|
在传统的 RAG 流程中,我们通常会等待整个生成过程完成后,再将完整的内容返回给用户。但对于许多应用场景,尤其是需要实时交互的聊天机器人或问答系统,这种等待时间可能会导致糟糕的用户体验。流式输出则很好地解决了这个问题,它允许语言模型在生成内容的同时,将每个词或每个 Token 实时地返回给用户,就像我们看到别人打字一样。 一、为什么需要流式输出? 提升用户体验:用户无需漫长等待,可以立即看到内容逐字逐句地生成,大大减少了等待的焦虑感,使得交互更加流畅自然。 实时性:对于需要快速响应的应用至关重要,例如客服系统或实时聊天。 内存优化:完整生成大段文本会占用较多内存,而流式输出可以边生成边释放,有助于降低内存消耗。
二、 FastAPI 中实现流式输出 在 FastAPI 中实现流式输出,主要有两种常见方式: 1、StreamingResponse 直接流式输出 这是最基础、通用的方案,适合文件传输、日志、模拟分段输出等用途。 fromfastapiimportFastAPIfromfastapi.responsesimportStreamingResponseimportasyncio
app = FastAPI()
asyncdeffake_stream(): foriinrange(5): yieldf"chunk{i}\n".encode("utf‑8") awaitasyncio.sleep(1)
@app.get("/stream")asyncdefstream(): returnStreamingResponse(fake_stream(), media_type="text/plain")
在这个例子中,/stream 接口会返回一个流式响应,每秒发送一个数据块(模拟的“Chunk”),客户端在每次接收到数据时就能立即处理,避免等待所有数据传输完毕。 2、SSE 协议流式推送数据 使用 SSE(Server-Sent Events)协议流式推送数据,适合实时通知、聊天系统、前端长连接监听场景,前端通过 EventSource 或相似库消费消息。 fromfastapiimportFastAPIfromsse_starlette.sseimportEventSourceResponseimportasyncioimportjson
app = FastAPI()
asyncdefevent_generator(): foriinrange(10): yield{"event":"message","data": json.dumps(f"chunk{i}")} awaitasyncio.sleep(1)
@app.get("/sse")asyncdefsse_stream(): returnEventSourceResponse(event_generator())
响应头自动设置 Content-Type: text/event-stream 和 Cache-Control: no-cache; 前端通过 JavaScript 的 new EventSource('/sse') 可接收每条 data: 消息 ; 可用于实时推送 ChatGPT 或 LLM 模型输出等应用;
3、 OpenAI 或 LLM 接口流式输出 结合 OpenAI 的 API stream=True 参数,将大语言模型 (LLM) 的令牌逐步传回客户端,样例(简化): fromfastapiimportFastAPIfromfastapi.responsesimportStreamingResponseimportopenaiimportasyncio
app = FastAPI()
asyncdefproxy_openai(req_messages): # openai.api_key 已设定 stream = openai.ChatCompletion.create( model="gpt‑3.5‑turbo", messages=req_messages, stream=True ) asyncforchunkinstream: if"content"inchunk["choices"][0]["delta"]: yieldchunk["choices"][0]["delta"]["content"] awaitasyncio.sleep(0)
@app.post("/chat_stream")asyncdefchat_stream(req:dict): req_messages = req.get("messages", []) returnStreamingResponse(proxy_openai(req_messages), media_type="text/plain")
根据以上信息,我们初步掌握了流式输出的基本原理和方法,接下来我们来看下在开发RAG或Agent等大模型应用中,如何使用流式输出! 三、RAG实现流式输出的核心逻辑 开发RAG或Agent,一般选择 LangChain(LangGraph)或 LlamaIndex 这两种框架。我们采用LlamaIndex来实现。 1、先来看下非流式输出 LlamaIndex内置了多种ChatEngine对话引擎,这里使用CondenseQuestionChatEngine+CitationQueryEngine,这种引擎特点是可以追溯来源,定位知识库中的元数据,这特点在开发RAG为主的应用中尤为常用。调用chat_engine.achat就可以进行多轮对话的查询了。 核心的代码如下:
