想象一下,你家里的机器人助手,每天清晨都能看到你。第一天,它看到你喝咖啡;第二天,它又看到你喝咖啡;第三天……当你问它“我早上喜欢喝什么?”时,它却一脸茫然。这就是当前大多数AI Agent的现状——它们拥有惊人的瞬时理解能力,却患有严重的“金鱼记忆症”。
它们的“世界”被一个名为“上下文窗口”(Context Window)的狭窄囚笼所限制。每一次交互都是一次“重启”,它们无法将今天的“爱丽丝”与昨天的“爱丽丝”联系起来,更无法从“每天都喝咖啡”这个重复的行为中,提炼出“爱丽丝喜欢喝咖啡”这一条宝贵的知识。这种无法积累经验、形成长期记忆的缺陷,是阻碍AI从一个“工具”进化为一个真正“伙伴”的根本瓶颈。
- 撰写“案件快照”(Episodic Memory):它将每30秒的见闻,写成一张张详细的快照卡片。“8:00 AM,目标人物
爱丽丝<face_1>拿起咖啡杯,说‘早上没这个可不行’。” - 提炼“人物档案”(Semantic Memory):更重要的是,它会从这些快照中提炼出更高层次的情报,并更新到软木板上的人物档案中。“从多日观察来看,
爱丽丝有喝早咖啡的习惯。”;“通过声音<voice_2>和面孔<face_1>的比对,确认为同一人,进行档案合并。” 案件分析师(Control Workflow):当接到一个指令(“给爱丽丝准备她最喜欢的早餐饮品”)时,这位分析师登场了。他不会大海捞针般地翻阅所有录像带,而是:
- 在软木板上进行“线索串联”:他首先在软木板上搜索关键词“爱丽丝”、“早上”、“饮品”。
- 发现知识缺口并二次搜索:他找到了“喝早咖啡”的记录,但“最喜欢”这个词无法确认。于是他发起第二轮、更精确的搜索:“爱丽丝”对“咖啡”发表过什么评论?
- 形成完整推理链并行动:他找到了那句“早上没这个可不行”,推理出咖啡对她至关重要。最终,他得出结论,并下达指令:“准备一杯咖啡”。
这个双流程、双记忆的系统,其革命性在于,它让AI的记忆系统从一个被动查询的“数据库”,进化成了一个主动构建、持续生长的“知识图谱”。
第三部分:架构解剖:一个记忆与控制的优雅双循环
M3-Agent的架构,如论文图1所示,是一个优雅的双循环系统,由记忆和控制两大核心支柱构成。
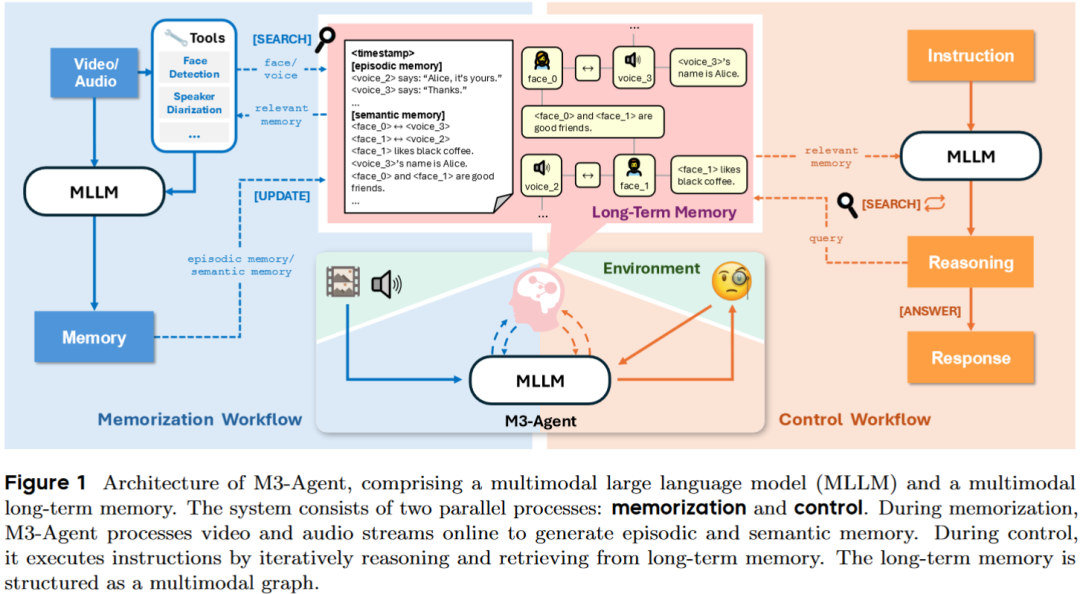
1. 记忆的基石:实体为心的多模态图谱
M3-Agent的长期记忆,并非简单的文本存储,而是一个以实体(Entity)为节点、以关系(Relationship)为边的多模态知识图谱。每个节点都拥有如论文表3所示的丰富属性:
| | |
|---|
id | Unique identifier for the node | |
type | Modality type (text, image, audio) | |
content | Raw content (text, base64 image/audio) | |
embedding | Vector representation for retrieval | |
weight | | |
extra_data | Metadata such as timestamps | |
这个图谱的核心在于实体的一致性。通过内置的人脸识别和声纹识别工具,M3-Agent能将不同时间、不同场景下出现的同一个人的面孔(<face_1>)和声音(<voice_2>)关联起来,并在语义记忆中生成一条关键的边:Equivalence: <face_1>, <voice_2>。这解决了困扰多模态Agent最核心的难题:如何知道视频里的“他”和音频里的“他”是同一个人?
