|
由于大型语言模型(LLMs)拥有极其庞大的参数数量,为了更新长尾或过时知识而对其进行微调在许多应用中是不切实际的。为了避免微调,可以将LLM视为一个黑盒(即,冻结LLM的参数),并通过检索增强生成(RAG)系统来增强它,这就是所谓的黑盒RAG。最近,黑盒RAG在知识密集型任务中取得了成功,并引起了广泛关注。现有的黑盒RAG方法通常会对检索器进行微调以迎合LLM的偏好,并将所有检索到的文档串联作为输入,这存在两个问题: 这些例子展示了大型语言模型(LLM)偏好的检索到的文档,但这些文档并不包含相关的事实信息。这些例子来自于TriviaQA训练集,并且答案是使用Llama1-13B-Chat生成的。
为了解决这些问题,提出了一个新颖的黑盒RAG框架,它在检索中利用事实信息,并减少了输入的令牌数量,称为FIT-RAG。通过构建一个双标签文档评分器来利用事实信息,该评分器分别将事实信息和LLM的偏好作为标签。此外,它通过引入自我知识识别器和子文档级令牌减少器来减少令牌,这使得FIT-RAG能够避免不必要的增强,并尽可能减少增强令牌。 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);letter-spacing: 0.034em;"/> ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: var(--articleFontsize);letter-spacing: 0.034em;"/>
