语言模型(LM)是一种基于自然文本预测词(Token)的机器学习方法,常见的架构包括GPT和BERT等。大语言模型通常指的是拥有亿级参数的神经网络语言模型,目前已经出现很多种能力强大的开源、闭源模型,如在下图中Zhao等人整理的大模型发展时间线中的模型。
图中,不同的分支上的模型具有不同的基础模型结构,仅有左下方的灰色分支为非Transformer模型,其余颜色的分支均为基于Transformer的模型:其中,蓝色分支为仅解码器模型(Decodr-Only),包括GPT系列模型、ChatGPT模型、LLaMA系列模型等;粉红色分支为仅编码器模型(Encoder-Only),包括Bert系列模型等;绿色分支为编码器-解码器模型(Encoder-Decoder),包括T5模型、GLM系列模型、UL2系列模型等。
图中,实心方块代表开源模型,空心方块代表闭源模型;右下角的条形图显示了各公司和机构的模型数量;纵轴上的垂直位置表示模型的发布日期。可以看出,NLP基础模型及Transformer架构的研究,对大模型的发展至关重要。
自然语言处理是计算机科学、人工智能和语言学的交叉领域,研究如何让计算机处理、理解和生成人类语言。目标是:能够实现人机交互、自动翻译、信息检索、情感分析等任务。应用领域包括搜索引擎、社交媒体监测、智能客服、新闻生成等。 ### 模型发展阶段
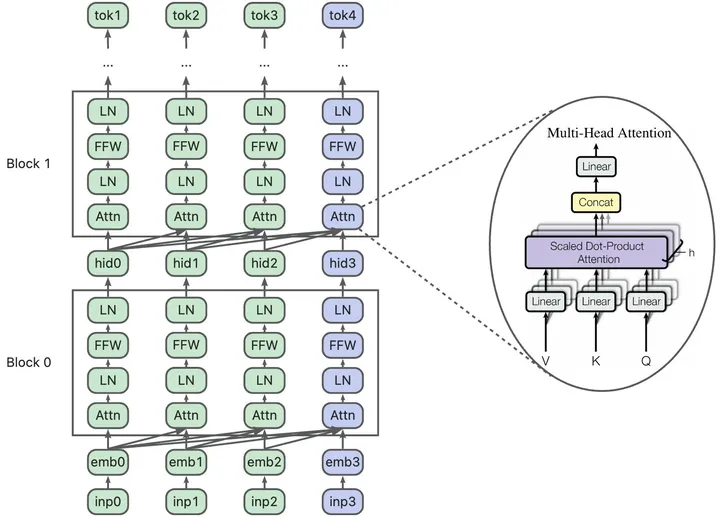
从网络结构角度来看,Transformer中Encoder与Decoder的主要区别在于Self-Attention机制的Mask应用。具体而言,Encoder在计算Self-Attention时不使用Mask,而Decoder则引入了Mask操作。
在Attention模块中的,对当前Q和所有的K计算相似度,然后通过Softmax操作得到权重,最后根据权重与对应的V成绩求和,得到Attention的Value值。
1. Norm:对数据归一化,将数据约束到高斯分布上,稳定训练;
2. Add&Residual:残差相加,避免梯度消失,构建更深的网络;
3. Feed Forward:将数据转化为非线性,更好表征复杂关系;
4. Masked Multi Head Attention:在Decoder中,将MHA中的矩阵与右上角进行掩码的矩阵相乘,其他操作与MHA相同;
5. Softmax:在模型的Decoder之后进行归一化,得到概率输出。
BERT(Bidirectional Encoder Representations from Transformers)是一种基于transformer的以Encoder为主的双向语言表征模型。
GPT(Generative Pre-trained Transformer),即生成式预训练Transformer模型,是一种基于Transformer架构的大规模预训练语言模型,它采用单向(从左到右)的自回归语言模型进行训练。
1)在预训练阶段:与BERT不同,GPT在预训练阶段只使用一个无监督任务:通过给定文本中的前N个单词,让模型预测第N+1个单词。即学习一个概率分布,即给定一系列文本片段(如单词、短语等),预测下一个文本片段的出现概率。这个过程也被称为自回归语言建模(Autoregressive Language Modeling)。
2)在微调阶段:在预训练阶段完成后,GPT模型已经学会了一定程度的语言知识。为了将模型应用于特定的NLP任务(如文本分类、摘要生成等),可以对模型进行进一步微调。 在微调阶段,GPT也会针对特定的NLP任务进行监督训练。完成微调后的GPT模型可应用于特定的NLP任务以获得较高的性能。
对话式GPT(Conversational Generative Pre-trained Transformer)是一种专为生成自然、流畅对话而设计的模型。它基于GPT架构,并利用多轮对话数据进行训练。与GPT相似,ChatGPT等对话模型同样采用了自回归语言模型,但在训练期间,它会对话数据的上下文信息进行建模,以生成更符合实际对话场景的回复。
在预训练阶段:模型首先需要在大量无标注文本数据上进行预训练。这些文本数据通常来自于互联网,例如维基百科、书籍、论坛等。预训练的目标是学习语言的一般规律,例如句子结构、语法、常识等。预训练采用的是自回归语言模型,即在给定上文的情况下,预测下一个词,优化模型参数以最大化训练数据上的对数似然。预训练完成后,将得到一个通用的语言模型。
在微调阶段:在预训练后的基础模型上,需要继续进行微调。微调过程通常需要有标注数据,例如人工标注的问答对、对话等,利用问答数据优化模型参数,以最大化给定任务的性能指标。微调可以采用有监督学习和强化学习等方法:通过有监督学习,模型通过正确的输入输出对学习;通过强化学习,模型通过与环境的交互,得到反馈并不断调整。
1. GPT是单向模型,只需要利用上文,Bert模型是双向模型,训练使用上下文,则更为复杂。
2. GPT是自回归模型,因此可以通过Prompt应用适配众多NLP任务;而Bert采用自编码,必须要先预训练再微调完成NLP任务。
在自回归生成模型生成sentence文本的过程中,token的生成方式是逐一生成(这也是为什么大模型可以进行流式输出),其中每个token的出现概率由之前tokens计算得到,即:
自2010年以来,随着深度学习技术进步,embedding技术在研究与应用上显著扩展。期间诞生了Word2Vec、GloVe和FastText等重要嵌入算法,通过神经网络训练或矩阵分解等方式学习单词的向量表示,并广泛应用于文本分类、机器翻译及情感分析等多种自然语言处理任务。
近年来,深度学习及自然语言处理领域的快速发展推动了embedding技术的持续改进。如BERT、ELMo和GPT等大模型能够生成基于上下文的词嵌入,更准确地反映词汇的语义及其所处情境。
在机器学习和自然语言处理中,embedding就是一个N维的实值向量,是指将高维度的数据(例如文字、图片、音频)映射到低维度空间的过程。embedding向量通常是一个由实数构成的向量,它将输入的数据表示成一个连续的数值空间中的点,它几乎可以用来表示任何事情。实值向量的embedding可以表示单词的语义,主要是因为这些embedding向量是根据单词在语言上下文中的出现模式进行学习的。
在使用大语言模型时,embedding可以解决大模型的输入限制,即将本地知识进行embedding化,通过embedding匹配获得相关性最高的内容,与query一起构建模型输入,最终获得答案,包含文档拆分、向量化、向量存储、向量检索、基于文档对话等。
Embedding的生成方法有很多,这些方法都有各自的优点和适用场景,选择最适合特定应用程序的嵌入生成方法需要根据具体情况进行评估和测试。几个比较经典的方法和库:
通过调整随机性控制参,可以用于控制生成文本的多样性,以temperature为例:当 temperature 较高时,概率分布更加平坦,因此采样出的标记更具多样性;当 temperature 较低时,概率分布更加尖锐,因此采样出的标记更倾向于概率最大的那个;当 temperature 等于 0 时,直接选择概率最大的标记,则相同的提示会产生相同的结果(存在部分模型该参数不能设置为0)。
本节主要针对在开源大模型落地过程中,关于模型的有监督调优阶段的相关实验,以及与知识库结合的实践过程中的一些相关总结和分享:首先,介绍了模型微调方法以及微调数据集的准备;其次,介绍了数据和超参数优化以及模型效果评价指标的常见方法;然后,基于之前的试验结果介绍了模型的测试和选型;最后,重点介绍了调优实践及与业务相关的尝试。
针对模型微调训练,常见的SFT数据集格式存在两种,分别是包含问题和答案两个字段的问答格式数据集,以及带有指令(instruction)的指令微调数据集。本节将对这两种数据集进行说明和对比。
通常我们希望模型遵循用户的指令,但只利用问答格式数据集对模型训练时,这种基础模型的语言建模目标不足以让模型学会以有用的方式遵循用户的指令。因此通常需要使用指令微调 (Instruction Fine-Tuning,IFT)方法来达到该目的,该方法除了使用情感分析、文本分类、摘要等经典 NLP 任务来微调模型外,还在非常多样化的任务集上向基础模型示范各种书面指令及其输出,从而实现对基础模型的微调。这些指令示范由三个主要部分组成 —— 指令、输入和输出。
其中,输入是可选的。一些任务只需要指令,如使用LLM做开放式文本生成。当存在输入时,输入和输出组成一个实例 (instance)。给定指令可以有多个输入和输出实例。如下例:
进行批量数据集字段检查,发现在部分数据集中,如alpaca_data_zh_51k.json,同一个数据集内部存在字段不一致情况或字段缺失情况,其包括[“instruction”, “input”, “输出”]、[“指示”, “输入”, “输出”]、[“instruction”, “输入”, “输出”]、[“instruction”, “input”] 等多种情况。因此,进行清洗和处理,处理为统一的数据格式和字段。
互联网语料基本上可以分为3大类:高质量语料(语句通顺且包含一定知识)、低质量语料(语句不通顺)、广告语料(语句通顺但重复率过高,如广告、网站说明、免责声明等)。其中低质量数据主要包括以下内容:
针对指令数据构建,可以通过如下的优化方式以让模型更好的理解指令以及具备泛化性: 1. 通过数据增强增加训练指令数据的多样性,增强模型的泛化能力。 2. 在训练阶段,可以对于特定下游任务进行相应的指令构建,同时在预测阶段,建议与训练阶段的指令或者特定任务的指令保持一定的一致性和相关性。 3. 适当构建 few shot 及COT(Chain of Thought) 数据加入训练,可以有助于模型的指令理解以及多轮对话能力。
大型语言模型(LLM)推理性能优化是当前AI应用部署的关键挑战。本节系统分析LLM推理过程中的性能瓶颈,并探讨主流优化技术及其理论基础。
LLM推理中的核心挑战主要体现在三个方面:
1.推理延迟高:自回归生成模式下单token生成速度难以满足实时交互需求
2.GPU利用率低:内存带宽受限导致计算资源无法充分利用,多数部署中GPU利用率仅为10%-30%
3.显存需求大:模型参数与KV-Cache共同占用大量显存,特别在长序列场景下容易出现OOM问题
针对这些挑战,业界已发展出多层次优化策略:
服务架构层:Continuous Batching、动态请求调度等技术提升系统整体吞吐量;
计算引擎层:PagedAttention、FlashAttention、算子融合等提高计算和内存效率;
模型优化层:量化技术、并行策略等减少资源需求并提升硬件利用率;
接下来将分析LLM推理过程中的性能问题,并逐一介绍各类优化技术的原理与实现。
推理常见问题分析
由于大模型一般都是采用自回归生成方式,即根据前面的语句预测下一个字的概率,而自回归生成方式上看会存在以下问题:
1. KV Cache占用显存大:
每个请求需要维护独立的KV缓存;
随着请求数量增加,KV缓存呈线性增长;
长序列场景下显存压力更大;
2. 解码算法复杂度:
3. 动态序列长度:
同时,现有系统采用静态连续内存分配策略,存在以下三类内存分配问题:
1. 预留浪费(reserved):需要为每个请求预留最大可能序列长度的内存空间,导致资源利用率低下;
2. 内部碎片(internal fragmentation):内存分配效率低导致已分配内存块内部存在未被充分使用的区域,降低内存的整体利用效率;
3. 外部碎片(external fragmentation):当小内存块无法被有效整合利用时,造成系统可用内存资源的浪费;

