ingFang SC', -apple-system-font, BlinkMacSystemFont, 'Helvetica Neue', 'Hiragino Sans GB', 'Microsoft YaHei UI', 'Microsoft YaHei', Arial, sans-serif;font-size: 15px;letter-spacing: 0.1em;color: rgb(34, 34, 34);word-break: break-all;">本文是 Anthropic 官方发布的“上下文工程(context engineering)“文章的中文翻译。ingFang SC', -apple-system-font, BlinkMacSystemFont, 'Helvetica Neue', 'Hiragino Sans GB', 'Microsoft YaHei UI', 'Microsoft YaHei', Arial, sans-serif;font-size: 15px;letter-spacing: 0.1em;color: rgb(34, 34, 34);word-break: break-all;">从 提示词工程 拓展到 上下文工程,再说明 上下文工程 如何构建。引言ingFang SC', -apple-system-font, BlinkMacSystemFont, 'Helvetica Neue', 'Hiragino Sans GB', 'Microsoft YaHei UI', 'Microsoft YaHei', Arial, sans-serif;font-size: 15px;letter-spacing: 0.1em;color: rgb(34, 34, 34);word-break: break-all;">提示词工程 聚焦数年后,出现新术语:上下文工程(context engineering)。使用语言模型构建应用,从"为提示词寻找合适的词语",转变为"什么样的上下文配置最可能产生期望的模型行为"。ingFang SC', -apple-system-font, BlinkMacSystemFont, 'Helvetica Neue', 'Hiragino Sans GB', 'Microsoft YaHei UI', 'Microsoft YaHei', Arial, sans-serif;font-size: 15px;letter-spacing: 0.1em;color: rgb(34, 34, 34);word-break: break-all;">上下文(Context):LLM使用时包含的token集合。ingFang SC', -apple-system-font, BlinkMacSystemFont, 'Helvetica Neue', 'Hiragino Sans GB', 'Microsoft YaHei UI', 'Microsoft YaHei', Arial, sans-serif;font-size: 15px;letter-spacing: 0.1em;color: rgb(34, 34, 34);word-break: break-all;">工程(engineering)问题:针对LLM约束优化这些token的使用,下方有说明为何要约束。ingFang SC', -apple-system-font, BlinkMacSystemFont, 'Helvetica Neue', 'Hiragino Sans GB', 'Microsoft YaHei UI', 'Microsoft YaHei', Arial, sans-serif;font-size: 15px;letter-spacing: 0.1em;color: rgb(34, 34, 34);word-break: break-all;">使用LLM需要在上下文中思考:考虑LLM在任何时刻可用的整体状态,及该状态可能产生的行为。ingFang SC', -apple-system-font, BlinkMacSystemFont, 'Helvetica Neue', 'Hiragino Sans GB', 'Microsoft YaHei UI', 'Microsoft YaHei', Arial, sans-serif;font-size: 15px;letter-spacing: 0.1em;color: rgb(34, 34, 34);word-break: break-all;">本文讲上下文工程,提供思维模型,用于构建可控、有效的智能体。