2. 控制的核心:迭代式推理策略模型
与负责“记录”的记忆模型(基于Qwen2.5-Omni)不同,负责“思考”的控制模型是一个纯语言模型(基于Qwen3),它扮演着策略模型的角色。它的任务是:给定一个问题和从记忆中检索到的信息,决定下一步是继续搜索([Search])还是直接回答([Answer])。这种迭代式推理的能力,是通过强化学习训练得来的,使其远比传统的单轮RAG更为强大和灵活。
第四部分:技术细节与工作流:RL如何赋能“思考”?
M3-Agent的“控制”工作流,是其另一个核心创新。它摒弃了传统RAG(检索增强生成)的一问一答模式,引入了强化学习(RL)来训练一个能够进行多轮迭代式推理的策略模型。
如算法1所示,当接到一个问题时,Agent会执行最多轮的“思考-行动”循环:
- 第一轮:模型接收问题,发现信息不足,决定输出一个动作和内容:
Action: [Search], Content: "爱丽丝的身份ID是什么?"。 - 记忆检索:系统执行搜索,从记忆图谱中返回相关信息:“
CLIP_4: 爱丽丝的名字是<character_3>”。 - 第二轮:模型将返回的记忆作为新的上下文,再次进行推理。它发现知道了ID但还不知道答案,于是决定进行下一步搜索:
Action: [Search], Content: "<character_3>早上喜欢喝什么?"。 - 循环往复:这个过程不断重复,直到模型认为上下文中已经包含了足够的信息来回答最初的问题。
- 最终回答:在最后一轮,模型被强制要求输出
Action: [Answer],并给出最终答案。
为了让模型学会如何进行高效的、有逻辑的连续搜索,作者采用了DAPO(Direct Advantage Policy Optimization),一种先进的强化学习算法。其优化目标可以被概括为:
人话解读:这个公式的核心思想是:对于一个完整的、由多轮搜索组成的推理轨迹,我们会先根据最终答案的正确性给予一个总奖励(答对为1,答错为0)。然后,我们将这个奖励转化为每一步行动的优势值(即,采取这一步搜索,对最终答对问题有多大“好处”)。最后,通过优化这个目标函数,模型会学会更频繁地采取那些能够导向高奖励轨迹的搜索行为,并抑制那些可能导向错误答案的无效搜索。这就是RL如何赋能M3-Agent学会“思考”的数学原理。
第五部分:试金石:专为长期记忆打造的M3-Bench
为了证明M3-Agent的卓越能力,作者们发现现有的长视频问答(LVQA)基准存在不足:它们大多关注短期的动作识别或时空定位,而缺乏对需要长期记忆积累才能回答的高级认知能力的评测。
为此,他们构建了一个全新的、极具挑战性的评测基准——M3-Bench。它包含两大部分:
- M3-Bench-robot:100个从机器人第一视角拍摄的、真实世界长视频。
- M3-Bench-web:929个来自网络的、覆盖更多样化场景的长视频。
M3-Bench的真正创新之处在于其精心设计的问题类型(如论文表1所示),它们直击长期记忆的核心能力:
- 多细节推理 (Multi-detail Reasoning):需要从视频中多个不连续的片段聚合信息(“五个商品中,哪个最贵?”)。
- 多跳推理 (Multi-hop Reasoning):需要像侦探一样,一步步追溯事件链条(“他们去了A店之后,下一站去了哪里?”)。
- 跨模态推理 (Cross-modal Reasoning):需要结合视觉(“他手里拿着红色的文件夹”)和听觉(“他说‘机密文件放这里’”),才能得出正确答案。
这个基准的建立,本身就是对该领域的一大贡献,它为评测未来更高级的AI Agent提供了一把精准的“标尺”。
第六部分:实验的雄辩:数据如何证明“记忆”的力量?