FIT-RAG包含以下组件: 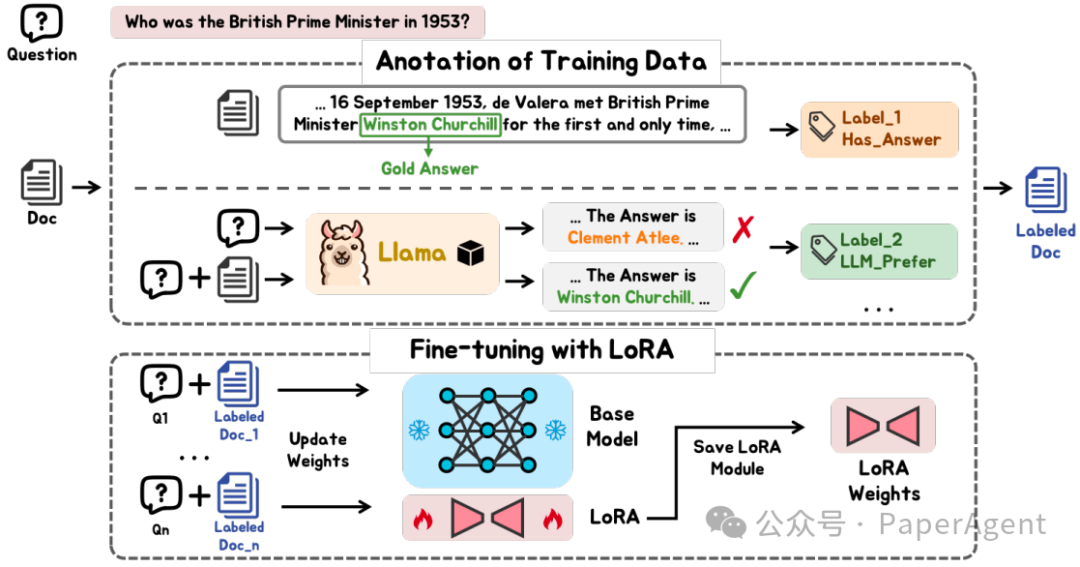
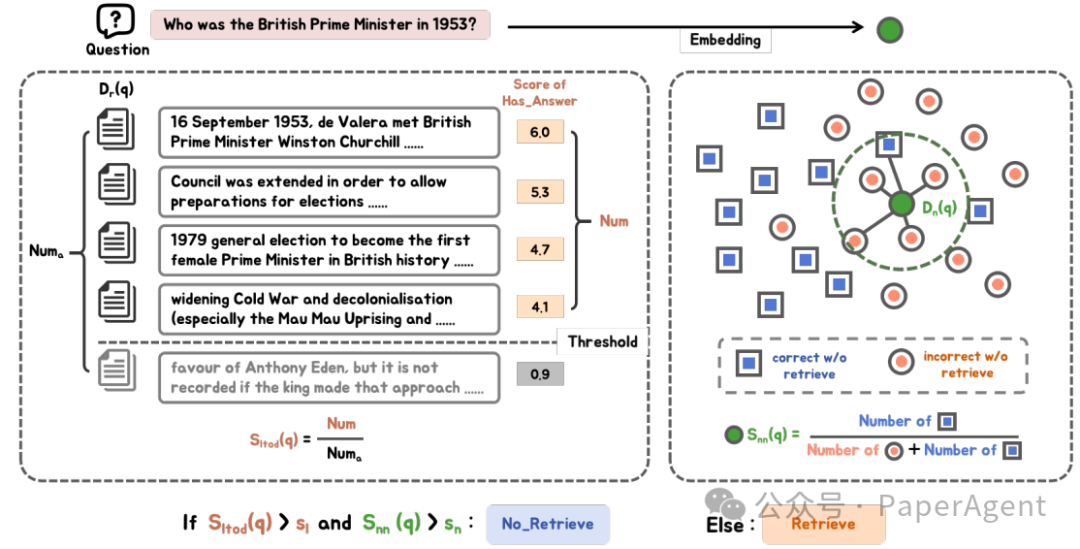
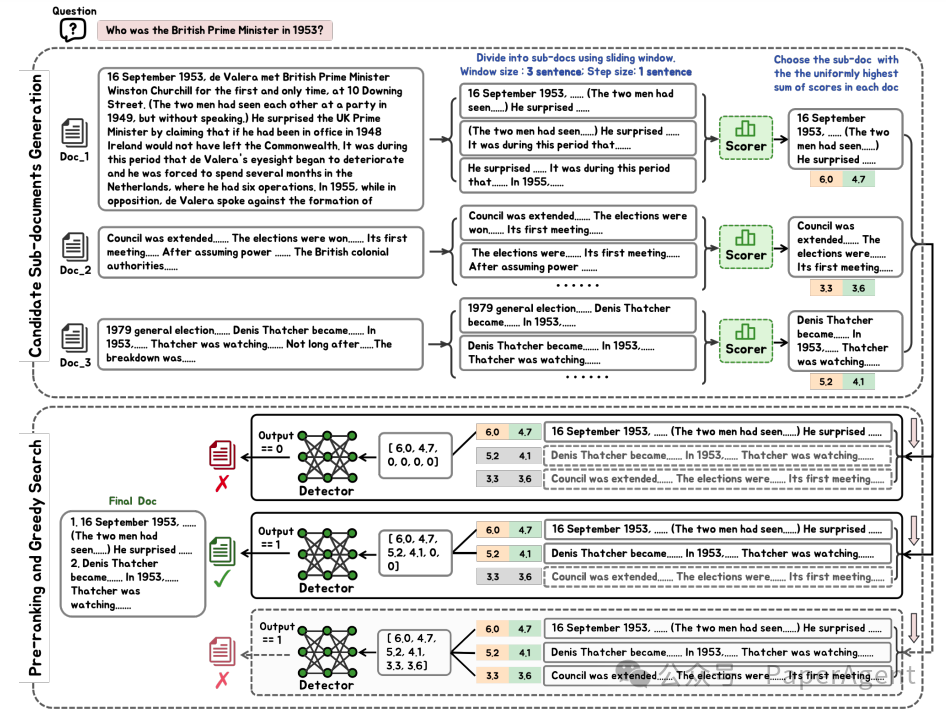

FIT-RAG在三个开放域问答数据集上进行了测试:TriviaQA、NQ和PopQA。实验结果表明,与未经检索增强的Llama2-13B-Chat模型相比,FIT-RAG显著提高了回答问题的准确率,分别在TriviaQA、NQ和PopQA数据集上提高了14.3%、19.9%和27.5%。此外,FIT-RAG在平均令牌消耗上节省了约一半,这表明了其在提高效率方面的显著优势。证明了FIT-RAG其在处理长尾知识和时效性信息方面的有效性,并展示了其在知识密集型任务中的潜力。
在TriviaQA数据集、NQ数据集和PopQA数据集上的答题准确率方面,基线方法与FIT-RAG方法之间的比较。输入令牌表示每个问题的平均输入令牌数量。对于Llama2-13B-Chat和ChatGPT,直接输入问题并指示它们给出答案。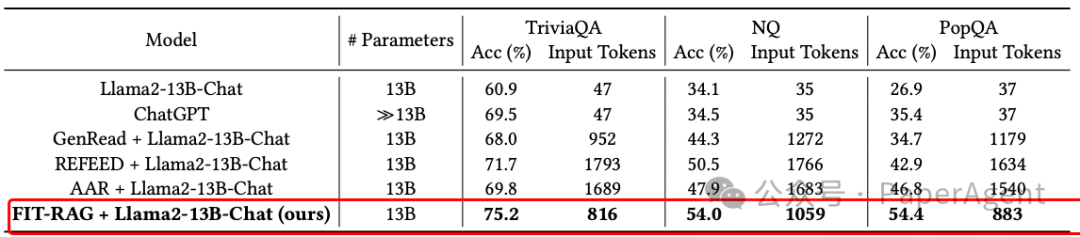
https://arxiv.org/pdf/2403.14374.pdfFIT-RAG:Black-BoxRAGwithFactualInformationandTokenReduction | 