对比:上下文工程 vs. 提示词工程ingFang SC', -apple-system-font, BlinkMacSystemFont, 'Helvetica Neue', 'Hiragino Sans GB', 'Microsoft YaHei UI', 'Microsoft YaHei', Arial, sans-serif;font-size: 15px;letter-spacing: 0.1em;color: rgb(34, 34, 34);word-break: break-all;">Anthropic将上下文工程视为提示词工程的演进。提示词工程ingFang SC', -apple-system-font, BlinkMacSystemFont, 'Helvetica Neue', 'Hiragino Sans GB', 'Microsoft YaHei UI', 'Microsoft YaHei', Arial, sans-serif;font-size: 15px;color: rgb(63, 63, 63);" class="list-paddingleft-1">ingFang SC', -apple-system-font, BlinkMacSystemFont, 'Helvetica Neue', 'Hiragino Sans GB', 'Microsoft YaHei UI', 'Microsoft YaHei', Arial, sans-serif;font-size: 15px;color: rgb(63, 63, 63);">上下文工程- • 定义:在LLM推理期间选择和维护最优token集合的策略
- • 范围:包括提示词之外进入上下文的所有信息(系统指令、工具、MCP、外部数据、消息历史等)
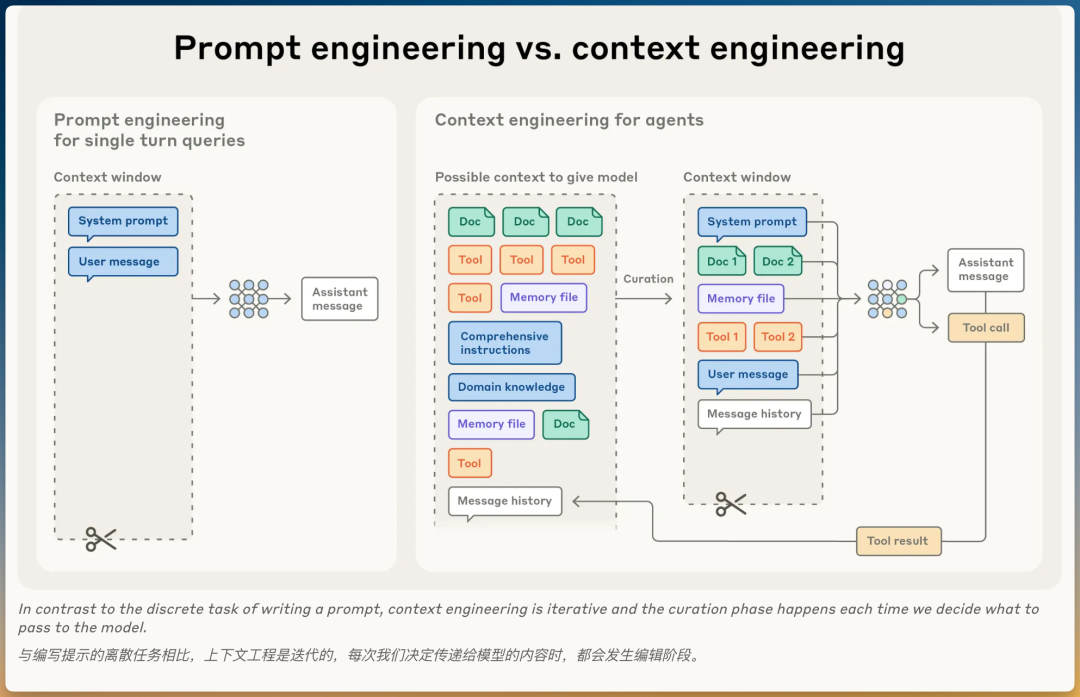
为什么需要演进?智能体在循环运行中生成越来越多可能相关的数据,这些信息必须循环精炼。 上下文工程的核心:从不断演化的可能信息中选择什么进入有限上下文窗口。 关键区别提示词工程:离散任务(写一次提示词) 上下文工程:迭代过程(每次推理都要决定传递什么给模型)
为什么上下文工程对构建智能体重要核心问题:上下文腐化LLM像人类一样,在某个点会失去焦点或困惑。 "大海捞针"式基准测试研究揭示上下文腐化(context rot): 这一特性出现在所有模型中。 根本原因:注意力预算有限上下文是边际收益递减的有限资源。 像人类拥有有限工作记忆容量,LLM解析大量上下文时动用"注意力预算": 架构约束这种注意力稀缺源于LLM架构约束。 LLM基于transformer架构: - • 每个token关注整个上下文中的每个其他token
上下文长度增加 → 模型捕获成对关系的能力被拉伸稀薄 → 上下文大小和注意力焦点间产生张力 训练数据的限制模型训练时: 结果: 类比:就像学生主要练习短跑,偶尔跑一次马拉松,那他马拉松成绩自然不如短跑。 扩大上下文窗口的局限有人可能会想:直接扩大上下文窗口不就行了? 确实有技术可以让模型处理更长的上下文(位置编码插值技术),但有代价: 效果: 具体表现: 类比:就像人的注意力——你可以同时看10个屏幕,但记忆准确度会比看1个屏幕低很多。 结论这些现实意味着上下文工程对构建智能体重要。 即使技术进步允许更长上下文,仍需要精心选择放入什么信息。
