|
许多公司一直在推广他们模型处理长上下文的能力。对于那些不在这些公司内部的人来说,100万个标记的上下文仍然显得有些神奇,或者需要巨大的计算资源。EasyContext旨在揭开长上下文扩展的神秘面纱,并展示它实际上是相当直接的。 EasyContext展示了如何结合现有技术来训练具有以下上下文长度的语言模型:模型可以进行完整的微调、全注意力和全序列长度的训练。训练脚本(train.py)代码行数不到200行。- Flash attention and its fused cross entropy kernel
- Dist flash attention(之前称为LightSeq)
然后,通过逐渐将Llama-2-7B的rope base频率增加到1B,在8个A100上进行训练。值得注意的是,模型仅使用512K的序列长度进行训练,同时能够泛化到近100万的上下文。from easy_context import prepare_seq_parallel_inputs, apply_seq_parallel_monkey_patch, prepare_dataloaderfrom transformers import LlamaForCausalLM# Swap attention implementation from flash attn to either dist_ring_attn or zigzag_ring_attnapply_seq_parallel_monkey_patch("dist_flash_attn", "llama")# Make sure you toggle on flash_attention_2model = LlamaForCausalLM.from_pretrained(model_name, _attn_implementation="flash_attention_2")accelerator = ...train_dataloader = ...prepare_dataloader("dist_flash_attn", train_dataloader, accelerator)
# In your training loop...for step, batch in enumerate(train_dataloader):# Shard the sequencesprepared = prepare_seq_parallel_inputs("dist_flash_attn", batch["input_ids"], batch["position_ids"], batch["target_ids"], accelerator.process_index, accelerator.num_processes, accelerator.device)local_input_ids = prepared["local_input_ids"]local_position_ids = prepared["local_position_ids"]local_target_ids = prepared["local_target_ids"]# Then do model forward as usuallogits = model(local_input_ids,position_ids=local_position_ids,).logits
大海捞针效果 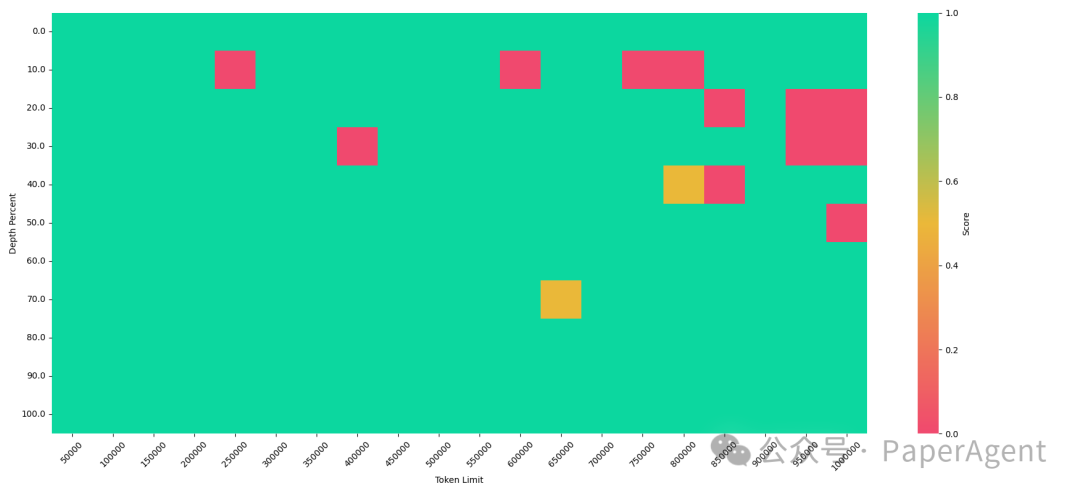
Perplexity:在proofpile测试集中对长度为50万到60万的2份文档进行了测试EasyContext作者的一些思考:到目前为止,处理视频生成模型中的长序列一直被认为是一个巨大的挑战。相信8个A100能够在训练期间为7B模型提供70万的上下文长度,这不仅对语言模型来说很酷;对于视频生成来说也是巨大的进步。70万的上下文长度意味着现在可以对1500帧进行微调/生成,假设每一帧包含512个标记。这意味着如果Meta或其它公司有一天开源了,至少可以对其进行微调。此外,encoder-only transformer的好处在于不需要存储KV缓存,这节省了大量的内存。 | 









