|
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;border-left: none;padding: 1em;border-radius: 8px;color: rgba(0, 0, 0, 0.5);background: rgb(247, 247, 247);margin: 0px 8px 2em;">
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">目前为止,我们已经写了几个爬虫程序,能将网页中的内容提取出来,或者保存成PDF。本文来总结一下这些方法,循序渐进地带大家看下爬虫的实现方法:从单个网页爬虫,到利用大模型提取指定信息,到利用AI Agent实现自动编写爬虫代码实现通用爬虫。
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;border-left: none;padding: 1em;border-radius: 8px;color: rgba(0, 0, 0, 0.5);background: rgb(247, 247, 247);margin: 2em 8px;">说明:本人爬虫小白,所以这篇文章总结的是简单的爬虫程序,可以直接使用的程序。没有复杂的操作,也没有深入的理解。适合爬虫小白或只是将爬虫作为一个数据来源的非专业人员。想要深入理解爬虫原理的同学,可以退出了。 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin: 2em auto 1em;padding-right: 1em;padding-left: 1em;border-bottom: 2px solid rgb(15, 76, 129);color: rgb(63, 63, 63);">0. 单网页的专用爬虫实现方法ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;border-left: none;padding: 1em;border-radius: 8px;color: rgba(0, 0, 0, 0.5);background: rgb(247, 247, 247);margin: 2em 8px;">这种爬虫是针对特定网页的数据爬取,可以是一个网页,或者是一系列结构相似的网页。 ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">这种爬虫的实现方法,最主要的是,需要打开网页,F12调试,然后找自己需要的文本内容在HTML中的Tag或Class。ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 1.2em;font-weight: bold;display: table;margin: 4em auto 2em;padding-right: 0.2em;padding-left: 0.2em;background: rgb(15, 76, 129);color: rgb(255, 255, 255);">0.1 基本的爬虫程序实现方法ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">如果你会一点爬虫基础,那看到网页结构,应该就知道怎么利用 BeautifulSoup 写一个简单的爬虫程序了。但是如果你一点爬虫基础也没有,不知该如何下手呢?可以利用ChatGPT、文心一言、智谱清言等工具帮你。保姆级操作教程可看下面的文章:ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">文章中包含了如何找到你需要的文本内容在HTML结构中的Tag、class,如何给大模型Prompt和交互等:
ingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;margin: 1.5em 8px;letter-spacing: 0.1em;color: rgb(63, 63, 63);">【AI大模型应用开发】【LangChain系列】实战案例2:通过URL加载网页内容 - LangChain对爬虫功能的封装
前面的文章,我们利用LangChain实现了URL网页数据的提取。但是今天想用它抓取微信公众号文章的数据时,失败了。 之前利用 LangChain 实现URL网页数据提取的文章可见:
0.2 利用 selenium 实现爬虫我们在【Python实用技能】建议收藏:自动化实现网页内容转PDF并保存的方法探索(含代码,亲测可用)这篇文章中通过 selenium 实现了自动将网页保存为PDF的功能。其实利用 selenium 也可以直接从网页中提取想要的内容。 下面的示例代码中,通过selenium模拟打开网页,通过 xpath 爬取指定元素。 importos,json,time
fromseleniumimportwebdriver
defcrawel_url(url):
#创建ChromeWebDriver对象
driver=webdriver.Chrome()
print('-'*100)
print(f'now:url:{url}')
driver.get(url)
#添加适当的等待时间或条件,确保页面已完全加载
fromselenium.webdriver.support.uiimportWebDriverWait
fromselenium.webdriver.supportimportexpected_conditionsasEC
#等待10秒钟,直到某个元素可见
wait=WebDriverWait(driver,10)
element=driver.find_element("xpath","/html/body/div[1]/div[2]/div[1]/div/div[1]/div[2]")
content=element.text
print(content)
driver.close()
url_list=[
'https://mp.weixin.qq.com/s/2m8MrsCxf5boiH4Dzpphrg',
]
forurlinurl_list:
crawel_url(url)
time.sleep(5)
xpath的获取方法如下: 
找到你想提取的此网页的数据,在F12调试面板中,在该元素位置鼠标右键 ---> 复制 ---> 复制完整 XPath,替换掉上面程序中的xpath。 运行结果(看起来效果还不错): 
0.3 利用 LangChain 爬取网页内容目前为止,我们接触了两种利用 LangChain 来获取网页内容的方法。 0.3.1 Loading + Transforming第一种方法是使用 LangChain 的 Loading 模块加载HTML网页,利用 Transforming 模块将HTML结构转换为文本。 其 Loading 模块可以使用 AsyncHtmlLoader 或 AsyncChromiumLoader,Transforming模块可以使用 HTML2Text 或 BeautifulSoup。 具体使用方法可看这篇文章的前半部分: 