上下文的构成受限于有限注意力预算,好的上下文工程意味着找到最小的有效token集合,最大化期望结果的可能性。 下面概述这一原则在上下文不同组成部分中的实际意义。 系统提示词系统提示词应清晰、简单、直接,保持适度的抽象程度。 两种极端,一个平衡点适度的抽象程度意味着在两种失败模式间找平衡: ❌ 极端1:过度硬编码 ❌ 极端2:过于模糊 ✅ 平衡点:适度抽象

组织建议将提示词组织成不同部分: - •
<background_information>背景信息 - •
## Output description输出描述
使用XML标签或Markdown标题划分这些部分。 💡 随着模型变强,提示词格式可能变得不那么重要
最小信息集原则追求完全符合预期行为的最小信息集。 注意: 迭代优化流程- 3.改进:根据初始测试中发现的失败模式添加清晰指令和示例
工具工具允许智能体与环境交互,在工作时引入新的额外上下文。 核心作用工具定义智能体与其信息/行动空间间的契约。 工具促进效率的两个方面: 设计原则类似设计良好的代码库的函数,工具应满足: 1. 自包含 - • ✅ 好例子:
search_file(keyword)- 直接搜索并返回结果 - • ❌ 差例子:
prepare_search()+execute_search()+get_results()- 需要三步配合
2. 鲁棒(对错误友好) - • ✅ 好例子:文件不存在时返回
{"error": "文件未找到", "path": "xxx"}
3. 清晰(一看就懂) - • ✅ 好例子:
get_user_profile(user_id)- 明确获取用户资料 - • ❌ 差例子:
process(id)- 不知道处理什么
4. 功能重叠最小 - • ✅ 好例子:一个
search_user(query_type, value) - • ❌ 差例子:三个工具
search_by_name()、search_by_id()、search_by_email()
输入参数设计: - • 发挥模型优势:让LLM用自然语言理解,而非复杂格式
常见失败模式❌ 臃肿的工具集 关键原则: 如果人类工程师无法明确说明在给定情况下应使用哪个工具,不能期望AI智能体做得更好。
✅ 最小可行工具集 选择最小可行工具集的好处: 示例提供示例(few-shot提示)是众所周知的最佳实践,强烈建议使用。 常见误区❌ 塞满边缘情况 推荐做法✅ 选择典型示例 建议选择一组: 💡对LLM来说,示例是值千言万语的"图片"。
总体指导原则 对上下文不同组成部分(系统提示词、工具、示例、消息历史等): 保持上下文信息丰富但紧凑
上下文检索和智能体搜索智能体的简单定义我们强调了基于LLM的工作流和智能体的区别。 简单定义:智能体 = LLM在循环中自主使用工具 与客户合作,我们看到领域正收敛到这个简单范式: - • 更智能的模型 → 独立导航问题空间并从错误中恢复
即时检索策略背景:从"预检索"到"即时检索"工程师在为智能体设计上下文时的思维转变: 传统方法:预推理时间检索 新趋势:"即时(Just in Time)"上下文策略 工作方式采用"即时"方法构建的智能体: 不会: 而是: - • ✅ 维护轻量级标识符(文件路径、存储查询、网络链接等)
案例:Claude CodeAnthropic的智能体编码解决方案Claude Code使用这种方法对大型数据库执行复杂数据分析: - 3. 利用
head和tail等Bash命令分析大量数据
类比:像人类一样思考这种方法反映人类认知: 人类不会: 人类会: 元数据的价值:不打开文件也能获取信息除了节省存储空间,元数据(文件路径、文件名、时间戳等)本身就能帮助智能体做决策。 什么是元数据?元数据 = 关于数据的数据 类比:就像你看书架上的书: 三种元数据类型1. 文件路径暗示用途 智能体看到文件路径,就能判断文件用途: 示例1: 示例2: 2. 文件名暗示内容 示例: 3. 时间戳暗示相关性 示例: - •
last_modified: 2天前→ 可能是最近修改的,相关性高 - •
