|
前不久我写了一篇百度最新的OCR模型(PaddleOCR-VL)的文章反响还不错。评论区大家呼声最高的是希望有一个PaddleOCR-VL的本地本地部署教程我本来以为很难达成的,没想到最后超额完成了,居然超了两倍还多。其中一个是因为这篇文章,受邀作为共学嘉宾参加了百度的PaddleOCR-VL共学直播。还有和Trae在昆明办了第一场线下活动TRAE Friends@昆明没想到能到场54人,也没想到大家氛围超级好,都非常积极,原定活动是5.30结束,结果最后搞到了6.00。这段时间,我其实陆续都有尝试本地部署,但是PaddleOCR-VL刚开源嘛,文档、资料都还不是很完善,所以自己还是踩了不少坑,进行的并不顺利。不过这两天终于跑通啦,然后轻松把本地PaddleOCR-VL接入了Fastgpt,而且没想到识别速度超快,基本上秒出!!最终只占了6G显存~所以就赶紧给大家把这个教程补上,希望对大家有帮助(如果有帮助的话,别忘了三连哦)首先PaddleOCR-VL目前还不支持Mac和AMD的显卡。据官方表示:本地部署paddleOCR-VL的最低配置是RTX3060 12G显存的显卡。但是我体验下来,感觉8G显存也能跑。本期我用的是Windows10的电脑,RTX 5060 TI 16G显存的显卡。第一次把paddleOCR-VL在本地启动之后,占了差不多11G的显存。我习惯用docker部署,因为简单方便,所以这次还是使用docker在本地部署PaddleOCR-VL。 https://www.paddleocr.ai/main/version3.x/pipeline_usage/PaddleOCR-VL.html#311-docker 刚好他们文档里面有对50系显卡的支持 我这次的PaddleOCR-VL本地部署过程还挺曲折的(踩了不少坑):注意:不想看踩坑过程的朋友,可以直接全局搜:"这条指令一键启动",定位到最终的启动指令。
没有docker的朋友需要先自行安装、启动docker 然后win+r,输入cmd 打开Windows的控制台 执行第一个指令: dockerrun-it--rm--gpusall-p8118:8118--networkhostccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlex-genai-vllm-server/bin/bash 如果是第一次执行,会先下载镜像 这个镜像有18G。 如果是之前下载过镜像的,那么就会像下面这样。 直接进入启动的docker容器内部。 不过得检查一下是不是最新版的镜像 pip list | grep paddlex 只要paddlex版本号在3.3.4以上就行。 如果不是就exit(退出容器,回到Windows的控制台)重新拉取一下最新镜像: dockerpullccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlex-genai-vllm-server 再执行最开始的指令,就会重新进入容器内部。 接下来需要安装flash-attn==2.8.3 不过他们之前的教程里面是错误的(现在更正了),因为镜像精简过,里面不包含CUDA编译工具,所以无法本地构建flash-attn。 我就说,之前一直报错,然后我丢给ai,ai给的方案都好复杂,越走越远了。。。 所以,他们给了我一个远程安装预编译的方案。 python-mpipinstallhttps://github.com/mjun0812/flash-attention-prebuild-wheels/releases/download/v0.4.11/flash_attn-2.8.3+cu128torch2.8-cp310-cp310-linux_x86_64.whl 上面这条还是在容器内执行。 终于!!! 成功安装flash-attn==2.8.3 到这里,我感觉离成功只有一步之遥了,马上就要成啦~ 于是我开始执行最后一条指令: paddlex_genai_server--model_namePaddleOCR-VL-0.9B--backendvllm--port8118--host0.0.0.0 结果,不出意外,就要出意外了。 