分析LLM结构及推理过程,对LLM推理的计算量、IO量和显存占用进行详细计算,并按照 Roofline方法 进行分析,定位推理速度慢、吞吐量低和OOM的原因。
推理过程及耗时分析
GPT模型推理分为两个阶段:
1. Prefill阶段:向模型输入context tokens,模型执行Context计算过程,该过程无论输如的context-length有多长,只需计算一次,输出第一个token,称为Prefill阶段。
2. Decode阶段:之后将生成的token作为input_id,执行自回归生成过程,称为Decode阶段,第二阶段反复进行。
大模型推理过程中的90%以上的时间耗费在第二阶段。单线程生成首个token的延迟一般不超过0.1s,后续每生成一个token的量级大概为50ms,推理时间和生成长度成线性关系。[6]

下图展示了Transformer编码器的核心架构,其中左侧部分呈现了多头注意力(MHA)模块的详细结构,右侧部分则展示了前馈神经网络(FFN)模块的计算流程图。

GPT类模型中解码器中的计算与序列长度的关系图如下:
对单个token生成过程的的计算分析,计算耗时主要集中在以下三个模块:
多头注意力(MHA)计算
层归一化(LayerNorm)
分组矩阵乘法(group gemm)
以GPT-2模型为例,计算耗时与序列长度的关系图如下:[7]

从上图分析可以得出:
1. 序列长度较短时,MHA(多头注意力)和FFN(前馈网络)中的投影层(projection layer)是主要的延迟来源,这主要是因为矩阵乘法运算的开销较大;
2. 序列长度较长时: 激活值之间(act-to-act)的延迟变得更加显著,非线性操作(如softmax、gelu等)的延迟超过了编码器(encoder)推理的延迟,这主要是由于序列长度增加导致注意力计算复杂度上升;
因此后续的性能分析和优化也需要重点关注这些计算密集型模块。
Roofline Model分析方法
Roofline Model是评估和分析高性能计算平台性能的有效工具,通过绘制性能上限与计算强度关系的图,直观展示系统瓶颈。

每个硬件平台都对应一个特定的Roofline图,其中关键参数包括:
硬件平台参数(对应图中折线):
峰值算力(π):计算平台每秒能完成的最大浮点运算次数(Maximum FLOPs Per Second),对应图中水平线的高度 - 单位:FLOPS (FLoating-point Operations Per Second)
内存带宽(β):计算平台每秒能完成的最大内存交换量(Maximum Memory Access Per Second),对应斜线的斜率 - 单位:Byte/s -计算强度上限(Imax):π/β,表示单位内存交换最多可支持的计算量 - 单位:FLOPs/Byte
算法/Kernel参数(对应图中屋檐下的某一点):
计算强度(I):计算量/访存量,表示每单位内存交换所执行的浮点运算次数 - 单位:FLOPs/Byte - 反映算法的内存利用效率计算强度I越大,内存使用效率越高。对应横轴x值。
理论性能上限(P):模型在特定平台上能达到的每秒浮点运算次数 - 单位:FLOPS - 受平台和算法特性双重限制,对应纵轴y值
根据Roofline模型划分的两个性能瓶颈区域:

因此有如下性能优化目标:
1. 提升模型的计算强度(Attainable Performance):通过多核并行等方式提高计算效率;
2. 提升计算密度(Operational Intensity):减少内存访问次数,降低带宽占用;

可以通过一些Roofline工具来生成得到相关数据,Roofline模型的核心价值在于揭示硬件资源限制与算法特性之间的关系,帮助开发者理解在特定计算平台约束下可达到的理论性能上限,从而指导性能优化方向。

