|
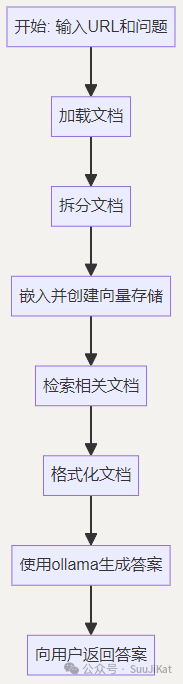
近期Ollama官方发布了其python的工具库,本文以此介绍将Ollama集成到Python中的指南,展示开发人员也可以轻松利用的AI功能。 上篇文章介绍了如何落地部署Ollama的大模型,这期将在此基础上进行本地模型的拓展应用——制作网页问答机器人
把大模型装进笔记本里:Ollama+Open Web UI 设计思路:
1 首先我们创建一个新的python环境,并安装ollama的python库 condacreate-nollamapython=3.11condaactivateollamapip3installollama 
接着我们把相关的依赖包安装进去,比如langchain(提示词工程)、beautifulsoup4(爬取html)、chromadb(处理词嵌入)、gradio(图形化界面),然后创建python文件。
pip3 install langchain beautifulsoup4 chromadb gradio
#创建python文件New-Item QAmachine.py
2 在文件中,首先导入依赖包,并创建网页内容接收器、拆分器和嵌入存储器,用于加载、拆分和后续检索文档。这里多数用的langchain的接口,这在大模型应用中很好用。这里注意的是本文用的LLM是OpenAI的“Mistral”,适用于文字处理。
import gradio as grimport bs4from langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_community.vectorstores import Chromafrom langchain_community.embeddings import OllamaEmbeddingsimport ollama
# 函数用于加载、拆分和检索文档def load_and_retrieve_docs(url):# 使用给定的URL初始化文档加载器loader = WebBaseLoader(web_paths=(url,),bs_kwargs=dict()# 空字典用于BeautifulSoup的初始化参数)# 加载文档docs = loader.load()# 初始化文档拆分器,设定拆分大小和重叠大小text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)# 拆分文档splits = text_splitter.split_documents(docs)# 初始化嵌入模型embeddings = OllamaEmbeddings(model="mistral")# 从文档拆分和嵌入中创建向量存储vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)# 将向量存储转换为检索器并返回return vectorstore.as_retriever()
3 合并文档内容,并定义检索器对文本内容进行回答检索,从而实现RAG
