ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;letter-spacing: 0.5px;">ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;">五年沉寂,一朝破壁。ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;letter-spacing: 0.5px;">就在凌晨,OpenAI以GPT-OSS的姿态重返开源战场,一口气开源两个权重语言模型:ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;">gpt-oss-120b和ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;">gpt-oss-20b。ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;padding: 0.4em 0px 0.3em 0.8em;">ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;">关键信息速读ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;" class="list-paddingleft-1">ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;display: block;margin: 0.8em 0px;padding-left: 2em;">•ingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;">两大模型:发布gpt-oss-120b与gpt-oss-20b,采用Apache 2.0协议,完全开放商用。•性能越级:120B版本性能直逼o4-mini,20B版本媲美o3-mini,在多个基准测试中展现SOTA(State-of-the-Art)实力。•极致效率:采用MoE架构与原生4位量化(MXFP4),120B模型可在单张80G H100上运行,20B模型仅需16GB显存,消费级硬件即可驾驭。•Agent友好:原生支持工具调用、代码执行与结构化输出,为构建强大的AI智能体铺平道路。•生态完备:发布即获Hugging Face、英伟达、微软、Ollama等业界巨头全面支持,部署和微调体验无缝衔接。五年磨一剑,OpenAI重拾“开放”初心?距离GPT-2发布已过去五年,当行业几乎将“OpenAI”视为“ClosedAI”的同义词时,它用gpt-oss给出了最强有力的回应。这不仅是自ChatGPT时代以来OpenAI首次开源语言模型,更是一次颠覆性的市场行动。 gpt-oss系列包含两个版本:120B模型面向生产级高推理任务,20B模型则专为低延迟、本地化和边缘计算场景设计。 性能“奇点”:MoE架构与原生量化GPT-OSS的惊人之处在于,它在保持强大性能的同时,将硬件门槛降至了前所未有的低点。这背后的核心技术,是混合专家(MoE)架构与原生4位(MXFP4)量化方案的精妙结合。 不同于传统模型需要调动全部参数,MoE架构仅激活处理当前任务所需的一小部分“专家”参数。gpt-oss-120b总参数高达1170亿,但每个token仅激活51亿;20B模型则从210亿参数中激活36亿。这种稀疏激活模式是效率的源泉。 更具革命性的是原生量化。OpenAI并非在训练后进行精度压缩,而是在训练阶段就让模型适应低精度环境。这种“出厂即量化”的设计,使得模型体积大幅缩小,性能损失却微乎其微。 最终,一个性能堪比o4-mini的庞然大物,得以在单张80GB显卡上安家;而一个超越众多开源模型的20B版本,仅需16GB显存即可流畅运行。这让高端AI技术真正飞入了寻常开发者的工作站。 SOTA级表现与客观短板在多个核心基准测试中,GPT-OSS的表现堪称惊艳。无论是在编程竞赛(Codeforces)、通用问答(MMLU),还是在专业领域的健康咨询(HealthBench)和数学竞赛(AIME)上,gpt-oss-120b都展现出与o4-mini分庭抗礼甚至超越的实力。 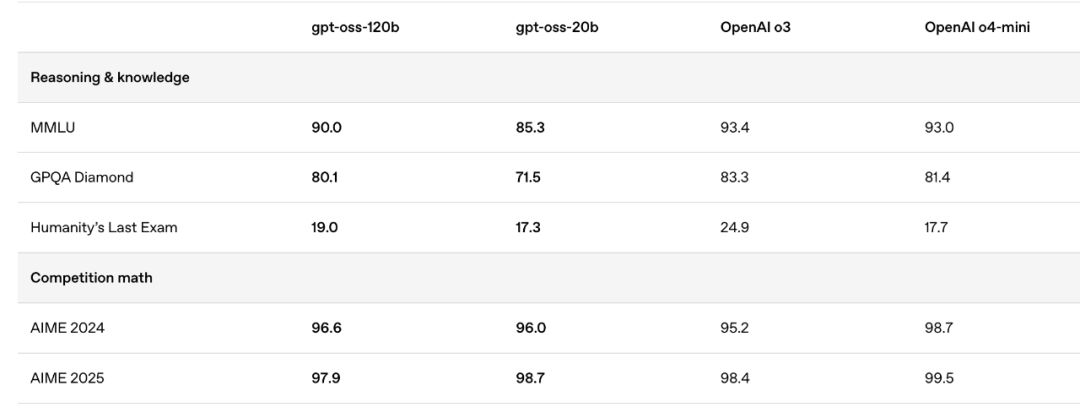
在同等规模的开源模型对比中,GPT-OSS几乎呈现出碾压性的优势,重新确立了开源SOTA的新标杆。这无疑给所有致力于开源大模型的团队带来了巨大的竞争压力。 然而,作为一款主打推理的纯文本模型,GPT-OSS并非完美。根据社区的初步测试,它在处理某些创意性或复杂代码生成任务时,表现不如顶级闭源模型。同时,其幻觉率也显著高于o3和o4-mini,这是小型化和推理优化过程中难以避免的权衡。 开源是手段,生态是目的OpenAI此刻选择开源,绝非一时兴起。在以DeepSeek为代表的全球开源力量迅速崛起的背景下,继续固守纯闭源策略已非明智之举。通过开源性能卓越的次顶级模型,OpenAI意在重新夺回开发者心智,巩固其技术生态的护城河。 gpt-oss全面兼容OpenAI的API规范,并原生支持函数调用与代码执行等Agent核心能力。这意味着开发者可以在本地低成本开发、测试和迭代AI应用,成熟后再无缝迁移至OpenAI的付费API,从而形成一个强大的商业闭环。 开放,是为了更深远的掌控。这盘棋,OpenAI下得愈加清晰。 GPT-OSS的发布,与其说是OpenAI的一次慷慨馈赠,不如说是开源力量倒逼下的必然结果。 它为全球开发者拉低了准入门槛,也为整个行业抬高了竞争基线,一个更开放、更激烈的AI新纪元,已然开启。 |