M3-Agent在M3-Bench以及另一个公开基准VideoMME-long上,与一系列强大的基线模型(包括基于Gemini-1.5-Pro和GPT-4o的Agent)进行了正面交锋。

1. 压倒性的主体胜利
如表5所示,M3-Agent在所有三个基准上都取得了最佳性能。相较于最强的基线模型(Gemini-GPT4o-Hybrid),M3-Agent的准确率在M3-Bench-robot上高出**6.7%,在M3-Bench-web上高出7.7%,在VideoMME-long上高出5.3%**。这定量地证明了其精心设计的架构和RL训练的优越性。
2. 消融研究:揭示成功的秘诀
更具洞察的是论文中的消融实验,它们揭示了M3-Agent成功的核心要素:
- 语义记忆是灵魂:如果从记忆系统中移除“语义记忆”(只保留“情景记忆”),模型的性能会发生断崖式下跌,在三个基准上分别暴跌17.1%、19.2%和13.1%。这雄辩地证明,简单的事件记录远远不够,从经验中提炼知识才是智能的关键。
- 强化学习是“点睛之笔”:如果将RL训练的控制模型,换成一个简单用提示工程(Prompting)驱动的模型,性能同样会大幅下降(在M3-Bench-robot上下降10.0%)。这证明了让Agent学会如何“思考”和“搜索”,远比给它一个好的“模板”要有效得多。
- 多轮推理不可或缺:如果限制Agent只能进行单轮推理,其性能也会显著降低。这证明了面对复杂问题时,迭代式地逼近答案的能力是至关重要的。
第七部分:即插即用的研究思路 (Plug-and-Play Research Ideas)
M3-Agent为多模态和Agent研究开辟了一片广阔的新大陆。以下是几个可以直接在其基础上展开的前沿研究方向:
- Idea: 人类的记忆并非无限。
M3-Agent的记忆图谱会随着时间无限增长,最终会面临存储和检索效率的瓶颈。可以设计一个“记忆剪辑师”模块,定期对记忆图谱进行压缩和遗忘。例如,利用LLM的总结能力,将大量相关的、琐碎的情景记忆,融合成一条更凝练的、新的语义记忆(“在过去的一个月里,爱丽丝每周一、三、五早上都喝了咖啡”),然后可以安全地“遗忘”掉那些原始的、低价值的记忆节点。这正是通往可扩展的、真正的“终身学习”Agent的关键。
- Idea: 当前的
M3-Agent是一个被动的观察者。一个更高级的智能体应该具备主动求知的能力。可以研究一种基于“信息熵”或“好奇心”的驱动机制。当Agent在构建记忆时,如果发现某个关键信息缺失(例如,知道一个人的脸,但从未听过他的声音),它可以主动发起提问:“你好,我们之前见过,但我还不知道你的名字,可以告诉我吗?”。这将把Agent从一个“记录员”提升为一个“学习者”。
- Idea: 如果一个家庭里有多个机器人助手,它们是否应该拥有各自独立的记忆,还是一个共享的“集体记忆”?可以探索分布式、多Agent的记忆图谱。挑战在于如何处理来自不同视角、可能相互矛盾的观测,以及如何设计一个高效的“记忆同步与冲突解决”协议。一个成功的集体记忆系统,将能让一组机器人协作完成极其复杂的任务(“你去楼下看看妈妈回来了没有,她昨天说今天会带草莓回来”)。
第八部分:终章 —— 不仅仅是记忆,更是世界模型的“以小见大”
M3-Agent的发布,其意义远不止于“让AI拥有了记忆”。它更深刻的启示在于,它为我们揭示了一条通往更通用、更持续的世界模型的全新路径。
传统的视频世界模型,试图在一个巨大的神经网络中,端到端地、隐式地对世界进行建模。而M3-Agent则另辟蹊径,它证明了通过一个显式的、结构化的、语言与多模态特征混合的记忆图谱,我们同样可以构建一个功能强大的世界模型。这种“以小见大”、“积少成多”的构建方式,可能更具可解释性、可扩展性,也更接近人类认知世界的真实过程。
我们正在见证AI Agent从一个执行指令的“工具人”,向一个能够与我们共同生活、共同成长、拥有共同记忆的“伙伴”演进的历史性转折点。M3-Agent所开启的,是一个关于机器认知、终身学习和人机共生的全新篇章。
第九部分:深入探索与思想碰撞 (Further Exploration & Discussion)
这篇文章的解读仅仅是一个开始。对于任何希望深入探索或将这些思想付诸实践的研究者,以下资源和问题或许能为您点亮前路。
1. 核心资源传送门 (Essential Resources)
- 论文原文 (ArXiv):https://arxiv.org/abs/2508.09736v1
- 官方代码与数据 (GitHub):https://github.com/bytedance-seed/m3-agent
- 项目主页:https://m3-agent.github.io
2. 一个值得深思的开放性问题 (A Lingering Question)
M3-Agent的记忆完全建立在其第一人称的、不完美的感知之上。人类拥有修正错误记忆、辨别信息真伪的能力,但M3-Agent如何处理“记忆污染”的问题?
例如,如果Agent错误地将爱丽丝的声音识别为了鲍勃的声音,并记录了一条错误的Equivalence关系,这个错误可能会像病毒一样,在记忆图谱中污染所有后续的推理。一个核心的思辨点是:一个拥有长期记忆的AI,是否必须配套一个同样强大的“事实核查与记忆修正”子系统?这个子系统应该如何设计?是依靠逻辑一致性自检,还是需要外部“真相源”的干预?这个问题的答案,将直接决定这类拥有长期记忆的Agent,在真实世界中的可靠性和安全性