# 函数用于格式化文档def format_docs(docs):# 将文档内容合并成一个字符串并返回return "\n\n".join(doc.page_content for doc in docs)
# 定义RAG链执行函数def rag_chain(url, question):# 加载和检索与URL相关的文档retriever = load_and_retrieve_docs(url)# 使用检索器根据问题检索文档retrieved_docs = retriever.invoke(question)# 格式化检索到的文档formatted_context = format_docs(retrieved_docs)# 构造ollama模型的输入提示formatted_prompt = f"Question: {question}\n\nContext: {formatted_context}"# 使用ollama模型生成答案response = ollama.chat(model='mistral', messages=[{'role': 'user', 'content': formatted_prompt}])return response['message']['content']
4 最后通过gradio创建网页UI并写下启动命令。
# 创建Gradio界面iface = gr.Interface(fn=rag_chain,inputs=["text", "text"],outputs="text",title="RAG链网页内容问答",description="输入URL并从RAG链中获取答案。")
# 启动命令iface.launch()
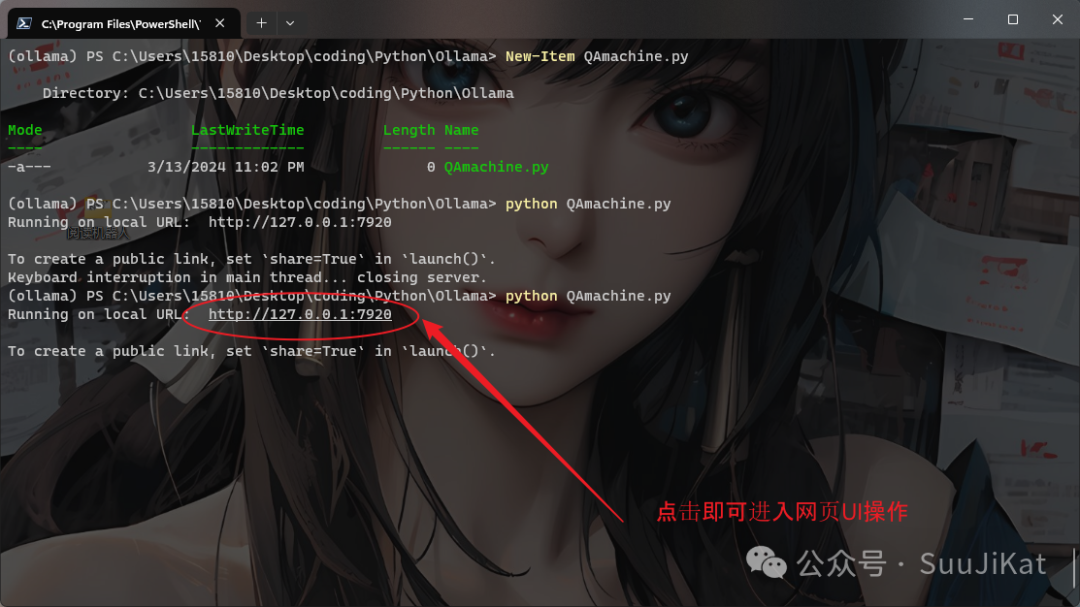
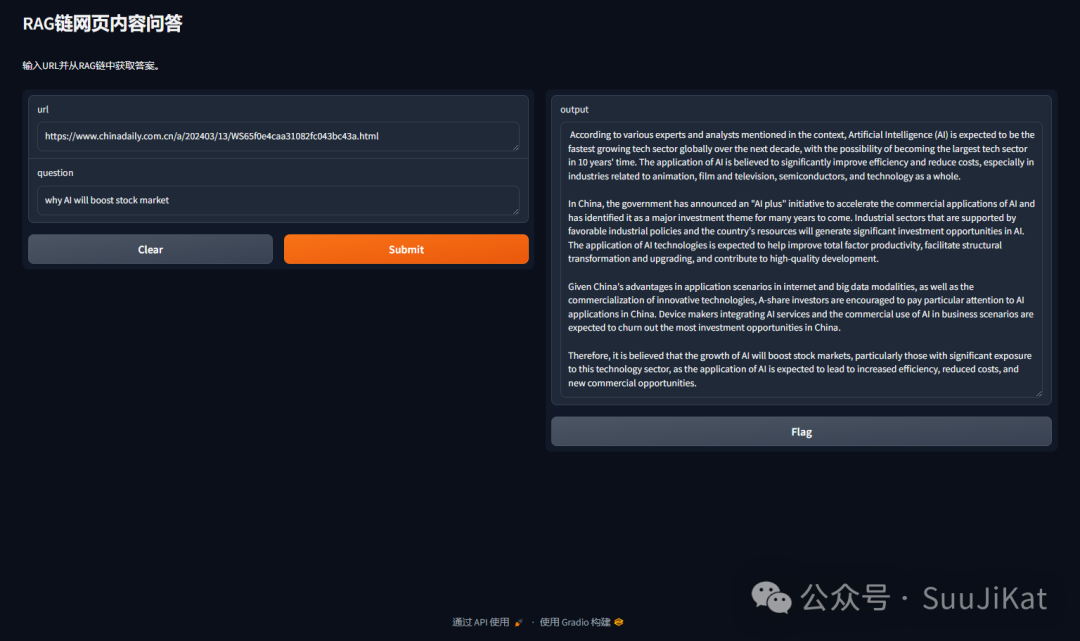
代码保存后在命令行中输入python+ QAmachine.py即可运行代码,点击端口链接进入网页端的问答机器人界面~
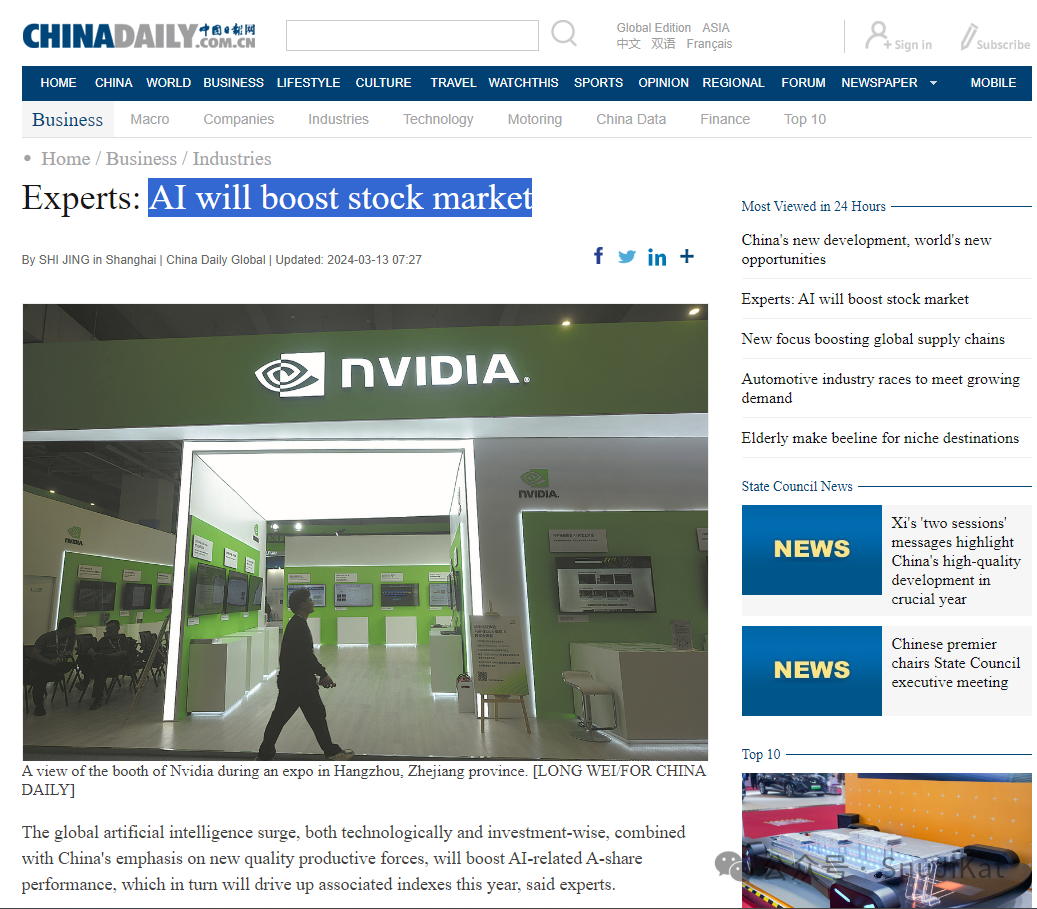
这里我用“china daily”的一篇新闻报道进行测试,内容准确度十分高,这很RAG,更多本地LLM的玩法使用之后会一一拓展,Bye~
| 