推理优化目标
基于对LLM推理过程的分析,我们发现推理性能主要受内存带宽而非计算能力限制,而服务吞吐量则受限于可支持的最大批量大小。因此,LLM推理优化主要围绕以下三个核心目标展开:
1. 推理速度优化
降低单token生成延迟:通过优化计算和内存访问效率,减少每个token的生成时间
保证批量请求延迟:在增加batch_size的同时,确保单条请求的响应时间不会显著增加
优化长序列处理:针对长文本输入场景,优化KV-Cache管理和内存使用
2. 吞吐量优化
提升GPU资源利用率:通过Continuous Batching等技术提高GPU计算效率
优化请求调度:实现动态请求分配和负载均衡,最大化系统整体吞吐量
支持并发处理:通过并行计算和流水线处理提高并发能力
3. 资源占用优化
解决显存OOM问题:通过量化技术和内存管理优化减少显存占用
提高显存利用效率:优化KV-Cache存储和访问方式,减少内存碎片
支持更大模型部署:通过模型并行和量化技术,使大模型能在有限资源下运行
优化方案分类与对比
从性能瓶颈来看,推理性能主要受显存带宽限制,而服务吞吐量则主要受batch_size限制。因此,针对这些限制,优化工作主要从三个维度展开:服务层优化、推理引擎层优化和模型量化技术。服务层优化通过高效的批处理策略和特定场景优化提升系统吞吐量;推理引擎层优化通过创新的算法和并行技术突破计算瓶颈;模型量化技术则通过降低模型精度在保证性能的同时减少资源占用。
在实际应用中,需要根据具体场景和资源约束,选择合适的优化策略组合,才能达到最优的推理性能。
由于LLM推理过程主要受内存带宽限制,在较小batch_size的情况下,模型权重的加载时间占据了主要开销。此时增加batch_size并不会显著增加推理延迟,反而能带来显著的吞吐量提升。
通过合理配置请求的batch策略,可以大幅提升系统吞吐量。因此,为了优化服务吞吐量和提升资源利用效率,batch策略的优化是其中最关键的部分。
Dynamic-Batching
Dynamic-batching的效果类似电梯,基于Dynamic-batching的服务主要服务侧维护一个task-queue,需要等够设置的batch size后进行批处理,或者需要超过等待时间。
- 场景:通常用于ResNet、BERT在线服务提取特征等应用场景。
- 局限:GPT类大模型具有自回归执行时间长、序列长等特性,不太适合GPT模型推理,主要表现在:

Continuous-Batching
Continuous-Batching(连续批处理)类似自动扶梯,是一种针对自回归生成模型特性设计的高效批处理机制,其核心思想是动态重组批次,而非等待一个完整批次的计算结束后才处理下一批。 在连续批处理中,新请求会立即加入当前批次,仅需等待一个token-step(约20毫秒)即可开始计算,而不需要等待当前批次的计算结束。
如上图,当请求1和2正在处理时,请求3、4、5和6到达系统。基于Continuous-Batching策略,新请求立即加入计算批次,无需等待前序请求完成,极大提高了服务效率。
Continuous-Batching通过动态重组批次的方式,实现了毫秒级响应、提升GPU利用率和吞吐量,同时显著减少了请求等待时间,从而优化了整体用户体验。
流式交互式生成
为了满足不同场景下LLM服务的需求,服务层提供了流式返回、交互式对话以及continue/cancel等关键功能特性:continue/cancel功能允许系统先返回部分生成结果,用户可以根据结果质量决定是继续生成还是中断生成过程,从而提升整体推理效率。采用web-socket和server-sent events(SSE)等协议来实现客户端的流式返回。
目前主流的服务框架都实现了对这些特性的支持。
长序列推理
LLM推理受限于预设的上下文窗口长度,在很多场景需要扩展模型的有效序列长度,主要解决方案如下表。
方案 | 实现方式 | 优势 | 劣势 | 适用场景 |
从头训练 | 直接训练长序列模型 | 效果最好 | 计算成本高 | 资源充足场景 |
继续训练 | 在基础模型上微调 | 成本适中 | 效果有限 | 快速迭代场景 |
可扩展位置编码 | 修改位置编码机制 | 支持动态扩展 | 需修改架构 | 定制化需求 |
位置编码内插 | 调整scale参数 | 简单易用 | 效果一般 | 通用推理场景 |
KV-Cache机制
KV-Cache的主要思想是空间换时间,主要因为和CNN、RNN等架构的深度学习网络模型相比,生成式模型的推理过程的特点是,输出一个回答(长度为N)过程中执行了N次推理迭代,具有很高的时间复杂度,因此需要通过缓存来优化推理效率。
由上文中自回归生成模型的token计算公式可知,第个token的概率分布以及概率最大的token 的选择会受到前个token的影响,而不会受到个及之后token的影响:
1. 计算:将前个token输入到模型,得到第个token的概率分布,选择概率最大的token作为。
2. 计算:同样的方式,将前个token输入到模型,得到概率分布,并生成第个token。
3. 迭代输出直到达到停止条件:重复上述步骤,直到达到停止条件(停止符、停止长度等)。
因此,计算时,可以对K和V的值进行缓存复用后,且只需要计算相关序列的值(蓝色框)而不再需要计算之前的单元(绿色框)。
如图所示,在生成第9个token时,模型需要计算Self-Attention。如果不使用KV-Cache,每一层Decoder Layer都需要重新计算之前所有token的key和value,并与当前token进行scale-dot-product计算。通过缓存之前步骤的key和value,在生成新token时,每层mask-MHA计算可以直接使用缓存的key和value,避免了重复计算,从而显著提升了推理效率。[3]

KV-Cache是大模型推理中最有效的优化方法之一,因此目前在transformers库及常用加速框架中通常把该特性已经在config配置中设置为默认使用,在基于FasterTransformer库的GPTNeoX、GPTJ、GPT等模型中,也都分配了key_cache_和value_cache_成员变量以保存推理过程中的key/value。
PagedAttention
PagedAttention主要为了解决传统KV-Cache管理机制的局限性。KV-Cache其在自回归生成过程中,系统需要缓存Key和Value值以优化计算效率。以FasterTransformer(FT)为例,在Beam Search场景下,KV-Cache的显存分配公式为:

其中,layer表示Transformer模型的层数,每一层都需要存储自己的KV-Cache;beam_size 表示每个时间步保留的候选序列数量,序列长度seq_len,包括输入序列和已生成的token长度;dim表示每个token的隐藏层维度大小;由于需要同时存储Key和Value两个矩阵所以需要乘2。
这个公式反映了KV-Cache显存占用的几个关键特点:
1)线性增长:显存占用与模型层数、批处理大小、束搜索宽度和序列长度都呈线性关系。
2)双重存储:由于需要同时存储Key和Value,所以需要乘以2。
3)维度依赖:显存占用与模型的隐藏层维度大小直接相关。
这种分配方式存在三个主要问题,导致显存利用率低下:
1. 变长序列对齐冗余:在动态批处理(dynamic-batching)场景下,系统需要按照最长序列长度分配显存空间。大多数推理框架在服务启动时会设定max_total_tokens参数,为每个请求分配固定长度的显存缓存。当请求序列长度差异较大时,会造成大量显存空间浪费。
2. Beam-Search冗余:在Beam-Search解码过程中,不同候选序列可能共享相同的前缀。传统KV-Cache存储方式会重复存储这些共享前缀,造成显存冗余。
3. 相同Prompt冗余:在实际应用中,同一业务场景下的请求通常使用相同的系统提示词(Prompt),也会造成浪费。
该算法的核心思想是允许在非连续的显存空间中存储逻辑上连续的key和value张量。具体实现方式为:将每个序列的KV-Cache分为固定大小的块(blocks),每块包含固定数量token的key和value张量,这些块在显存中不需要物理连续分布。
PagedAttention将物理空间当做KV Cache,将其划分为固定大小的连续内存块,从左到右存储。PagedAttention允许在非连续内存空间存储K和V,更适合LLM的推理。
类比于在操作系统中的虚拟内存,可以将块比作页面,token比作字节,sequence则相当于进程;通过块表,sequence的逻辑块被映射到非连续的物理块上;当生成新的token时物理块按需分配;基于分块策略每个sequence只在最后一个块中可能会留有未使用的空间。
逻辑与物理映射
在逻辑空间与物理空间的映射过程中,vLLM通过维护一个映射表(Block table)来实现这一功能。当处理如“Alan Turing is a computer scientist”这样的输入时,每当生成新的token,系统将执行以下步骤:
1. 查询Block table中的Physical block编号。
2. 定位到相应的物理内存位置进行数据存储,并更新Block table中Filled slots的信息。
3. 若生成新token(例如“renowned”)需要额外的存储空间,则分配新的物理内存块,并相应地更新Block table。
多个Request时同理,物理空间不需要连续,随机选取Block即可。

