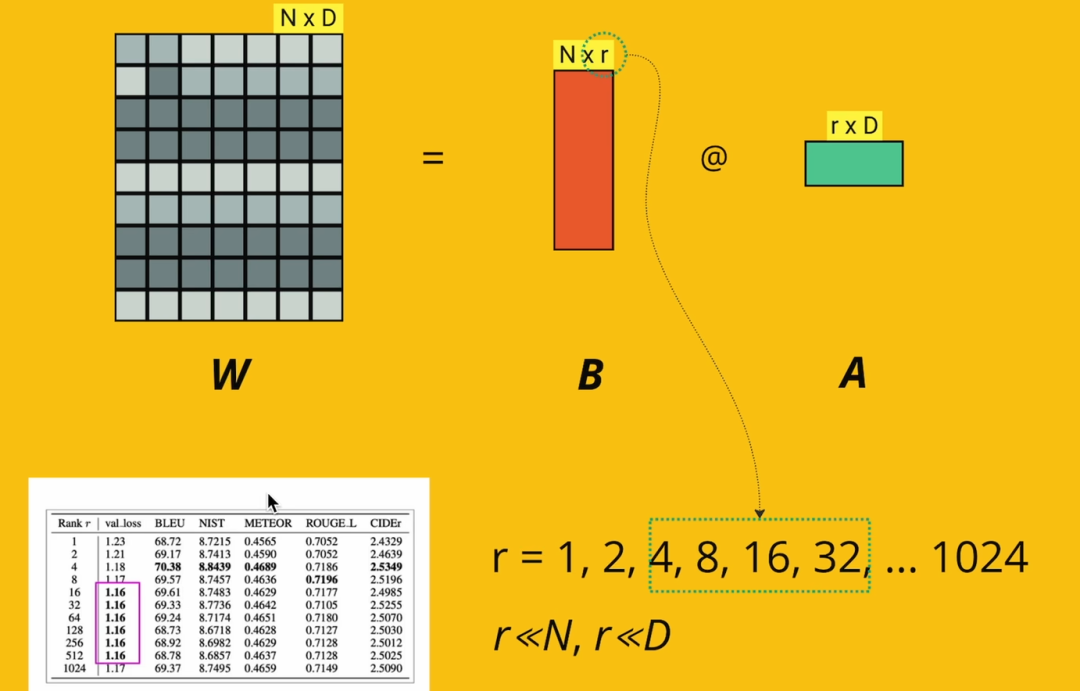


这里的alpha/r可以看成是学习率; 全参数训练和LoRA的对比 
在每个层里头应用LoRA, 从而极大减小参数量 
这里是其中一个层的示例 
QLoRA的极简入门 
LoRa的使用小技巧进行LoRA高效的模型微调,重点是保持参数尺寸最小化。 使用PEFT库来实现LORA,避免复杂的编码需求。 将LORA适应扩展到所有线性层,增强整体模型的能力。 保持偏置层归一化可训练,因为它们对模型的适应性至关重要,并且不需要低秩适应。 应用量化低秩适应 (QLORA)以节省GPU显存并训练模型,从而能够训练更大的模型。
| 