# 长期和缓存记忆 memory =awaitself.muxue_memory.get_session_memory(req.session_id)
# 知识库索引Index kbm_index =awaitself.muxue_vector_store.init_kbm_vector_index()
# 先构造查询引擎 citation_query_engine = CitationQueryEngine.from_args( kbm_index, similarity_top_k=3, citation_chunk_size=512)
# 再构造对话引擎 chat_engine = CondenseQuestionChatEngine.from_defaults( query_engine=citation_query_engine, condense_question_prompt=custom_prompt, memory=memory, verbose=True, )
resp =await chat_engine.achat(req.query) #多轮对话
# 溯源:知识库元数据 sources = [ {"id":getattr(n.node,"node_id",None),"text": n.node.get_content()[:200],"metadata":getattr(n.node,"metadata", {}), }forninresp.source_nodes ]
# 返回的数据封装 result=ChatQueryResponse(answer=resp.response,sources=sources)
使用memory组件,可以将历史信息保存到数据库和缓存中;memory组件的使用方法点击这里! 知识库的索引kbm_index,需事先将文档Embedding到知识库,然后创建索引Index; 查询引擎使用CitationQueryEngine,该引擎的特点是可溯源; 对话引擎使用CondenseQuestionChatEngine,初始化时需传入查询引擎、提示词、memory组件等,想看详细日志可以verbose=True; 多轮对话方法是chat_engine.achat; AI回答的内容,需要溯源知识库元数据 sources;
从代码量来看真实的RAG落地,其工程化的确需 Python功底和对LlamaIndex的各个组件的掌握的!流式输出会更加复杂;在开发RAG中,还会碰到其他的需求,我们一般在核心代码外部还需要包一层Workflow,扩展性和灵活性瞬间上升一个级别! 2、流式输出的核心代码 2.1 LlamaIndex的多轮对话底层方法 @stepasyncdefchat_step(self,ctx: Context, ev: ChatEvent) -> StopEvent: req=ev.chat_reqprint(f"chat_step.chat_req={ev.chat_req}")
# 记忆组件 memory =awaitself.muxue_memory.get_session_memory(req.session_id)
# 知识库索引 kbm_index =awaitself.muxue_vector_store.init_kbm_vector_index()
# 先构造查询引擎,流式输出=True citation_query_engine = CitationQueryEngine.from_args( kbm_index, similarity_top_k=3, citation_chunk_size=512, streaming=True,)
# 再构造对话引擎 chat_engine = CondenseQuestionChatEngine.from_defaults( query_engine=citation_query_engine, condense_question_prompt=custom_prompt, memory=memory, verbose=True,)
#多轮对话,流式输出 resp :StreamingAgentChatResponse =await chat_engine.astream_chat(req.query)
asyncfortokeninresp.async_response_gen(): ctx.write_event_to_stream(StreamEvent(delta=token))
sources = [ {"id":getattr(n.node,"node_id",None),"text": n.node.get_content()[:200],"metadata":getattr(n.node,"metadata", {}), }forninresp.sources[0].raw_output.source_nodes ]
result=ChatQueryResponse(answer=resp.response,sources=sources)
returnStopEvent(result=result)
大部分逻辑与上面的一致,只有以下几点需要调整! 构造查询引擎,流式输出 streaming=True ; 多轮对话流式输出 chat_engine.astream_chat(req.query) ; 大模型返回的一个一个数据块方法: async for token in resp.async_response_gen(), 因为这里是使用workflow,所以需要将其保存到上下文的流里write_event_to_stream; 若不在workflow里,则直接使用 yield token; 溯源的Source数据可以放在最终的返回结果里;