内存利用提升
内存利用率显著提升,浪费空间仅占KV Cache总空间的4%以下,整体内存利用率提升了3-5倍。这种优化效果主要来自两个方面:首先,内部碎片被最小化,因为碎片仅出现在最后一个block中,且大小不超过block size。论文中采用的block size为16或32个token,远小于传统方案中近千量级的tokens长度;其次,通过分块管理机制,完全避免了外部内存碎片的产生。
共享机制优化
并行采样(Parallel Sampling)场景:
多个候选输出序列(candidates)通常会共享相同的输入提示(Prompt)。针对这种情况,PagedAttention采用了KV块共享机制(Sharing KV blocks),其工作原理如下:
当两个输出序列共享同一个Prompt时,虽然在逻辑空间上各自维护独立的存储,但在物理空间上只需保存一份KV缓存。具体实现通过以下步骤:
1. 引用计数管理:
2. 序列A生成新token时:
3. 序列B生成新token时:
这种机制有效减少了内存占用,提高了系统资源利用率。
Beam search场景:
在一些相对复杂的场景如Beam search时,其每一次迭代只保留 top-k 个候选序列。
PagedAttention 对其处理与 parallel sampling 不同,它不仅会共享 prompt 的 KV cache,还会基于copy-on-write和mapping机制来有效支持动态共享候选块。
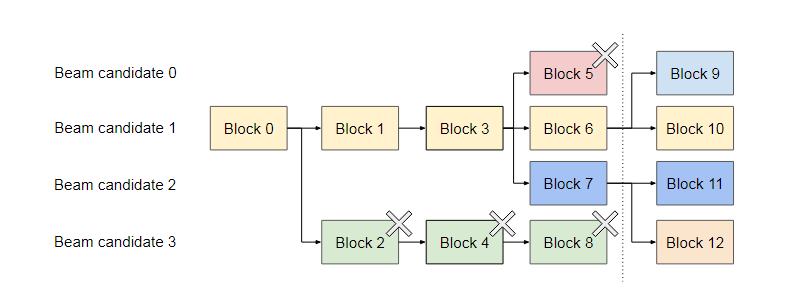
在虚线之前的每个候选序列使用了4个Block。其中,Block 0被所有序列共享,Block 1由候选序列0、1、2共享,而Block 2则仅被候选序列3使用。虚线之后,由于候选序列3不再需要Block 2、4和8,这些块被释放。
因此,通过引用计数的方法,beam-search能够及时回收无效分支占用的显存。对于相同的prompt请求,可以通过增加引用计数来重用同一块 prompt kv-cache。
PageAttention的内存共享机制显著减少了复杂采样算法(如并行采样和beam search)的内存开销,内存使用量降低一半左右。实测结果显示,采用PagedAttention优化后,推理速度没有明显下降,可支持的batch_size相比增加两倍以上。目前,TGI等框架已集成了PagedAttention功能。
Sharing prefix场景:
针对system prompt等不会频繁修改的prefix信息存储下来,可以提前计算system prompt 的 KV 值并缓存下来作为共享部分,只需要计算新的token的KV Cache并进行拼接。

自动前缀缓存(APC)
自动前缀缓存(Automatic Prefix Caching, APC)是一种针对大规模语言模型(LLM)推理场景设计的高级内存优化技术。通过智能缓存和复用已计算的键值对(KV)缓存,APC能够显著提升推理效率和系统吞吐量。这一技术特别适用于那些请求间存在共享前缀内容的应用场景,如系统提示、文档内容或对话历史。
在实际应用中,不同请求间经常共享相同的前缀内容。其工作流程如下:
1. 缓存管理:系统缓存现有请求的KV值,并建立高效索引结构。
2. 前缀检测:新请求到达时检测是否与已有请求共享前缀。
3. 计算复用:对共享前缀部分直接复用已缓存的KV值,仅计算新增内容。
通过这种方式,APC能够显著减少重复计算,提高推理速度和系统吞吐量。
APC的核心在于构建高效的映射关系:hash(prefix tokens + block tokens) <--> KV Block。通过在vLLM的KV缓存管理中引入一层间接映射,所有具有相同哈希值的KV块可以被映射至同一物理块,并共享内存空间,从而避免了重复计算。
当缓存空间满时,系统采取多层次淘汰机制的缓存管理策略:
1. 首先淘汰引用计数为0的KV块(即无活跃请求使用)。
2. 对于多个可淘汰块,依据LRU(最近最少使用)原则进行筛选。
3. 若时间戳相同,则优先淘汰前缀较长的块,以优化内存使用效率。
在如下场景有较大优化:
作为一种典型的“以空间换时间”优化方法,APC特别适用于高并发、低延迟需求且请求间存在前缀相似性的LLM应用场景。
分布式推理并行方案
TP(张量并行)和PP(流水线并行)是用于扩展大规模模型训练任务的通用方法:

TP并行
TP并行:把一个变量分散到多个设备并共同完成某个或多个计算操作。(应对单个 Tensor/Op 很大或者模型很大情况)
由于层叠的Transformer Layer中,主要是Self-Attention和MLP,所以主要可分为MHA并行和MLP并行。[8]

PP并行
当模型规模增大到一定程度,单张卡放置不下模型,则可以将大模型按层进行切分,放置在多个设备上。
其主要依照模型的运算符的操作将模型的上下游算子分配为不同的流水阶段,每个设备负责其中的一个阶段模型的存储和计算。一个完整请求的计算过程为:首先在gpu0上处理,随后继续在gpu1上进行,此时gpu0可以接受新的请求;依此类推,直到请求完成。
通过PP并行可以实现数据传输量较少、Batch_size可以更大:
为了提升设备效率,已经提出了一些复杂的多流水并行方法。例如,GPipe借鉴了数据并行的思想,将批次(Batch)拆分为更小的微批次(Micro-Batch),如F0,1、F0,2等。这样,下游设备可以更早地获得可计算的数据,从而减少设备空闲(Bubble)时间,提高整体效率。

负载均衡
在大模型部署过程中,当存在多个单卡可容纳的模型时,可以通过多模型的Pipeline并行(PP)部署来实现负载的自动均衡。根据AlpaServe论文中的原理,假设在两张GPU卡(GPU1和GPU2)上部署了两个模型(Model A和Model B),对以下两种部署方案进行了对比分析:
无协作分配方案:每个模型独占一个GPU卡。当请求到来时,如果所有请求(如R1-R4)都是针对Model A的突发请求,在没有采用PP并行部署的情况下,这些请求需要在GPU1上串行处理,导致GPU2(运行Model B)处于空闲状态。
PP并行协作式部署:采用PP并行方法,模型的不同部分被分配到两块GPU上。这样,当GPU1正在处理Model A的一部分时,GPU2可以同时处理Model B的一部分。这种方法使得来自不同模型的请求更有可能被均衡分配到两块GPU上进行处理。
通过比较可以看出,在多模型请求存在时间错峰的情况下,采用PP并行部署(方案b)能够更好地实现负载均衡,显著减少请求的服务时间,从而提高整体资源利用率。