0.3.2 WebBaseLoader另一种使用 LangChain 获取网页内容的方法是使用其中的 WebBaseLoader 类。我们在【AI大模型应用开发】【LangChain系列】实战案例4:再战RAG问答,提取在线网页数据,并返回生成答案的来源使用过: loader=WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content","post-title","post-header")
)
),
)
docs=loader.load()
这其实是对第一种方法的一种高层封装,将第一种方法中的两个步骤合并在了一起。 小结:单网页的专用爬虫实现方法,目前我们用过的就这几个,可以看到,无论用哪种方法,都躲不过需要我们手动去 F12 调试页面,分析HTML的结构,找到文本内容的Tag或Class。换一个网页,这些Tag或Class可能就不通用了,需要重新分析结构,查找 Tag和Class。
1. 利用大模型直接提取指定信息的探索上面虽然利用了大模型帮我们生成Python代码,但代码不通用,如何利用大模型将这个过程通用化呢?我们也做过探索: 
在这篇文章的后半部分,我们就利用了 LangChain 中的 create_extraction_chain 来尝试创建一个从网页内容中提取特定内容的通用爬虫。 其主要代码如下: schema={
"properties":{
"article_title":{"type":"string"},
"article_content":{"type":"string"},
"article_example_python_code":{"type":"string"},
},
"required":["article_title","article_content","article_example_python_code"],
}
defextract(content:str,schema:dict):
returncreate_extraction_chain(schema=schema,llm=llm).run(content)
最主要的是 schema 的定义,因为这是告诉LLM我们想要什么样的信息。所以,尽可能详细。其实现原理也比较明确,就是内部将 schema 转换成了 OpenAI 的 function calling 的结构,利用 Function Calling 能力来提取信息。 具体的操作步骤和原理解释可以看下上面链接中的文章。 小结:这种方式在获取到网页全部内容后,利用大模型从全部内容中提取出我们需要的信息。不需要知道想要信息的 Tag 和 Class,因此具有一定的通用性。但是效果好坏,完全取决于大模型的能力和我们自己定义的schema内容。目前来看,有点用,但想真正能用,还是非常难的。
2. 利用AI Agent实现通用爬虫2.1 实现思路实现真正能够通用的爬虫,我们将目光放到 AI Agent 上。正好,前段时间学习 MetaGPT,里面的教程中就有通用爬虫的实现,咱们借鉴一下。 具体的MetaGPT实现通用爬虫的详细步骤可以看这篇文章第3部分:【AI Agent系列】【MetaGPT】10. 一句话订阅专属信息 - 订阅智能体进阶,实现一个更通用的订阅智能体(2) 
它的 实现思路是先让大模型理解用户想要的数据内容,然后根据这些数据内容让大模型写爬虫代码,然后自动执行爬虫代码,获取相关文本内容。 2.2 自动化爬虫代码生成器我将这个过程单独抽离了出来,自动写爬虫代码的完整代码如下: importasyncio
frommetagpt.tools.web_browser_engineimportWebBrowserEngine
frommetagpt.utils.commonimportCodeParser
frommetagpt.utils.parse_htmlimport_get_soup
fromopenai_testimportopenai_test
defget_outline(page):
soup=_get_soup(page.html)
outline=[]
defprocess_element(element,depth):
name=element.name
ifnotname:
return
ifnamein["script","style"]:
return
element_info={"name":element.name,"depth":depth}
ifnamein["svg"]:
element_info["text"]=None
outline.append(element_info)
return
element_info["text"]=element.string
#Checkiftheelementhasan"id"attribute
if"id"inelement.attrs:
element_info["id"]=element["id"]
if"class"inelement.attrs:
element_info["class"]=element["class"]
outline.append(element_info)
forchildinelement.children:
process_element(child,depth+1)
forelementinsoup.body.children:
process_element(element,1)
returnoutline
asyncdeftest(url,query):
page=awaitWebBrowserEngine().run(url)
outline=get_outline(page)
outline="\n".join(
f"{''*i['depth']}{'.'.join([i['name'],*i.get('class',[])])}:{i['text']ifi['text']else''}"
foriinoutline
)
#print(outline)
PROMPT_TEMPLATE="""PleasecompletethewebpagecrawlerparsefunctiontoachievetheUserRequirement.Theparse\
functionshouldtakeaBeautifulSoupobjectasinput,whichcorrespondstotheHTMLoutlineprovidedintheContext.
```python
frombs4importBeautifulSoup
#onlycompletetheparsefunction
defparse(soup:BeautifulSoup):
...