last_modified: 2年前→ 可能是旧代码,相关性低
综合使用元数据智能体通过元数据组合判断: 场景:修复最近的bug - 3. 看文件名 → 优先看
bugfix.py而非config.json
效果: 渐进式披露(Progressive Disclosure)让智能体自主导航和检索数据也实现渐进式披露——允许智能体通过探索逐步发现相关上下文。 每次交互都提供线索智能体通过探索获得信息: 逐层组装理解智能体的工作方式:
效果: 权衡与解决方案权衡:速度 vs 精准缺点: 风险:没有适当指导,智能体可能: 解决方案:混合策略某些情况下,最有效的智能体可能采用混合策略: "正确"自主水平的决策边界取决于任务。 案例:Claude Code的混合模型 Claude Code采用混合模型: - •预检索部分:
CLAUDE.md文件被预先放入上下文 - •即时检索部分:
glob和grep等原语允许导航环境并即时检索文件
适用场景 混合策略更适合动态内容较少的上下文,例如:法律或金融工作 未来趋势 随着模型能力提高: 💡"做最简单有效的事情"可能仍将是对在Claude之上构建智能体的团队的最佳建议。
长期任务的上下文工程问题:上下文窗口总会不够长期任务的挑战: - • 例如:大型代码库迁移、综合研究项目(数十分钟到数小时)
为什么不能只等更大的上下文窗口?看似显而易见的策略:等待更大上下文窗口 现实:在可预见的未来,所有大小的上下文窗口都会受影响: 三种解决方案为使智能体在扩展时间范围内有效工作,我们开发了三种技术: - 2.结构化笔记(Structured Note-taking)
- 3.多智能体架构(Multi-Agent Architectures)
方案1:压缩(Compaction)什么是压缩?当对话接近上下文窗口限制时:
核心目标: 案例:Claude Code如何压缩Claude Code的做法:
用户体验:获得连续性,无需担心上下文窗口限制 压缩的艺术:平衡取舍核心挑战:选择保留什么和丢弃什么 风险:过于激进的压缩 → 丢失微妙但关键的上下文 → 后续才发现重要性 优化建议对实施压缩系统的工程师: 步骤1:最大化召回率 步骤2:提高精度 快速见效:清除工具结果低垂果实示例:清除工具调用和结果 最安全的压缩形式:工具结果清除 方案2:结构化笔记(Structured Note-taking)什么是结构化笔记?也叫:智能体记忆 机制: - 1. 智能体定期将笔记写入上下文窗口外的持久化内存
好处以最小开销提供持久记忆 例子: 效果: 案例:Claude玩宝可梦展示:记忆如何在非编码领域转变智能体能力 智能体的记忆能力:
- • “在过去1,234步中,我一直在1号道路训练我的宝可梦”
关键价值:这种跨总结步骤的连贯性实现长期策略,仅靠LLM上下文窗口无法实现。 官方工具:记忆功能作为Sonnet 4.5发布的一部分,Claude开发者平台推出: 记忆工具(公开beta) 允许智能体: 方案3:子智能体架构(Multi-agent Architectures)核心思想不是: 而是: - • ✅ 专门化的子智能体用干净上下文窗口处理聚焦任务
工作方式主智能体: 子智能体: - • 只返回浓缩、精炼摘要(通常1,000-2,000个token)
核心优势清晰的关注点分离: 实际效果这种模式在**《我们如何构建多智能体研究系统》**中讨论过: 在复杂研究任务上显示对单智能体系统的显著改进 如何选择方案?这些方法间的选择取决于任务特征:
核心洞察: 即使模型继续改进,在扩展交互中维持连贯性的挑战仍将是构建更有效智能体的核心。
结论从提示词工程到上下文工程上下文工程代表我们如何使用LLM构建的根本转变。 过去: 现在: 不变的指导原则无论: 指导原则不变: 💡找到最大化期望结果可能性的最小高信号token集合
未来趋势技术演化:我们概述的技术将随模型改进继续演化 模型能力提升: 核心不变:即使能力扩展,将上下文视为有限资源仍将是构建可靠、有效智能体的核心。
|