对比与选择
从通信量的角度来看,大致排序为:TP > DP> PP,由于TP需要在每次迭代中频繁交换被分割的张量,导致通信量较大;DP则在每个epoch结束时进行一次大规模的数据交换。相比之下,PP虽然通信需求较低,但需精细调度与同步以确保正确执行。
选择建议:
TP因其加速性能被广泛应用于模型推理;PP则通过按层划分模型,能够处理单个设备无法容纳的大规模模型。
对于中小型模型,优先考虑TP进行加速;对于超大规模模型,推荐采用PP。
在实际应用中,通常结合多种并行策略优化性能。例如,单个计算节点内采用张量并行(TP)分割模型,跨多个节点时利用数据并行(DP)加速训练。引入流水线并行(PP)至TP架构,进一步降低模型复杂性。选择并行策略时,需综合考虑模型大小、硬件配置及数据集特点。
算子优化和融合
在深度学习推理引擎中,算子层面的优化是提升计算性能的关键环节。例如,PyTorch 2.0对LayerNorm的引入Welford算法进行均值和方差计算的优化,显著提升并行性能。[9]优化策略可分为两类:
1. 工程实现优化:针对现有kernel函数进行底层实现层面的优化,主要关注计算资源的利用效率
2. 算法优化:通过数学变换,采用更高效的计算方法替代原有实现,从算法层面提升性能
算子融合(Operator Fusion)是深度学习推理优化的核心方法之一,核心思想是将多个串行执行的算子合并为复合算子,通过减少中间数据传输和Kernel启动次数来提升性能。具体优势包括:
- 显存带宽优化:合并后的算子无需将中间结果写入显存,降低内存访问次数。
- 降低Kernel调用次数:每个算子对应一次Kernel启动,合并后可显著减少启动开销。
- 提升计算密度:复合算子通过扩大并行粒度更充分地利用计算资源。
FasterTransformer和ByteTransformer[10]等优化方法均在此方面进行了优化,以Transformer的非常重要的Add&Normalize操作为例,原始实现与优化后的对比如下: 1. 原始实现(PyTorch)流程:Multi-Head Attention输出后,依次执行逐元素相加(element-wise addition)和LayerNorm。存在的问题是:需启动多个独立Kernel(Add、LayerNorm)。 2. 优化实现(FasterTransformer)的融合策略:将Add与LayerNorm合并为一个算子(如AddBiasResidualLayerNorm),仅需启动1个Kernel。
通过算子融合,Transformer层的对应结构可以简化为下图所示的形式,显著提升了推理性能:

大规模语言模型的推理性能受限于显存带宽,而推理吞吐量则受显存容量和最大批次大小(max_batch_size)的限制。在推理过程中,显存溢出(OOM)问题使得无法通过增加批次大小来进一步提升吞吐量。

从上图可以看到,近年来,大型语言模型的模型大小的发展速度比GPU等计算资源更快,从而导致对显存的供应和需求之间存在差距,因此,模型量化技术已逐渐成为优化模型推理性能和服务吞吐量的重要手段。
量化概述
量化(Quantization)通常指的是定点数量化,即小数点位置固定,这与常见的浮点数表示法形成对比。量化的主要目的是在牺牲少量精度的基础上,压缩模型体积,使其能够在资源受限的环境中运行,例如嵌入式设备,而无需依赖高性能服务器或GPU。
定点数与浮点数这两种数值表示方法主要区别在于小数点位置的处理:定点数的小数点位置固定,整数和小数部分各自占用一定数量的位;浮点数则通过存储有效数字(尾数)和指数来表示数值,因此能够覆盖更广的数值范围。
模型量化的主要优势包括:
1. 降低内存及显存占用:量化技术能够显著减少模型参数的存储需求。例如,将一个具有16B参数的模型从FP16量化到INT4,显存占用可从32GB减少至10GB,使得该模型能够在消费级GPU上运行。
2. 加速计算:在支持低精度计算的硬件上,量化模型可通过INT8 GEMM内核执行计算,通常比使用FP16或FP32格式更快。量化减少了单个数据点所需的比特数,从而减少了计算过程中的I/O通信量,进一步提升了计算效率。
3. 增大批次大小以加快处理速度:由于量化降低了显存需求,可以在相同的硬件条件下增加批次大小,从而提高单次推理处理的样本数量,进而提升并行度和计算速度。
量化目标:在大规模语言模型(LLM)的推理过程中,量化技术主要应用于权重(Weight)、激活值(Activation)以及键值(KV)缓存三个模块,此外还可以针对模型参数、激活值及梯度进行量化。
通过这三个维度的方法进行量化优化,能显著提升模型的推理吞吐量和执行效率。
 Emergent Features问题:
Emergent Features问题:
随着模型参数量的增加,参数和激活值中会出现系统性的异常凸出特征,这些异常值在所有层中普遍存在,形成了大尺度的凸出特征。这种特征扩大了量化的数值范围,降低了Tensor级别的量化精度,从而影响了量化后模型的性能指标。
针对大语言模型量化的这种问题,当前的解决方案思路有几种:
- TimDitmmers提出的混合精度量化方案LLM.int8
- MIT团队提出的平滑量化(SmoothQuant)方案 - 高通通过引入截断softmax和门控注意力机制来降低异常值的幅度
前两种方法都旨在解决激活值中的异常值计算问题,第三种方法则从模型结构层面入手,使得传统的W8A8量化算法在LLM中也能保持良好的性能。
在SmoothQuant论文中,对大模型量化的难点进行了总结,指出大模型量化具有以下特点:[11]
1. 激活值量化难度高于参数量化:如图所示,权重参数值的分布相对平稳,而激活值的分布范围非常广泛,存在显著的离群点。
2. 激活值中的离群点导致量化困难:部分激活值的值可能达到其他激活值的100倍左右。在这种情况下,如果直接对Tensor进行量化,异常离群点将主导量化范围,导致有效量化比特位降低,大部分激活值被压缩到0附近,量化误差显著增大。
3. 离群点分布于特定通道:异常激活值的比例较小且集中在固定的通道内。基于这一特性,后续的LLM.int8和SmoothQuant方法得以实现更有效的量化。
模型参数和异常值的分布如下图所示:

SmoothQuant方法对离群点进行了平滑量化:

SmoothQuant中的混合精度方法:
GPTQ量化方法
GPTQ是一种专为GPT系列大语言模型设计的后训练量化技术。该技术通过逐个量化模型中每个block的参数,并适当调整未量化的参数来补偿量化带来的精度损失,从而实现模型压缩。执行GPTQ需要准备特定的校准数据集以确保量化过程的准确性。
GPTQ的发展根植于Yann LeCun于1990年提出的OBD算法,之后经过OBS、OBC(或称OBQ)等多种方法的演化,最终形成了当前的GPTQ技术框架。
在GPTQ中,模型的每一层被划分为若干个block,针对每个block,采用逐列量化的方式,并通过最小化平方重建误差优化未量化参数。这样,在保证模型性能的同时,也能实现有效的参数压缩。
以特定计算设备为例,使用fp16格式进行推理时,批量大小(batch size)仅能达到4(最大令牌数max_tokens为2048)。相比之下,GPTQ能够在相同的令牌数限制下支持批量大小达到8。尽管在小批量推理场景下FP16可能提供更快的速度,但GPTQ通过支持更大的批量大小,能够在整体吞吐量(throughput)方面优于FP16。