又报错了:out of memory(内存溢出),,丢给Gemini分析,简单来说就是,这个脚本限制使用一半的显存(8G),导致不够用。 然后就换了一个指令(在结尾加了一段参数:--backend_config <(echo -e 'gpu-memory-utilization: 0.8'),把vLLM的显存占用率设置为了80%≈13G): paddlex_genai_server--model_namePaddleOCR-VL-0.9B--backendvllm--port8118--host0.0.0.0--backend_config<(echo-e'gpu-memory-utilization:0.8') 这玩意儿,我真的断断续续折腾了好几天,这下终于部署好了,一下子还有点成就感。后面我最后一次启动忘记加--backend_config <(echo -e 'gpu-memory-utilization: 0.8',不过没报错,成功启动了,最终显存占用是6G多。
当然,也可以使用docker-compose的方式部署:如果是非50系显卡,可以使用下面这个docker-compose.yml的配置services:paddleocr-vl-api:image:ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddleocr-vl:latest-offlinecontainer_name:paddleocr-vl-apiports:-8080:8080depends_on:paddleocr-genai-vllm-server:condition:service_healthydeploy:resources:reservations:devices:-driver:nvidiadevice_ids:["0"]capabilities:[gpu]restart:unless-stoppedhealthcheck:test:["CMD-SHELL","curl-fhttp://localhost:8080/health||exit1"]paddleocr-genai-vllm-server:image:ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddleocr-genai-vllm-server:latest-offlinecontainer_name:paddleocr-genai-vllm-serverdeploy:resources:reservations:devices:-driver:nvidiadevice_ids:["0"]capabilities:[gpu]restart:unless-stoppedhealthcheck:test:["CMD-SHELL","curl-fhttp://localhost:8080/health||exit1"]start_period:300s 50系显卡的docker-compose文件官方暂时还没出dockerrun-d--rm--gpusall-p8118:8118--namepaddleocr-vl-serverccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddleocr-genai-vllm-server:latestsh-c"pipinstallhttps://github.com/mjun0812/flash-attention-prebuild-wheels/releases/download/v0.4.11/flash_attn-2.8.3+cu128torch2.8-cp310-cp310-linux_x86_64.whl&&paddleocrgenai_server--model_namePaddleOCR-VL-0.9B--backendvllm--port8118--host0.0.0.0--backend_config<(echo-e'gpu-memory-utilization:0.8')" 非50系显卡可以使用下面这个指令: dockerrun-d--rm--gpusall-p8118:8118--namepaddleocr-vl-serverccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddleocr-genai-vllm-server:latestsh-c"paddleocrgenai_server--model_namePaddleOCR-VL-0.9B--backendvllm--port8118--host0.0.0.0--backend_config<(echo-e'gpu-memory-utilization:0.8')" 有点烦的就是每次启动,都要去下载那个253.6MB的flash-attn补丁和1.8GB的PaddleOCR-VL -0.9B以及202M的PP-DocLayoutV2模型。会导致Windows里面docker所占用的虚拟空间越来越大。还可以访问它的API文档地址:<服务base URL>/docs也就是http://localhost:8118/docs测试请求是下面这样的,使用OpenAI API的格式,识别的是一个在线的图片的URL地址。{"model":" addleOCR-VL-0.9B","messages":[{"role":"user","content":[{"type":"text","text":"请识别这张图片中的所有文本内容。"},{"type":"image_url","image_url":{"url":"https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png"}}]}],"max_tokens":2048,"temperature":0.0} addleOCR-VL-0.9B","messages":[{"role":"user","content":[{"type":"text","text":"请识别这张图片中的所有文本内容。"},{"type":"image_url","image_url":{"url":"https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png"}}]}],"max_tokens":2048,"temperature":0.0}PS:如果复制这段json用不了的朋友,可以丢给AI输出一遍,因为公众号里面复制出去可能会有格式错误,但是肉眼很难看出来。
说实话,我当时虽然部署成功了,但是我心里是没底的,我害怕这玩意儿调用困难,那也很难用。 结果没想到,它居然支持OpenAI API的格式。 那能做的事情就很多啦!!这不随便接入各种平台嘛。 比如fastgpt、dify、n8n都可以随便接入,非常方便。 我就先来试试接入fastgpt 非常简单,甚至都不需要配置apikey 新增模型->填写模型id:PaddleOCR-VL-0.9B 开启图片识别,填写请求地址: http://<Base_URL>:8118/v1/chat/completions 点击确定保存即可 然后随便创建一个空白应用,添加PaddleOCR-VL-0.9B为模型,推荐把记忆轮数设置为0,否则它每次识别之后,返回的结果会带上一轮的回复,就会比较混乱。 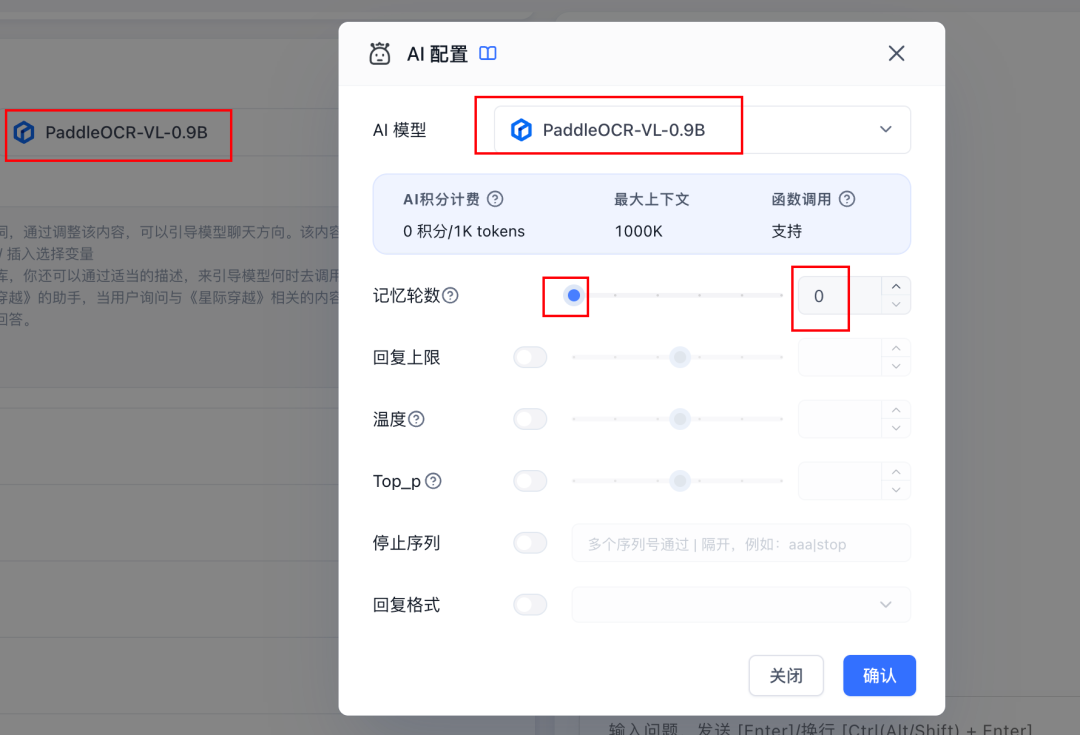 ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]() ![]()
把文件上传->图片上传打开 就可以开始测试啦,速度快到惊人!!基本上是秒出 这个fastgpt在我的Mac电脑上,然后PaddleOCR-VL是部署在我的windows电脑上,Mac这边请求一次,能在Windows的docker里面实时看到请求日志。 也可以把PaddleOCR-VL当作fastgpt知识库的图片理解模型 同时,接入Dify、n8n也非常轻松。不过目前官方貌似还没有出MCP。 对这块感兴趣的朋友可以多多三连呀,我再立一个flag:这篇阅读量如果再超过8000,我出一篇接入n8n的教程,然后再制作一个PaddleOCR-VL的MCP工具,让Claude Code这些本地Agent工具也能更方便的接入PaddleOCR-VL的能力~ | 