2.2 Service层写法 asyncdefchat_stream(self, req: ChatQueryRequest)->ChatQueryResponse:""" 对话服务,返回固定的回答和来源,流式输出 """ handler = self.chat_agent_wf.run(chat_req=req, module="test_module")asyncforchunkin handler.stream_events():ifisinstance(chunk, StreamEvent):#print(f"chat_service.chat-chunk: {chunk.delta}")yieldchunk.delta
final_result :ChatQueryResponse =awaithandler# print("最终的完整的答案:", final_result)yield final_result
之所以有services层,是为了对流数据统一管理,因为第一步中,source并没有放流里。( 也可以在第一步中将source数据放流里)
2.3 FastApi的WebApi接口层写法 @chat_router.post("/chat_stream",summary="多轮对话问答", description="提交用户问题,返回AI回答和溯源信息。流式输出。")@injectasyncdefchat_stream(req: ChatQueryRequest,request: Request, chat_service: ChatService = Depends(Provide[Container.chat_service]) )-> EventSourceResponse:
asyncdefevent_stream():asyncforchunkin chat_service.chat_stream(req):ifisinstance(chunk, ChatQueryResponse):yield{"event":"source","data": chunk.sources}else:yield{"event":"message","data": chunk}
returnEventSourceResponse( event_stream(), media_type="text/event-stream", headers={ "Cache-Control":"no-cache", "Connection":"keep-alive", } )
效果如下: 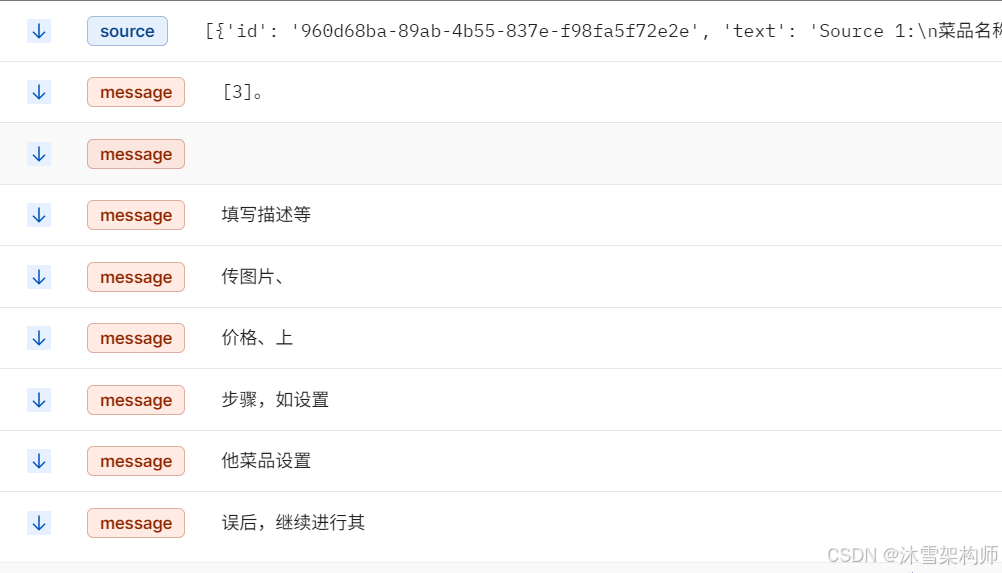
2.4 前端停止后接口的处理 FastAPI 可以通过 直接监听请求的 disconnect 事件来感知客户端断开连接,进而停止数据发送并释放资源。webapi层完整的代码如下: # 活跃连接 Task ID 集合active_tasks:Set[int] =set()
@chat_router.post("/chat_stream",summary="多轮对话问答,流式输出", description="提交用户问题,返回AI回答和溯源信息。流式输出。")@injectasyncdefchat_stream(req: ChatQueryRequest,request: Request, chat_service: ChatService = Depends(Provide[Container.chat_service]) )-> EventSourceResponse:
task = asyncio.current_task() task_id =id(task)iftaskelseNone iftask_id: active_tasks.add(task_id) logger.info(f"新连接建立 (task_id={task_id}),当前活跃连接数:{len(active_tasks)}")
asyncdefevent_stream(): try: asyncforchunkin chat_service.chat_stream(req): # 检查客户端是否断开 ifawaitrequest.is_disconnected(): logger.info(f"客户端断开 (task_id={task_id})") break
ifisinstance(chunk, ChatQueryResponse): yield{"event":"source","data": chunk.sources} else: yield{"event":"message","data": chunk} finally: # 清理任务 iftask_idandtask_idinactive_tasks: active_tasks.remove(task_id) logger.info(f"连接关闭 (task_id={task_id}),剩余活跃连接数:{len(active_tasks)}")
returnEventSourceResponse( event_stream(), media_type="text/event-stream", headers={ "Cache-Control":"no-cache", "Connection":"keep-alive", } )
| 