GPTQ量化程序通过利用Cholesky分解中存储的逆Hessian信息,在给定步骤中对连续列块进行量化(标记为粗体),并在步骤结束时更新剩余权重(标记为蓝色)。此量化过程在每个块内递归执行,当前正在处理的是标记为白色的中间列。
当前大语言模型from Zero to Hero的完整训练过程,通常认为主要分为基座预训练(Base pretrain)和大模型微调。其中,大预言模型的基座预训练通常指利用无监督或自监督学习方法让模型学习到通用语言能力,这个过程往往需要利用大量语料以及大量的计算资源。
大模型微调阶段中,可以使用更少的资源消耗和时间,提升模型在领域数据集上的效果,目前大家较为公认的LLM微调优化阶段,通常主要指的是如下几个阶段[12]:
1. 监督微调(Supervised Fine-Tuning,SFT):使用精选的标注数据监督微调预训练模型。
2. 奖励模型微调(Reward Modeling):使用一个包含人类对同一问题的多个答案打分的数据集来训练一个单独的奖励模型。
3. 基于人类反馈的强化学习(RLHF):基于更多人类反馈数据集,利用强化学习算法根据模型的奖励反馈进一步调优模型并与人类进行对齐。
可以在训练中采用的一些训练方法有:
1. 微调(Fine-Tuning):在预训练模型的基础上,使用特定任务的数据进行微调;可提高模型在特定任务上的性能。
2. 知识蒸馏(Knowledge Distillation):使用大型教师模型的知识来训练小型学生模型;提高小型模型的性能,同时减少计算资源需求。
3. 多任务学习(Multi-Task Learning):同时训练多个相关任务,共享部分模型参数;提高模型在多个任务上的性能,同时减少过拟合。
4. 迁移学习(Transfer Learning):利用预训练模型在新任务上进行微调;减少训练时间和数据需求,提高模型性能。
基座预训练
大语言模型的基座(Base)通常指的是在大量文本数据上进行预训练的初始模型。这个初始模型作为一个基础框架,具有一定程度的通用语言理解能力,但可能在特定任务上的表现尚不理想。预训练模型的目的是让模型学习到语言的基本结构、语法规则和一般知识,从而为后续的任务定向训练打下基础。
这个基座模型在许多自然语言处理任务上具有较强的表现,但为了在特定任务上取得更好的性能,通常需要对其进行进一步的微调。通过对基座模型进行微调,可以使其更好地适应特定任务的需求,从而实现更高的性能。
Prompt微调
Prompt Tuning是大模型微调方法中的一种常用方法,包括Prefix-Tuning、P-Tuning、Parameter-Efficient Prompt Tuning、P-Tuning v2、LoRA等方法。[13、14、15、16、17]
SFT微调
模型的监督微调,是一种在深度学习预训练模型中最常被使用到的模型调优方式,其通常指对预先训练好的神经网络模型,针对下游任务,在少量的监督数据上完成参数重新训练的技术。
同样,LLM的SFT微调是指对预先训练好的大型语言模型(如GPT系列)进行监督式微调。通过使用大量的人工标注数据,根据特定任务需求,进一步优化模型的性能。这些数据通常包括输入与对应的期望输出,让模型学会如何从输入得出正确的输出。微调的过程可以看作是在原始预训练模型的基础上,为其适应特定任务场景而进行的个性化训练。
SFT在LLM训练过程中的应用有以下重要原因:
1)针对特定任务提升性能:预训练过程,大规模的无监督训练可以学习通用语义,但是在特定任务上可能无法表现出相似的性能。因此通过利用有标签数据,进行有监督微调,可以针对对应数据和针对特定任务的性能。
2)针对特定领域提高适应性:在特定领域进行有监督训练,可以适应其中的专业数据、表达结果和语义。
3)针对数据稀缺的任务:某些很难获取大量有标签数据情况下,通过使用有限的标签数据来训练模型,便可获得较好的模型效果。
RL微调
强化学习是一种利用反馈来学习策略的范式。具体而言,强化学习的模型(Agent)与环境交互,对于每个给定状态st采取动作at并从环境获得奖励rt,同时进入下一状态st+1,这一过程循环往复。在积累了这一系列交互经验后,模型通过调整自己的策略以让交互过程得到的奖励最大化。这样一来Agent就学习到了在给定状态下采取有益的动作的策略,实现了强化学习的目标。
LLM固然有很强的自然语言理解能力,但我们更希望它能够理解人类指令并做出对人有帮助的回答,因此,需要让LLM的行为与人类“对齐”。为此,以InstructGPT为代表的一系列工作便尝试通过强化学习让LLM与人类的行为对齐。InstructGPT的核心由两个模型构成:一个反馈模型(RM),它给定一对模型输入和输出,反馈该输出的合理程度(有多好)打分;一个生成式语言模型,给定输出生成一段输出,并利用RM给出的打分作为奖励进行强化学习。只要让RM能很好的反应人类的偏好,就可以让生成模型与人类行为进行对齐。[12]
奖励函数训练(Reward Modeling, RM):RM(Reward Modeling, RM)奖励函数训练是指为强化学习任务设计奖励函数。奖励函数是一个用于评估AI智能体在特定任务中表现的度量,引导智能体在学习过程中采取正确的行动。RBRM是一种基于排序的奖励建模方法,通过对多个候选输出进行人工排序,为输出赋予相对优劣,从而指导模型生成更好的回答。这种方法可以帮助解决常规奖励建模方法在一些情况下难以为模型提供足够明确指导的问题。
RLHF:基于RM/RBRM的PPO强化学习:PPO(Proximal Policy Optimization,最近邻优化策略)是一种强化学习算法,通过优化模型的策略(即在给定输入时选择动作的方式)来提高模型性能。在基于RM或RBRM的PPO训练中,模型利用设计好的奖励函数(或基于排序的奖励模型)来学习如何为特定任务生成更好的输出。通过与环境交互并获取奖励信号,模型不断调整自身策略,以便在未来的相似任务中获得更高的奖励。PPO算法的优势在于其能够在保持稳定性的同时实现较高的性能。
人类对齐
大语言模型的与人类对齐是指让人工智能模型理解、遵循并适应人类的价值观、需求和期望。这意味着让模型在处理各种任务时,不仅要提供准确和有帮助的信息,还要确保所生成的内容遵循道德、法律和社会规范,避免产生有害或误导性的结果。
为了实现与人类的对齐,需要在模型的训练和优化过程中充分考虑人类价值观。这包括:
1. 在监督式微调阶段使用具有明确指导意义的标注数据,
2. 在奖励建模阶段设计合适的奖励函数,
3. 在强化学习阶段根据实际反馈调整模型策略。
总之,与人类对齐是确保大型语言模型能够更好地服务于人类社会的关键因素。通过关注人类价值观并将其纳入模型训练过程,可以使模型更加可靠、安全和有用。
后训练任务目标
模型后训练阶段涉及创建专门的数据集,这些数据集包含旨在指导模型在不同情境下的回复效果,以下是两类常见的后训练任务目标:
1. 指令/对话微调:主要旨在使模型能够遵循指令、执行任务、参与多轮对话、遵守安全规范并拒绝不当请求。如今,许多数据集由AI自动生成,随后经过人工审核和编辑以确保质量。
2. 领域特定微调:该方法的目标是使模型适应特定领域的需求,如医学、法律或编程。通过在这些领域的高质量数据上进行微调,模型能够生成更专业、更准确的响应。
特殊token的使用
在后训练阶段,还会引入一些在预训练阶段未使用的特殊token。这些token有助于模型理解交互的结构。例如,通过标记用户输入的起始与结束、标记AI响应的起始位置等特殊token,可以确保模型能够正确区分提示和回答,从而生成更符合上下文的响应。
通过后训练的特殊token,模型不仅能够更好地理解任务和指令,还能在特定领域和复杂交互中表现更好。
随着AI模型的规模越来越大,分布式训练技术越来越被广泛使用。现行的分布式训练方法主要包含两个部分:数据并行(Data Parallel)和模型并行(Model Parallel)。其中,数据并行是将模型完整拷贝到多张显卡中,对批次数据进行并行计算,适合规模小而数据多的训练场景;而模型并行适合超大规模参数的模型训练,将模型不同的部分分别加载到不同的显卡中,依次计算得出结果。
DeepSpeed方法
Deepspeed方法是微软开源的模型训练框架,主要有流水线并行, 以及ZeRO内存优化技术等。[18]
DeepSpeed 实现了ZeRO论文中描述的所有内容,目前已支持:优化器状态分区(ZeRO 阶段 1)、梯度划分(ZeRO stage 2)、参数划分(ZeRO stage 3、自定义混合精度训练处理一系列快速的基于 CUDA扩展的优化器、ZeRO-Offload 到 CPU 和磁盘。DeepSpeed ZeRO-2 主要仅用于训练,因为它的特征对推理没有用。 DeepSpeed ZeRO-3 也可用于推理,因为它允许将大型模型加载到多个 GPU 上,这在单个 GPU 上是不可能的。
集成DeepSpeed加速可以通过2种方式:1)在加速配置中通过DeepSpeed配置文件规范集成了DeepSpeed功能。只需提供您的自定义配置文件或使用我们的模板。本文的大部分内容都集中在这个特性上。这支持DeepSpeed的所有核心功能,并为用户提供了很大的灵活性。用户可能需要根据配置更改几行代码。2)通过deepspeed_plugin进行集成。这支持DeepSpeed功能的子集,并为其余配置使用默认选项。用户不需要更改任何代码,对于那些对DeepSpeed的大多数默认设置都很满意的人来说是好的。
在对话场景中,以基于deepspeed方法利用问答数据集对LLM模型进一步sft微调为例。进行模型的微调训练脚本如下:
deepspeed\--include="localhost:0,1,2,3"\./train_sft.py\--deepspeed./ds_config/ds_config_zero3.json\--model_name_or_pathTigerResearch/tigerbot-7b-sft\--dataset_nameTigerResearch/dev_sft\--do_train\--output_dir./ckpt-sft\--overwrite_output_dir\--preprocess_num_workers8\--num_train_epochs5\--learning_rate1e-5\--evaluation_strategysteps\--eval_steps10\--bf16True\--save_strategysteps\--save_steps10\--save_total_limit2\--logging_steps10\--tf32True\--per_device_train_batch_size2\--per_device_eval_batch_size2
在该启动命令配置中,模型的参数主要有以下几个部分:
模型指定部分,指定模型的本地路径或模型名称model_name_or_path(如果本地不存在默认会直接根据指定名称从huggingface进行下载),以及微调后的模型输出路径output_dir。
训练数据部分,需要将数据集划分为训练集和验证集,并分别进行指定训练数据dataset_name等。
模型参数部分,包括模型训练次数num_train_epochs、输入输出的文本长度max_source_length和max_target_length、批处理相关参数per_device_train_batch_size和per_device_eval_batch_size,模型学习率learning_rate等。
计算设备部分,如果需要指定其他运算设备或仅使用单卡,只需要调整CUDA_VISIBLE_DEVICES为指定设备ID即可。
其中,在ds_config_zero3.json配置文件中的配置参数如下,可以看到,在参数配置文件中,指定了学习率、优化器等多种模型参数。
{"fp16":{"enabled":"auto","loss_scale":0,"loss_scale_window":1000,"initial_scale_power":16,"hysteresis":2,"min_loss_scale":1},"bf16":{"enabled":"auto"},"optimizer":{"type":"AdamW","params":{"lr":"auto","betas":"auto","eps":"auto","weight_decay":"auto"}},"scheduler":{"type":"WarmupLR","params":{"warmup_min_lr":"auto","warmup_max_lr":"auto","warmup_num_steps":"auto"}},"zero_optimization":{"stage":3,"offload_optimizer":{"device":"cpu","pin_memory":true},"offload_param":{"device":"cpu","pin_memory":true},"overlap_comm":true,"contiguous_gradients":true,"sub_group_size":1000000000.0,"reduce_bucket_size":"auto","stage3_prefetch_bucket_size":"auto","stage3_param_persistence_threshold":"auto","stage3_max_live_parameters":1000000000.0,"stage3_max_reuse_distance":1000000000.0,"stage3_gather_16bit_weights_on_model_save":true},"gradient_accumulation_steps":"auto","gradient_clipping":"auto","steps_per_print":2000,"train_batch_size":"auto","train_micro_batch_size_per_gpu":"auto","wall_clock_breakdown":false}Megatron方法
Megatron是NVIDIA提出的一种由于分布式训练大规模语言模型的架构,是一个基于 PyTorch 的框架,针对Transformer进行了专门的优化。它可以高效利用算力、显存和通信带宽,大幅提升了大语言模型大规模预训练的效率。Megatron-LM已经成为许多大语言模型预训练任务的首选框架。[19]
大规模并行训练的一个关键因素是并行训练策略的选择。在[20、21]中介绍了Megatron-LM常见的大规模训练策略。
如下为一段利用 Megatron-LM方法进行加速模型训练的示例,可以参考如下所示的脚本配置模型架构和训练参数:
GPUS_PER_NODE=8MASTER_ADDR=localhostMASTER_PORT=6001NNODES=1NODE_RANK=0WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))DISTRIBUTED_ARGS="--nproc_per_node$GPUS_PER_NODE--nnodes$NNODES--node_rank$NODE_RANK--master_addr$MASTER_ADDR--master_port$MASTER_PORT"CHECKPOINT_PATH=/workspace/Megatron-LM/experiments/codeparrot-smallVOCAB_FILE=vocab.jsonMERGE_FILE=merges.txtDATA_PATH=codeparrot_content_documentGPT_ARGS="--num-layers12--hidden-size768--num-attention-heads12--seq-length1024--max-position-embeddings1024--micro-batch-size12--global-batch-size192--lr0.0005--train-iters150000--lr-decay-iters150000--lr-decay-stylecosine--lr-warmup-iters2000--weight-decay.1--adam-beta2.999--fp16--log-interval10--save-interval2000--eval-interval200--eval-iters10"TENSORBOARD_ARGS="--tensorboard-direxperiments/tensorboard"python3-mtorch.distributed.launch$DISTRIBUTED_ARGS\pretrain_gpt.py\--tensor-model-parallel-size1\--pipeline-model-parallel-size1\$GPT_ARGS\--vocab-file$VOCAB_FILE\--merge-file$MERGE_FILE\--save$CHECKPOINT_PATH\--load$CHECKPOINT_PATH\--data-path$DATA_PATH\$TENSORBOARD_ARGS
本节主要分析如何在大模型训练过程中,优化训练性能,加快训练速度(即提高数据吞吐量)以及优化显存利用率。在huggingface、nvidia等社区里有提到很多在GPU设备上进行的训练优化方法,如下为一些较为通用的方法:
通过上述表格可以看出,不同的技术手段针对训练速度和显存管理有着各自的优势。合理选择并结合使用这些技术,可以显著提高深度学习模型在GPU上的训练效率。 在本节将对训练性能优化相关方法进行具体介绍。
并行化和批处理
并行化和批处理是训练过程的重要并行化手段。以Nvidia进行的性能测试实验为例,下图为具有 4096 个输入和 4096 个输出的全连接层的算术强度和硬件性能随BS变化的曲线图。[22]
可以看到,对于非常小的批次大小计算将始终受到带宽限制,批次大小 128 及以下的计算量受到带宽限制,通过更多的输入和输出在一定程度上提高了性能。
下图为具有4096个输入、1024个输出时,不同批次大小时的前向传播、激活梯度、权重梯度计算的性能实验数据:[23]
(a)(b)(c) 实验证明在不OOM情况下尽可能增加batch size,可以提高训练速度同时优化显存利用率,同时Batch size配置最好设置为可以提升计算效率。
梯度累积策略
梯度累积(Gradient Accumulation)通过累积多个小批量样本的梯度来减少显存需求,同时保持计算效率。针对显存不足以使用较大 batch size时,可以通过累积实现较大batch size对应效果的效果。整体流程为重复下述循环:
- 针对每个batch的训练数据,完成前向传播和反向传播后,判断是否达到设置的累积次数。
- 如果未达到,则不更新模型参数,但保存梯度不清零。
- 如果达到,梯度清零同时更新模型参数,进行后续循环。
不进行梯度累积的伪代码:
forbatchindataset ptimizer.zero_grad()#梯度清零#===计算代码begin===outputs=model(inputs)#前向传播,计算输出loss=compute_loss(outputs,labels)#计算损失loss.backward()#反向传播,计算梯度#===计算代码end===optimizer.step()#更新模型参数
ptimizer.zero_grad()#梯度清零#===计算代码begin===outputs=model(inputs)#前向传播,计算输出loss=compute_loss(outputs,labels)#计算损失loss.backward()#反向传播,计算梯度#===计算代码end===optimizer.step()#更新模型参数
进行梯度累积的伪代码:
forbatchindataset:ifbatch_index%num_accumulation_steps==0ptimizer.zero_grad()#每num_accumulation_steps步重置一次梯度#===计算代码begin===outputs=model(inputs)#计算输出loss=compute_loss(outputs,labels)#计算损失loss.backward()#反向传播,计算并累积梯度#===计算代码end===if(batch_index+1)%num_accumulation_steps==0ptimizer.step()#每num_accumulation_steps步更新模型参数
梯度保存策略
如果不进行数据并行训练还是会出现OOM时,则可以考虑通过进一步显存优化的方法,例如梯度保存策略(Gradient checkpointing)优化。
梯度保存策略优化可以通过保存激活值来减少显存占用(一定程度增加计算量),为一种时间换空间方法。例如,通过gradient-checkpointing优化可以让将10 倍大的神经网络放入显存中(需额外花费 20% 的计算时间)。可以发现该方法可以有效缓解显存资源问题,合理使用检查点可以平衡显存和计算资源。[24]
其主要思想是在训练过程中,选择性的保存前向传播中得到的激活值,反向传播过程中重新计算未保存的激活值。
对于具有n层的简单馈送神经网络,梯度计算图如下图所示:

默认策略为在峰值时,该算法会存储所有激活值,这意味着深度为 n 的网络需要 O(n) 的内存。在本例中,意味着需要 7 个内存单元。计算反向传播的默认策略如下:

内存节省策略为:可以通过在节点被消耗时忽略它们并在稍后重新计算来节省内存。这种“内存匮乏”的策略需要 O(1) 内存,但需要 O(n²) 计算步骤。如下图所示,此策略需要 4 个内存单位来计算目标。

另外的方法是保留一部分中间结果,这些保存的节点在gradient-checkpoints中的Checkpoint可以自动选择,也可以手动提供。对于上面的例子,中间策略可以是使用下面圈出的节点作为检查点。使用此检查点会产生一种需要 5 个内存单位的策略,并且其运行时间介于内存不足策略和默认策略之间。

因此,通常使用的优化后方法为sqrt(n)步放置checkpoint策略:对于长度为n的链,每sqrt(n)步放置检查点。如果要求对任何节点最多计算两次,这是内存效率最高的策略。内存需求是 ,计算需求是一个额外的向前传递。这是目前在openai的gradient-checkpoints中采取的默认策略。
以下是这三种策略的内存和计算的复杂度:
混合精度训练
混合精度训练 (Mixed precision training)通过部分对精度要求低的参数使用FP16等低精度浮点数进行计算,减少了显存占用并加速了训练过程。例如,DeepSeek系列模型采用了FP8混合精度训练,显著提升了计算效率。
在一些自动混合精度比如torch中实现的方法,会自动将归一化等需要高精度的计算在梯度累计时仍使用FP32,这样可以保持精度避免溢出。 混合精度训练迭代示意图:[@micikeviciusMixedPrecisionTraining2018]

首先会拷贝一份FP32权重副本,然后权重转为FP16进行前向传播并计算loss后,通过FP16进行反向传播计算梯度,最后转换为FP32更新到FP32的权重上。
但需要注意,当小模型和batch且设备性能比较低时,训练速度也会消耗于GPU和GPU之间的IO上以及FP16与FP32的转换,会导致混合精度训练可能会没有效果甚至会更慢。
数据预加载
为了通过数据预加载 (Data preloading) 提高训练速度,需要以GPU能够处理的最大速率提供数据,从而确保GPU的利用率接近100%,可以通过两种DataLoader方法来加速数据供给:[26]
1. 使用锁页内存(pin_memory):此设置允许将数据预先加载到CPU的锁定内存中,锁页内存可以防止数据被交换到磁盘上,减少内存交换的时间(拷贝速度可提升一倍)。
2. 使用更多多线程(num_workers):通过增加线程数来预加,从而提高数据加载效率。

其他优化方法
1. Optimizer :合适的优化器是既可以加快训练速度又可以提高显存利用率的。目前训练Transformer类模型最常用的优化器是Adam或AdamW(带权重衰减的Adam),Adam通过存储先前梯度的滚动平均值可以实现比较好的收敛,但这增加了与模型参数数量成正比的额外显存占用。
2. DeepSpeed Zero:针对训练大型模型时显存不足的问题,Deepspeed主要进行了较多的显存优化。
3. 模型简化:通过减少模型层数、参数数量或使用更简单的网络结构,可以在保持性能的同时降低计算复杂度。
4. 模型剪枝与压缩:模型剪枝和量化技术可以进一步减少模型大小和计算成本,提高推理速度。
5. 算子优化:算子融合、动态重显存计算等优化技术可以提升算力利用率。
6. 分布式训练与并行计算:分布式训练是解决大规模数据集和模型参数规模问题的关键技术。通过多机多卡并行计算,可以显著减少训练时间;深度学习框架如DeepSpeed和Megatron-LM支持算子融合、梯度累积等技术,进一步优化了分布式训练的效率
在训练阶段,合理调整参数对提升模型性能和效果至关重要。以下是关键超参数及其调整策略:
1. Epochs:根据数据规模调整epoch数量,小数据集可适当增加epoch以促进模型收敛。但需注意,过高的epoch可能导致通用能力下降,若仅需提升下游任务性能,可接受一定程度的通用能力损失。
2. Batch Size:较大的Batch Size加速训练但可能收敛于次优解;较小的Batch Size有助于模型泛化但延长训练时间。需在训练速度与模型性能间找到平衡。
3. Global Batch Size:随着计算资源或分布式节点增加,可适当增大Batch Size并调整累积步数。
4. 权重衰减(Weight Decay):通过在损失函数中添加与权重大小成正比的惩罚项来防止过拟合,有助于保持较小权重值,增强模型泛化能力。
5. 梯度裁剪(Gradient Clipping):设置梯度阈值以防止梯度爆炸,确保参数更新稳定。
6. 学习率(Learning Rate):控制参数更新步长,过高导致震荡,过低减慢训练;动态调整学习率是优化训练过程的重要策略,常见的方法包括指数衰减、余弦退火以及自适应学习率调整。
7. Dropout率:正则化方法如dropout(训练时随机丢弃部分神经元)、L1/L2正则化等可以有效防止模型过拟合,提高泛化能力。
基于训练参数调整可实现的优化策略如:
1. 学习率衰减:随着训练进行,逐渐降低学习率,常用方法包括Step Decay、Exponential Decay、Cosine Annealing。
2. 早停法:在验证集上监控模型性能,连续几个epoch性能无提升时停止训练。
3. 数据增强:通过变换训练数据增加多样性,提高模型泛化能力。
4. 梯度裁剪:限制梯度大小,防止梯度爆炸。
5. 混合精度训练:使用FP16进行训练,减少内存消耗并提高训练速度。
6. 超参数优化:超参数的优化通常通过网格搜索、随机搜索或贝叶斯优化等方法实现。
通过以上方法,可以调整和优化大模型的训练过程,提高模型在特定任务上的性能,并确保模型在实际应用中的效果。
通常在不同场景可以使用不同的技术方案组合,例如如下不同场景的技术对比与选型建议示例:
在实际的大模型落地场景时,通常需要在不同场景可以使用不同的技术方案组合,例如,如下不同场景的技术对比与选型建议:
本文主要整理总结了LLM效果和性能优化一些技术和分析,在AI汽车行业性能优化相关实践中,一些典型场景需求和优化场景有:
自动驾驶模型训练场景:生产模型的训练周期可通过训练加速技术进行显著提升;
智能座舱场景:推理延迟从秒级压缩至百毫秒级,可支持多模态实时交互;
联网诊断场景:基于APC和并发优化等,提升并发同时降低硬件成本;
后续将基于 AI 汽车场验证的实战方案,进行更多实际的优化场景案例分享