#Returntheobjectthattheuserwantstoretrieve,don'tuseprint
```
##UserRequirement
{requirement}
##Context
Theoutlineofhtmlpagetoscrabeisshowlikebelow:
```tree
{outline}
```
"""
code_rsp=openai_test.get_chat_completion(PROMPT_TEMPLATE.format(outline=outline,requirement=query))
code=CodeParser.parse_code(block="",text=code_rsp)
print(code)
asyncio.run(test("https://mp.weixin.qq.com/s/2m8MrsCxf5boiH4Dzpphrg","获取标题,正文中的所有问题,正文中的代码"))
其步骤可总结如下: (1)通过WebBrowserEngine获得URL的HTML结构:page = await WebBrowserEngine().run(url) (2)通过get_outline获取出该HTML网页的主体结构,这是为了消除原HTML中的无用数据,同时减少Token消耗:outline = get_outline(page) (3)将outline和用户的需求数据组成Prompt,给大模型,让大模型写代码:code_rsp = openai_test.get_chat_completion(PROMPT_TEMPLATE.format(outline=outline, requirement=query)) 其最终运行结果如下(最终输出的是针对此url和用户需求的爬虫代码): defparse(soup:BeautifulSoup):
title=soup.find('h1',class_='rich_media_title').text
questions=[]
codes=[]
sections=soup.find_all('section')
forsectioninsections:
blocks=section.find_all(['p','h2','h3','pre','ul','blockquote'])
forblockinblocks:
text=block.get_text(strip=True)
iftext:
ifblock.name=='p'orblock.name=='h2'orblock.name=='h3':
iftextnotin['公众号内文章一览','原创','同学小张','2024-03-1308:00','北京']:
questions.append(text)
ifblock.name=='pre'orblock.name=='ul'orblock.name=='blockquote':
codes.append(text)
return{
'title':title,
'questions':questions,
'codes':codes
}
运行该爬虫代码看下大模型写的代码的效果,测试程序如下: importasyncio
frommetagpt.tools.web_browser_engineimportWebBrowserEngine
frombs4importBeautifulSoup
defparse(soup:BeautifulSoup):
title=soup.find('h1',class_='rich_media_title').text
questions=[]
codes=[]
sections=soup.find_all('section')
forsectioninsections:
blocks=section.find_all(['p','h2','h3','pre','ul','blockquote'])
forblockinblocks:
text=block.get_text(strip=True)
iftext:
ifblock.name=='p'orblock.name=='h2'orblock.name=='h3':
iftextnotin['公众号内文章一览','原创','同学小张','2024-03-1308:00','北京']:
questions.append(text)
ifblock.name=='pre'orblock.name=='ul'orblock.name=='blockquote':
codes.append(text)
return{
'title':title,
'questions':questions,
'codes':codes
}
asyncdeftest(url):
page=awaitWebBrowserEngine().run(url)
result=parse(page.soup)
print(result)
asyncio.run(test("https://mp.weixin.qq.com/s/2m8MrsCxf5boiH4Dzpphrg"))
运行结果: 
该爬虫程序将网页内容提取成了用户需求的那三个字段:题目、正文问题(文字)、正文代码,效果还是很不错的。 当然,我们上面是手动将爬虫代码粘贴出来测试的,在AI Agent中,直接再加一个Agent,让其专门自动运行此代码,就完成了通用爬虫的过程(这也是上文链接文章中的做法):用户全程只需输入一个Url和想要的数据,然后就能拿到想要的内容了,而且效果比上面第1节中利用大模型直接提取指定信息的方法要好得多。 2.3 可能遇到的问题虽然我们上面通过 get_outline 对HTML内容进行了精简,但还是存在超过大模型 Token 数限制的情况,这种情况就无法生成爬虫代码,而是报下面的错误: 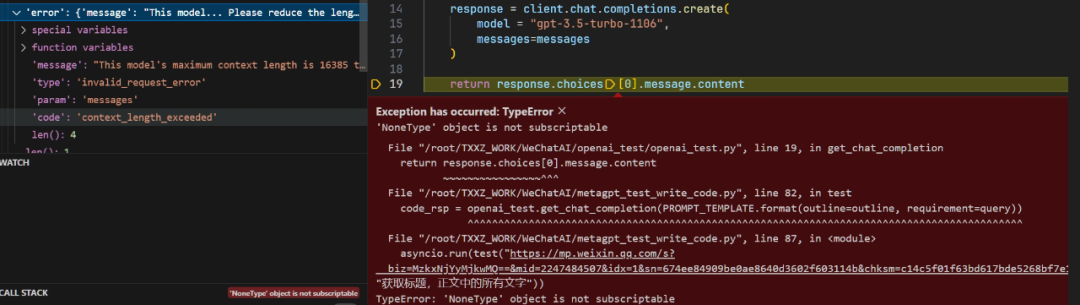
解决这种情况的方法也简单,限制下最终 Prompt 的 Token 数就好了(简单粗暴),这些 Token 已经足以表达 HTML 的结构了。 if(len(prompt)>16000):
prompt=prompt[0:16000]
3. 总结本文我们盘点了目前为止我使用过的所有爬虫代码,分析了它们的实现方法。从专用爬虫,到大模型直接提取指定信息的通用爬虫探索,再到最终的利用 AI Agent 实现通用爬虫,逐步递进,总能让你收获点东西。 本文中的代码和关联文章中的代码都是我亲测可用的,可以直接拿去用。 题外话:在运行过程中,LangChain 和 MetaGPT 中的相关封装类,底层有使用 Playwright 来进行网页数据获取,所以,你可能需要安装下 Playwright 环境。我在这上面踩了不少坑,如果你需要,可以看这篇文章避下坑:【云服务环境】含泪总结:我在云服务安装Python爬虫环境Playwright的踩坑实录
|










